
머신러닝이란?
AI는 인공지능으로 그 안에는 머신러닝(ML), 그리고 딥러닝은 머신러닝 안에 포함된다고 할 수 있습니다.
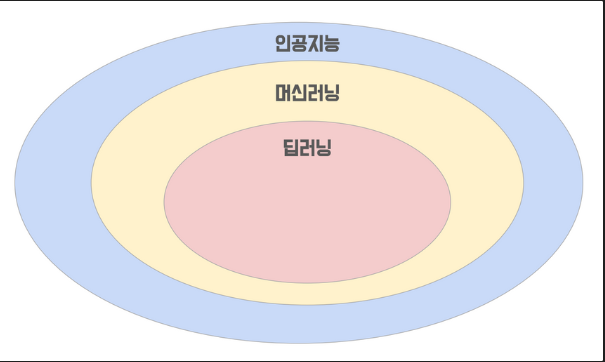
또한 인공지능은 규칙기반과 학습기반으로 나눌 수 있는데요, 규칙기반은 어떤 입력이 들어오면 어떤 출력이 나오는지를 결정하는 규칙 혹은 알고리즘을 사람이 정하는 것이고, 학습기반은 그러한 규칙을 사람이 만드는 것이 아니라 대량의 데이터를 통해 컴퓨터가 스스로 규칙을 찾아 나가는 것을 의미합니다. 머신러닝은 학습기반에 속한다고 할 수 있습니다.
그래서 머신러닝이 진짜 원하는 것, 목표는 무엇일까요? 또 무엇으로, 어떻게 학습을 진행하는 것일까요?
학습의 목표
그렇다면 학습을 한다고는 했지만 무엇을 학습을 하는 것일까요?
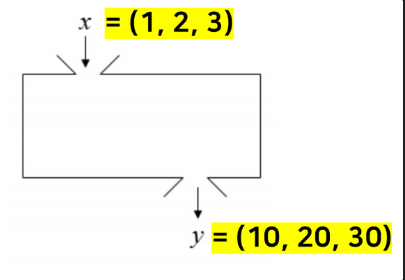
머신러닝은 데이터로 부터 컴퓨터가 학습하는 것이라고 했는데, 여기서 학습하는 것을 바로 데이터 간의 상관관계(Hypothesis)입니다. 예를 들어 x = 1, 2, 3 이고 y = 10, 20, 30 이라고 합시다.
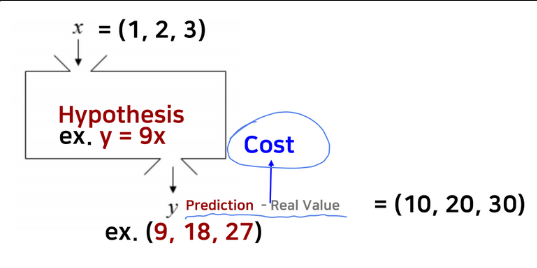
만약 y = 9x 라고 기계가 예측을 했다고 칩시다. 그렇다면 우리는 여기서 오차, 즉 Cost값이 생긴다는 것을 알 수 있습니다. 이를 통해 우리는 한 가지 정리할 수 있습니다. “Hypothesis는 머신러닝의 목적이고, Cost는 그 Hypothesis의 평가지표 라는 것”을 알 수 있었습니다. 그렇다면 머신러닝의 목적을 달성하기 위해서는 이상적인 상관관계, 즉, 오차값이 가장 낮은 상관관계를 찾는 것을 의미할 것입니다.
그렇다면 오차값을 낮출려면 어떤 값을 움직여야 할까요? 바로 가중치(weight)입니다. 이 가중치를 움직이는 것이 바로 컴퓨터이며, 컴퓨터는 데이터의 출력값을 통해 오차를 계산, 다양한 방식으로 가중치를 조절하게 될 것입니다. 즉, 정리해서 말하자면, 상관관계의 뼈대는 사람이 만드는 것이며, 오차값이 가장 낮을 때의 가중치를 찾는 것이 머신러닝의 궁극적인 의미라고 볼 수 있습니다.
학습의 차이점
머신러닝은 또 2가지로 나눠질 수 있는데, 바로 지도학습과 비지도학습이다. 사실 지도학습인지 비지도학습인지는 데이터만 봐도 알 수 있다. 지도학습은 x와 y값이, 비지도학습은 x값만 있다고 보면 된다.
지도학습의 목적은 위에서 봤듯이, x와 y의 관계성 파악을 토대로 새로운 x값이 왔을 때, y값을 예측하는 것에 초점을 둔다. 회귀와 분류로 구분된다. 회귀는 어떤 값을 예측하며, 분류는 어떤 카테고리를 예측한다.
비지도학습은 x값 간의 관계성 파악에 목적을 두고 있다. 군집화(clustering)과 비지도변환(transformation)으로 나눌 수 있다. 군집화는 x간의 관계를 파악해서 그룹화를 진행하는 것이며 K-Means, Gaussian Mixture Model 등이 이에 포함됩니다. 또한, 비지도변환은 데이터를 새롭게 표현해 사람이나 다른 머신러닝 알고리즘이 원래 데이터보다 쉽게 해석할 수 있도록 만드는 알고리즘 입니다. 대표적인 예로 차원축소가 있습니다.
학습의 방법
그렇다면 지금까지 우리는 머신러닝이 뭔지도 알았고, 어떤 값을 찾는지, 무슨 학습이 있는지도 알아봤습니다. 그렇다면 컴퓨터가 찾고자 하는 가중치를 어떻게 찾아야 하는 것일까요?
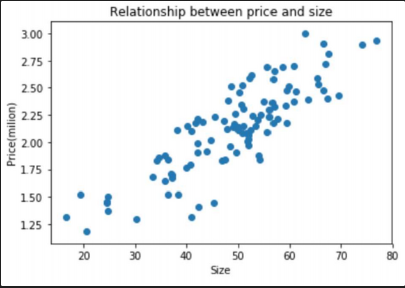
위의 데이터를 예로 들어봅시다. 우리는 저 점들을 포괄할 수 있는, x와 y의 관계를 표현할 수 있는 어떤 단순한 직선을 찾는다고 가정해봅시다.
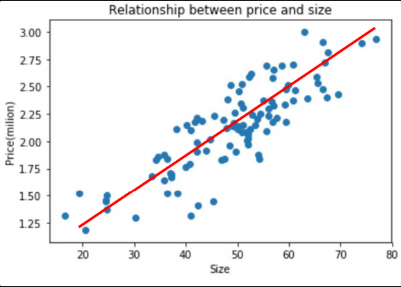
우리는 직관적으로 저 빨간색 선을 긋게 될 것입니다. 하지만 컴퓨터는 이를 직관적으로 파악하지 못합니다. 그래서 우리는 단계를 나눠 컴퓨터가 저 빨간선을 찾을 수 있도록 단계를 나눕니다.
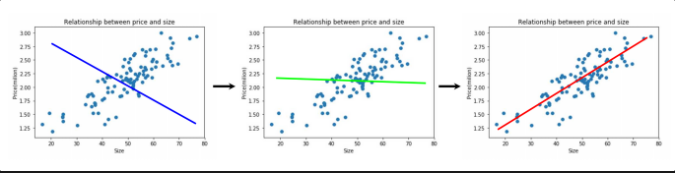
- 임의의 직선을 하나 고릅니다.
- 직선과 해당되는 실제 값 간의 오차를 계산합니다.
- 직선을 업데이트해 오차값을 줄여나갑니다.
이제 우리는 어떻게 직선을 찾는지 대략적으로 알았습니다. 그렇다면 이 직선의 핵심이 되는 가중치를 어떻게 찾아갈까요? 이때 필요한 것이 바로 편미분입니다.
거의 모든 영역(머신러닝/딥러닝)에서 사용되는 방법으로, 그 형태만 조금씩 바뀔뿐, 가중치를 찾아가는 방법의 가장 큰 줄기는 편미분을 통해 찾아가는 것입니다.
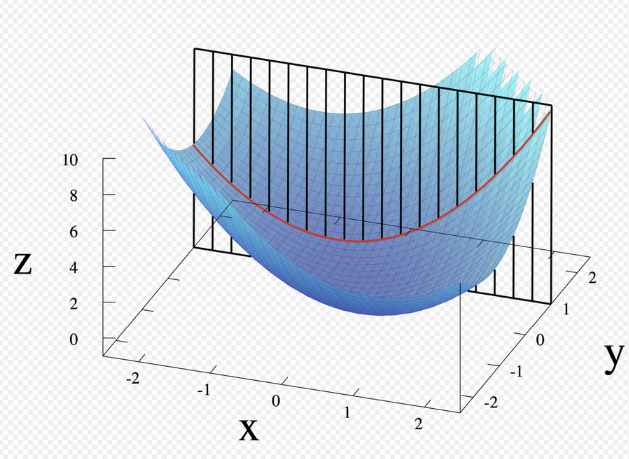
편미분의 정의는 다변수 함수의 특정 변수를 제외한 나머지 변수를 상수로 간주해 미분하는 것입니다. 즉, 다양한 변수가 있는 함수에서 특정 변수를 x로 잡고 미분을 진행한다면, x를 제외한 다른 변수들은 모두 상수 취급을 한 후 미분을 진행하는 것을 뜻합니다.
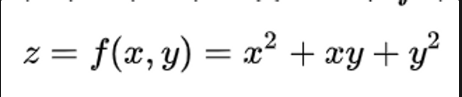
이를 통해 우리는 3차원을 넘어 4차원, 5차원 함수에서의 변수들의 변화률을 알 수 있게 되었습니다. 또한 우리는 예전 고등학교때 미분한 값이 0이 된다면 이를 극소값 혹은 극대값이라고 했습니다. 편미분도 마찬가지입니다.
위의 z함수를 예를 들자면 우리는 x로 미분한 값, y로 미분한 값이 0이 되는 x 혹은 y 값을 찾는다면 z의 극소값을 찾을 수 있을 것입니다. 이를 우리는 gradient(그라디언트)라고 부릅니다.
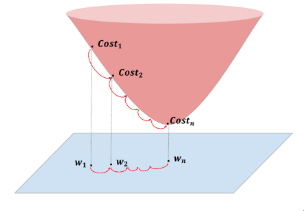
우리는 gradient를 구함으로서 오차값이 가장 낮은 부분을 찾아갈 것입니다. 먼저 W1에서의 경사를 보고 경사가 완만해지는 방향으로 업데이트 할 것입니다.
한번 예를 들어봅시다.
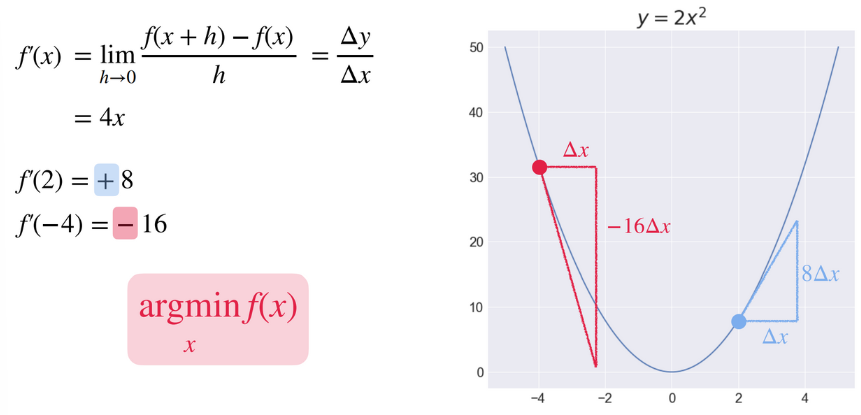
(fast campus 고마워요!)
x가 2일때를 보면 dx가 커질때 y값은 dx의 8배 만큼 커진다는 것을 알 수 있습니다. 이는 x를 오른쪽으로 옮길수록 y값이 더 커진다는 것을 암시하기도 합니다.
반대로 x가 -4일때 dx가 커질시 y값은 dx의 16배 만큼 감소한다는 뜻이며, 이는 x를 왼쪽으로 옮길수록 y값이 커진다는 것을 암시합니다.
그렇다면 이 y값을 오차라고 생각해봅시다. 우리가 궁극적으로 원하는 것은 오차가 최소가 되는 값을 찾는 것이며, 그 값을 찾기 위해서는 기울기가 완만해지는, 즉, 미분값이 0이 되는 w를 찾기 위해 아래와 같은 식을 사용해야 한다는 것입니다. 이를 식으로 표현하면 아래와 같이 표현할 수 있으며, 이것을 우리는 gradient decent, 즉, 경사하강법이라고 합니다. (보통 a는 매우 작은 수로 표현됩니다.)

오차함수
지금까지 우리는 미분을 통해 오차값이 가장 작은 w를 찾는다고 했습니다. 그렇다면 이번에는 우리가 미분해야할 오차함수(다른 말로는 손실함수라고도 한다)를 알아봅시다.
오차함수는 측정한 데이터를 토대로 산출한 모델의 예측값과 실제값의 차이를 표현하는 지표이다. 즉, 모델이 데이터를 얼마나 잘 표현하지 못하는가를 나타내는 지표라고 할 수 있다. 따라서 얼마나 잘 표현하지 못하는가를 어떤 방식으로 표현하느냐에 따라 다양한 손실함수가 존재한다.
머신러닝과 딥러닝에서 자주 쓰이는 오차함수로는
Mean Squared Error(MSE) - 평균 제곱 오차와 Mean Absolute Error(MAE) - 평균 절대 오차로 주로 회귀에 많이 쓰이는 오차함수이다. 이 둘중 주로 가장 많이 쓰이는 것은 MSE이다. 특히 MSE는 오차의 제곱을 구해서 실제 오류 평균보다 더 커지는 특성이 있기 때문에 루트를 씌운 RMSE도 사용되어지곤 한다.
평균 절대 오차는 L1, 평균 제곱 오차는 L2 라고도 한다.
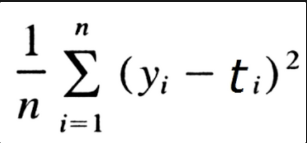
MSE (y는 정답, t는 예측값이다)
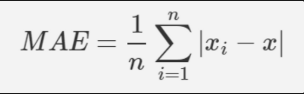
MAE(xi는 정답, x는 예측값이다)
아울러 Categorical CrossEntropy - 범주형 교차 엔트로피와 binary CrossEntropy - 이항 교차 엔트로피로 둘은 주로 분류에 쓰이는 함수로, 범주형은 다수의 클래스가 있을 때, 이항 교차 엔트로피는 두개의 객체를 구분할 때 사용한다.
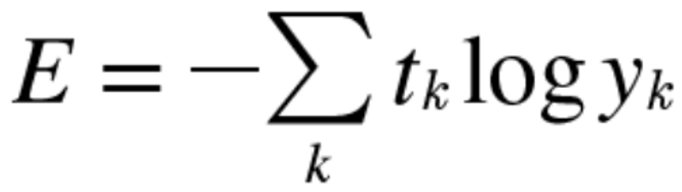
t는 예측값, y는 정답이다.
출처: https://ardino-lab.com/, 딥러닝 파이토치 교과서(책)
