
오차함수 미분법
우린 앞서 최적화 된 직선을 찾는 법과 오차함수 등을 배웠다. 그렇다면 이번에는 오차함수를 미분해 가장 최선의 직선을 찾는 과정을 보자.
오차는 우리가 모델에 데이터를 넣었을 때, 실제 값과 예측값의 차이라는 것을 알고 있다. 이는 이 모델이 얼마나 좋은 모델인지 알려주는 척도가 되기도 하며, 컴퓨터가 가장 최적의 상관관계를 찾아나가는데 큰 도움을 준다.
우선 앞에 했던 내용을 복습해보자.
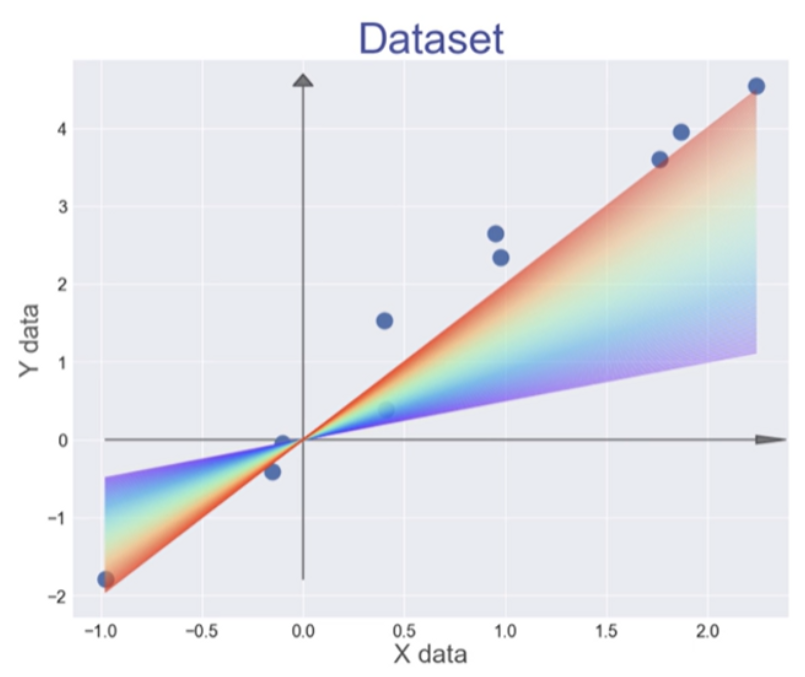
우리는 빨간선을 찾을 때까지 학습을 반복하면 된다. (주의 - 초기값은 0이 되면 안됨!)

아주 보편적인 오차함수(Mean Squared Error)이다. 여기서 예측값인 t를 일차식으로 바꿔준다면,
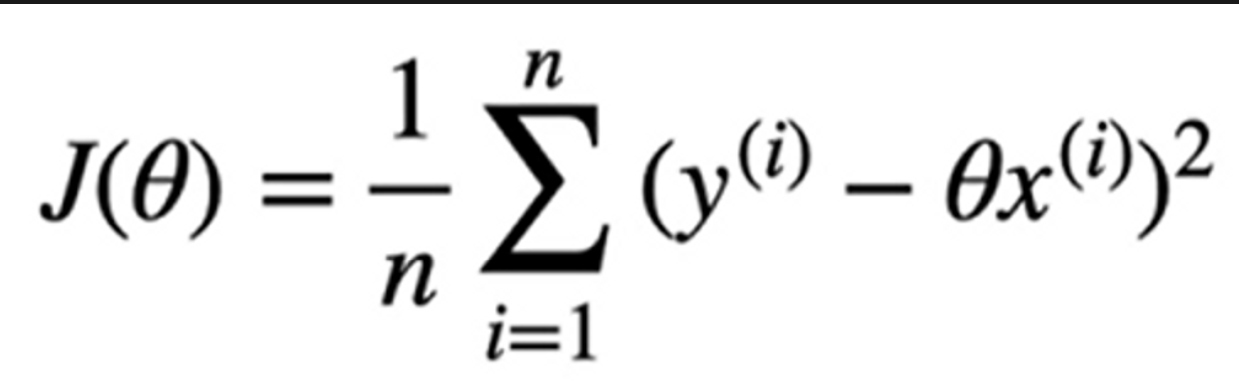
여기서 세타 말고는 전부 상수 취급을 하기 때문에 세타에 대한 함수라고 할 수 있으며, 아래는 전개 형태이다.
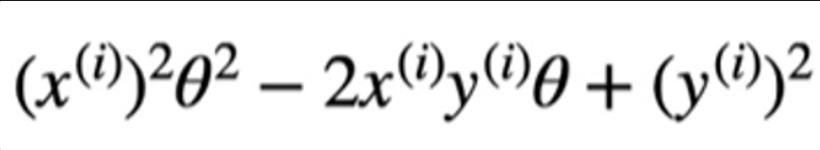
이는 아주 간단한 형태이며, 만일 bias까지 추가 된다는 가정하에 식이 이렇게 변한다.
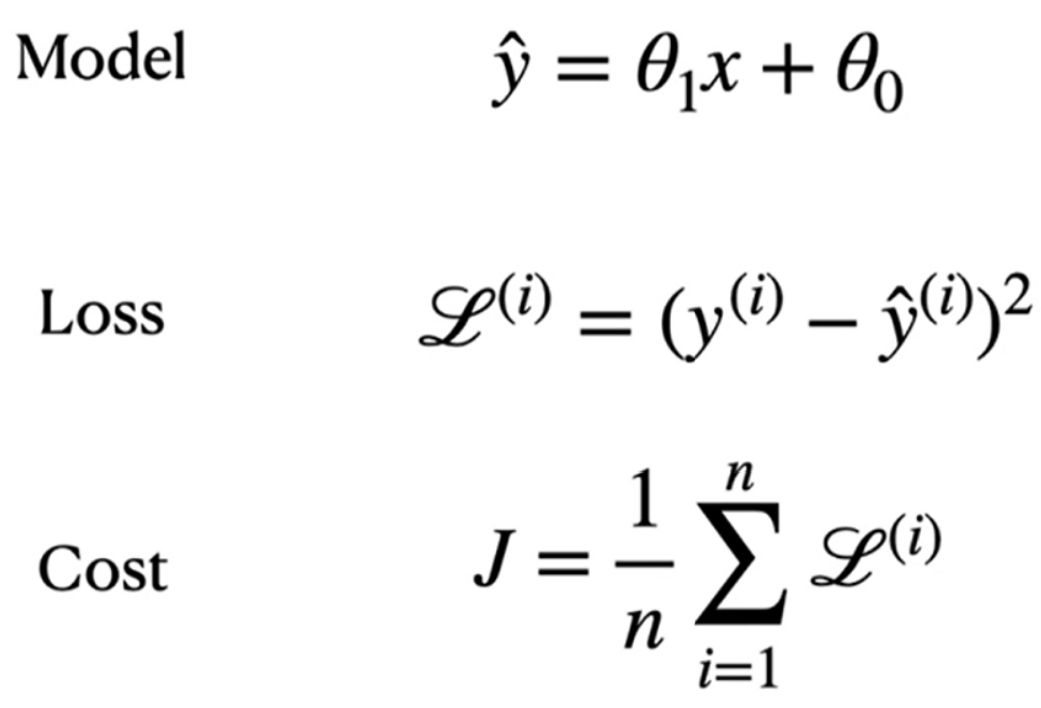
하지만 보통 입력값이 다차원으로 되어있는 경우가 많기 때문에, 이 식을 기본형으로 바꾼다면,

세타와 x를 다차원의 벡터로 바꿀 수 있다. 그리하여 최종적인 식은 밑에와 같아진다.
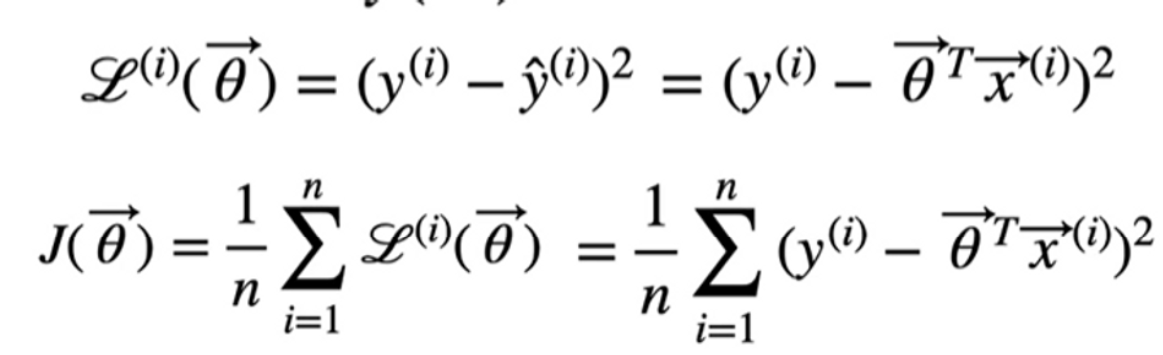
사실 이러한 함수들을 시각화 하는것은 가능하지만 굳이 하지는 않는다. 또한 보통 몇 백, 몇 천 차원의 함수를 이용해서 모델 학습을 진행할 건데, 이를 시각화 하는 것은 시간낭비이다. 여기서 우리가 알 수 있는 것은 기울기 뿐이다. 마치 어두운 산속에서 발바닥으로만 기울기가 느껴지는 정도이다. 그럼 우리는 그 기울기가 밑으로 가는 방향으로 그저 갈 뿐이다.
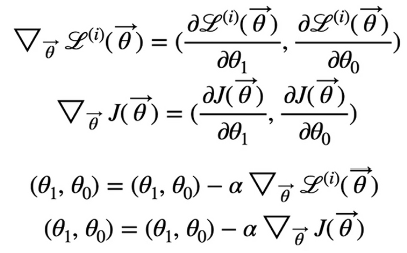
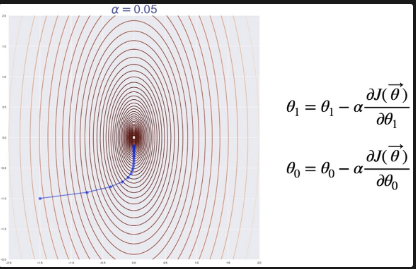
하여, 우리는 gradient를 사용해 오차함수의 최저점을 찾아갈 것이며, 이는 learning rate를 곱한 것을 빼는 방식으로 각각의 세타를 학습시킬 것이다. 여기서 learning rate는 하이퍼파라미터(사람이 정하는 값)으로 학습을 반영시키는 정도라고 알아놔도 되며, 보통 아주 작은 수를 대입시킨다. ex) 0.001, 0.0003 …
기본적인 인공신경망
ANN(Artifucial Neuron Network)
ANN은 인공신경망으로 사람의 뇌 속 뉴런의 작용을 본떠 패턴을 구성한 컴퓨팅 시스템 일종이다. ANN은 가중치를 적용한 방향성 그래프라고 보면 가장 적당하다. 이를 보통 여러 계층으로 구조화 하는데, 생물학적 뉴런과 마찬가지로 수많은 노드가 있으며, 활성화 함수를 통해 정보를 보낼지 말지를 결정합니다. 그 중 Perceptron은 가장 단순한 유형의 인공신경망으로 대개 이진법 예측을 하는데 쓰입니다.
다층 인공 신경망
완전히 연결된 다층 신경망을 다층 퍼셉트론(Multilayer Perceptron, MLP)라고 한다. 이 유형의 인공신경망은 하나 이상의 인공 뉴런이나 노드 계층으로 구성되어있다. 다층의 ANN은 복잡한 분류나 회귀 작업을 해결하는 데 쓰이며, input, hidden, output layer로 구성되어 있습니다.
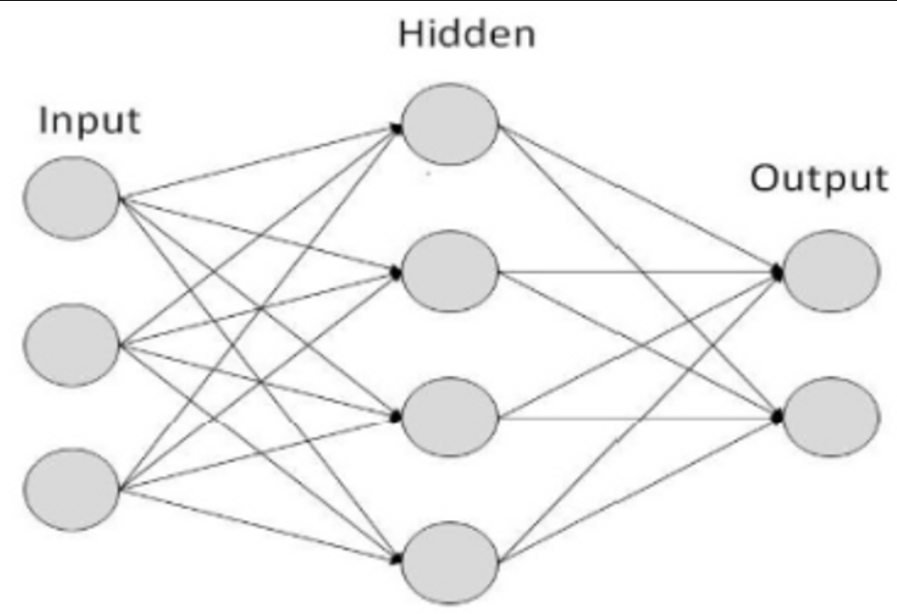
이러한 신경망은 forward propagation과 back propagation을 통해 학습을 진행합니다. 즉, 입력값이 들어가면 은닉층을 지나 모델은 예측값을 출력해내며, 이를 정답과의 차이(오차값)를 이용해 다시 입력층까지 연쇄법칙(Chain rule)을 이용해 편미분을 진행, 위에서 보였던 gradient를 통해 가중치의 최적화를 진행합니다.
(연쇄법칙의 예시)
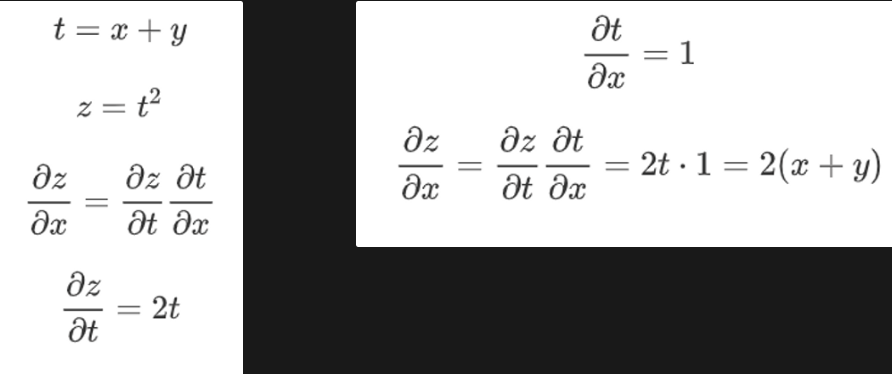
위의 모델을 한 번 자세히 살펴보면 아래와 같은 노드들로 구성되어 있다는 것을 알 수 있다. 거의 모든 신경망 혹은 모델들의 구조는 아래와 같은 노드들의 조합으로 만들어져 있다.
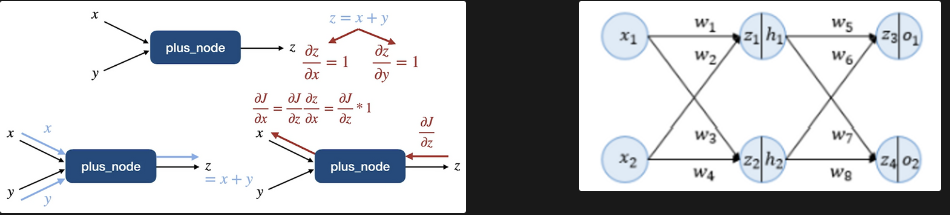
출처: https://ardino-lab.com/, 딥러닝 파이토치 교과서(책)
