출처: 코리 웨이드.(2022). XGBoost와 사이킷런을 활용한 그레이디언트 부스팅. 서울:한빛미디어
XGBoost in Kaggle
- 테이블 형태의 데이터(행과 열로 구성)에서 우수한 성능을 보임
- LightGBM (MS 개발)과 경쟁 구도
- 개별 모델의 예측이 중요하지만,
더 높은 성능 달성을 위해서는 새로운 특성을 만들고 최적의 모델을 결합하는 것도 중요함
홀드아웃 세트
- 머신러닝 모델을 만드는 목적 → 일반화 성능을 높이는 것 (=본 적 없는 데이터에서 정확한 예측을 만드는 것)
- 홀드아웃 세트 (test data): 모델의 최종 성능을 평가하는데 사용
- 학습에 사용하면 안됨! → 검증 세트에 모델이 overfitting되어 일반화 성능이 떨어질 수 있음
- 일반적인 ML 모델 검증 및 테스트 방법
-
데이터를 Train, Test(홀드아웃) 세트로 분할
-
Train 세트를 다시 Train, Validation 세트로 분할하거나 교차 검증을 사용
-
최종 모델을 만든 후, Test 세트로 모델 평가
- 모델 평가 점수가 안좋으면 2번으로 돌아가서 반복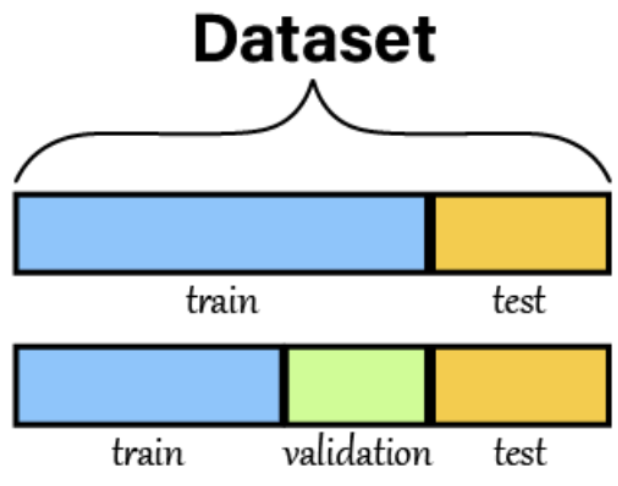
-
Feature Engineering (특성 공학)
- 머신러닝 모델을 위한 데이터 테이블의 컬럼을 생성하거나 선택하는 작업
- 모델 성능에 영향을 많이 미치기 때문에 머신러닝 응용에 있어서 굉장히 중요한 단계
- 전문성과 시간이 많이 드는 작업
Timestamp Data
- 유닉스시간: 1970년 1월 1일부터 시간을 밀리 초로 나타냄
- timestamp 객체로 변환
pd.to_datetime(unit='ns')단위(unit) default값 ‘ns’(나노초)
df['ns_date'] = pd.to_datetime(df['time_stamp'])
df['ms_date'] = pd.to_datetime(df['time_stamp'], unit='ms')
df[['time_stamp', 'ns_date', 'ms_date']].head(3)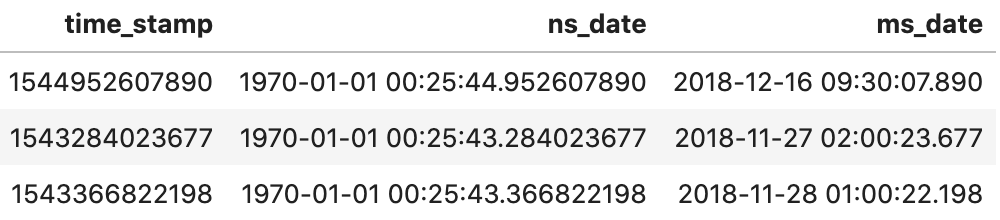
- 월, 시간, 요일 추출
df['month'] = df['date'].dt.month
df['hour'] = df['date'].dt.hour
df['dayofweek'] = df['date'].dt.dayofweek # 0: Monday, 6: Sunday- 주말 여부 확인 (요일 데이터 사용)
def weekend(row):
if row['dayofweek'] in [5,6]:
return 1
else:
return 0
df['weekend'] = df.apply(weekend, axis=1)- 러시아워 여부 확인 (시간 데이터 사용)
-
rush hour: 오전 6~10, 오후 3~7시
def rush_hour(row): if (row['hour'] in [6,7,8,9,15,16,17,18]) & (row['weekend'] == 0): return 1 else: return 0 df['rush_hour'] = df.apply(rush_hour, axis=1)
-
Categorical Data
pd.get_dummies()로 범주형column을 수치형 column으로 변환 가능- 범주가 나타난 빈도로 변환해서 사용할 수도 있음
-
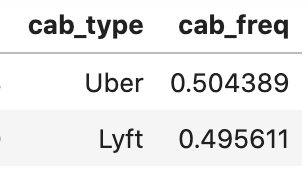
‘cab_type’변수의 빈도를 백분율로 변환df['cab_freq'] = df.groupby('cab_type')['cab_type'].transform(lambda x: x.count() / len(df))
-
평균 인코딩
- target encoding이라고도 불림
- 놀라운 성능을 낸다고 입증됨
- 범주형 특성을 타깃 값의 평균을 기반으로 수치 특성으로 변환
- ex. Blue 중 8개가 O, 2개가 X → 평균 인코딩 특성은 8/10 = 0.2
- 타깃 값 사용으로 data leakage가 있음 → 추가적인 규제 필요
- data leakage
- train과 test or 특성과 타깃 사이에 정보가 공유될 때 발생
- 타깃이 특성 데이터에 직접적인 영향을 미치기 때문에 위험 (overfitting 가능성)
- 규제 방법
- Smoothing
- K-Fold Regularisation: label 값에 따른 인코딩 값을 fold 수만큼 더 다양하게 만들어 규제
- Expanding Mean Regularisation: 위 K-Fold 규제 방법보다 label 당 인코딩 되는 값을 더욱 많이 만드는 방법
- data leakage
from category_encoders.target_encoder import TargetEncoder
encoder = TargetEncoder()
df['cab_type_mean'] = encoder.fit_transform(df['cab_type'], df['price'])
# df.groupby('cab_type')['price'].mean() # 값 확인 용도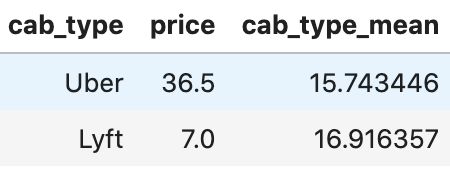
TargetEncoder 클래스 없이도 변환할 수 있음
df['cab_type_mean2'] = df.groupby('cab_type')['price'].transform('mean')
# len(df) == sum(df['cab_type_mean'] == df['cab_type_mean2']) # True상관관계가 낮은 앙상블 만들기
- 앙상블 학습(Ensemble Learning)이란?
- 여러 개의 분류기를 생성하고, 그 예측을 결합하여 보다 정확한 예측을 도출하는 기법
- 상관관계: 두 변수 사이의 선형 관계의 강도를 나타내는 통계값 (-1 ≤ corr ≤ 1)
- 상관 관계가 낮은 모델을 선택하는 이유
- 모델이 동일한 예측을 하면, 새로운 정보를 제공받지 못함 (다수결 방식에서 불리)
- 다른 예측을 만드는 다양한 모델을 가지는 것이 강력한 모델을 만들 수 있음
- 모델 및 예측 결과준비
from xgboost import XGBClassifier from sklearn.ensemble import RandomForestClassifier from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score def y_pred(model): model.fit(X_train, y_train) y_pred = model.predict(X_test) score = accuracy_score(y_pred, y_test) return y_pred X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=2) y_pred_gbtree = y_pred(XGBClassifier()) y_pred_dart = y_pred(XGBClassifier(booster='dart', one_drop=True)) y_pred_forest = y_pred(RandomForestClassifier(random_state=2)) y_pred_logistic = y_pred(LogisticRegression(max_iter=10000)) y_pred_xgb = y_pred(XGBClassifier(max_depth=2, n_estimators=500, learning_rate=0.1)) - 모델 상관관계 결과
df_pred = pd.DataFrame(data= np.c_[y_pred_gbtree, y_pred_dart, y_pred_forest, y_pred_logistic, y_pred_xgb], columns=['gbtree', 'dart', 'forest', 'logistic', 'xgb']) df_pred.corr()
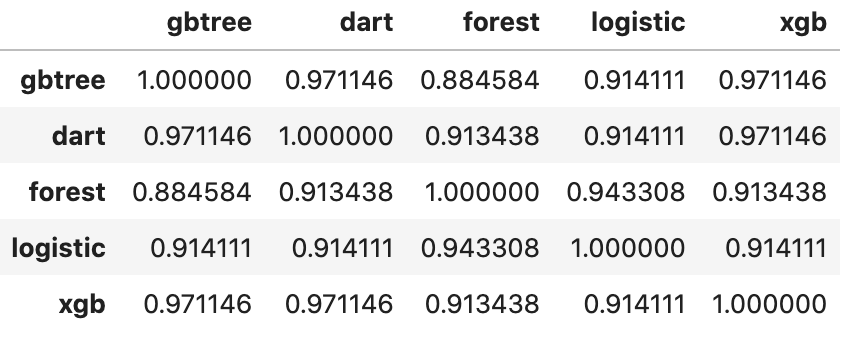
- 모델 선택
- 가장 예측률이 좋은 모델 기준으로 선택 (xgb)
- 상관관계가 낮은 모델 선택 (forest, logistic)
- 상관관계가 낮은 것에 대한 명확한 기준은 없음
- 하드 보팅 적용 (다수결 방식)
from sklearn.ensemble import VotingClassifier from xgboost import XGBClassifier from sklearn.ensemble import RandomForestClassifier from sklearn.linear_model import LogisticRegression from sklearn.model_selection import cross_val_score estimators = [] logistic_model = LogisticRegression(max_iter=10000) estimators.append(('logistic', logistic_model)) xgb_model = XGBClassifier(max_depth=2, n_estimators=500, learning_rate=0.1) estimators.append(('xgb', xgb_model)) rf_model = RandomForestClassifier(random_state=2) estimators.append(('rf', rf_model)) ensemble = VotingClassifier(estimators) scores = cross_val_score(ensemble, X, y, cv=kfold) print('Voting 결과: %.3f' % scores.mean()) print('Xgb(최고 모델) 결과: %.3f' % accuracy_score(y_pred_xgb, y_test)) # Voting 결과: 0.977 # Xgb(최고 모델) 결과: 0.965
스태킹
- 개별적인 여러 알고리즘을 서로 결합해 예측 결과를 도출
- 배깅, 부스팅과의 차이점은 개별 알고리즘으로 예측한 데이터를 기반으로 다시 예측을 수행하는 것
- 두 종류 모델이 필요
- 기본 모델(아래 파랑, 보라, 빨강)
- 메타 모델(아래 초록)
- 기본 모델의 예측 결과를 학습 데이터로 만들어서 학습하고 예측
- 예측을 입력으로 받기 때문에,
선형 회귀(회귀), 로지스틱 회귀(분류) 같이 간단한 모델을 사용하는 것이 권장됨


from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import StratifiedKFold, cross_val_score
from sklearn.ensemble import RandomForestClassifier, StackingClassifier
from xgboost import XGBClassifier
from sklearn.linear_model import LogisticRegression
# 데이터 준비
X, y = load_breast_cancer(return_X_y=True)
kfold = StratifiedKFold(n_splits=5)
# 기본 모델
base_models = []
base_models.append(('lr', LogisticRegression()))
base_models.append(('xgb', XGBClassifier()))
base_models.append(('rf', RandomForestClassifier(random_state=2)))
# 메타 모델
meta_model = LogisticRegression()
# 스태킹 앙상블
clf = StackingClassifier(estimators=base_models, final_estimator=meta_model)
scores = cross_val_score(clf, X, y, cv=kfold)
print('Stacking 결과: %.3f' % scores.mean()) # Stacking 결과: 0.981Reference
- https://mrlazydev.tistory.com/entry/Feature-Engineering%ED%8A%B9%EC%84%B1-%EA%B3%B5%ED%95%99%EC%9D%B4%EB%9E%80
- http://www.dinnopartners.com/__trashed-4/
- https://casa-de-feel.tistory.com/9
- https://towardsdatascience.com/stacking-classifiers-for-higher-predictive-performance-566f963e4840
- https://velog.io/@gjtang/%ED%8C%8C%EC%9D%B4%EC%8D%AC-%EB%A8%B8%EC%8B%A0%EB%9F%AC%EB%8B%9D-%EC%99%84%EB%B2%BD-%EA%B0%80%EC%9D%B4%EB%93%9C-Section4
- https://casa-de-feel.tistory.com/22

Data Scientist, Data Analyst