토이 프로젝트를 진행하면서 발생했던 문제에 대한 본인의 생각과 고민을 기록한 글입니다.
기술한 내용이 공식 문서 내용과 상이할 수 있음을 밝힙니다.
Mysql 공식문서 참고: https://dev.mysql.com/doc/refman/8.0/en/
Scale-Out이란?
Scale-Out이란 시스템의 처리 능력을 향상시키기 위해 하드웨어를 추가하는 방식을 말한다. 주로 서버의 개수를 늘려서 전체 시스템의 성능을 향상시키는 방법이다.
Slave를 Scale-Out하게된 이유
- Write/Read의 작업을 분리시켜 부하 분산 방법으로 Master-Slave를 선택했다. 하지만 Read 작업 역시 웹 서버의 트래픽이 증가하면서 기존의 한 대의 서버로는 부하를 감당하기 어려워질 수 있다. 따라서 서버 증설로 각 서버는 더 적은 양의 트래픽을 처리하게 되므로 성능 향상 및 데이터를 분산 저장함으로써 데이터의 안정성을 높일 수 있다.
- MHA(Master High Availability)를 사용하여 Master-Slave 구조의 안정적인 Failover하려면, Slave 서버가 최소 2대 이상이어야 한다. 이는 Master 서버에 장애가 발생했을 때, Slave 서버 중 하나를 새로운 Master로 승격시키고, 나머지 Slave 서버들이 새로운 Master를 참조할 수 있도록 한다.
기존 Master-Slave (1:1) 구조
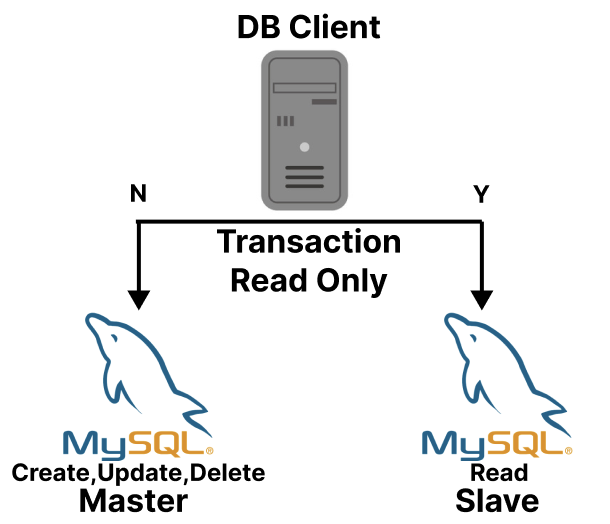
MHA(Master High Availability)는 기본적으로 Master 서버와 Slave 서버가 각각 1대씩 있을 때도 작동한다. MHA의 주요 기능 중 하나는 Master 서버에 장애가 발생했을 때, Slave 서버를 자동으로 Master로 승격시킨다. 이를 통해 서비스 중단 시간을 최소화하고 데이터 손실을 방지할 수 있다.
그러나 Slave 서버가 1대만 있을 경우, 해당 Slave가 새로운 Master로 승격된 후에는 고가용성을 유지하기 어렵다. 왜냐하면 새로운 Master 서버에 문제가 발생하면 이를 대체할 추가적인 Slave 서버가 없기 때문이다.
따라서, Master-Slave 구조의 데이터베이스에서 Failover를 제공하려면, Slave 서버를 최소 2대 이상 구성하는 것이 좋다. 이렇게 하면 한 Slave 서버가 Master로 승격된 후에도 남은 Slave 서버를 이용해 고가용성을 유지할 수 있다.
Scale-Out 이후 Master-Slave(1:多) 구조
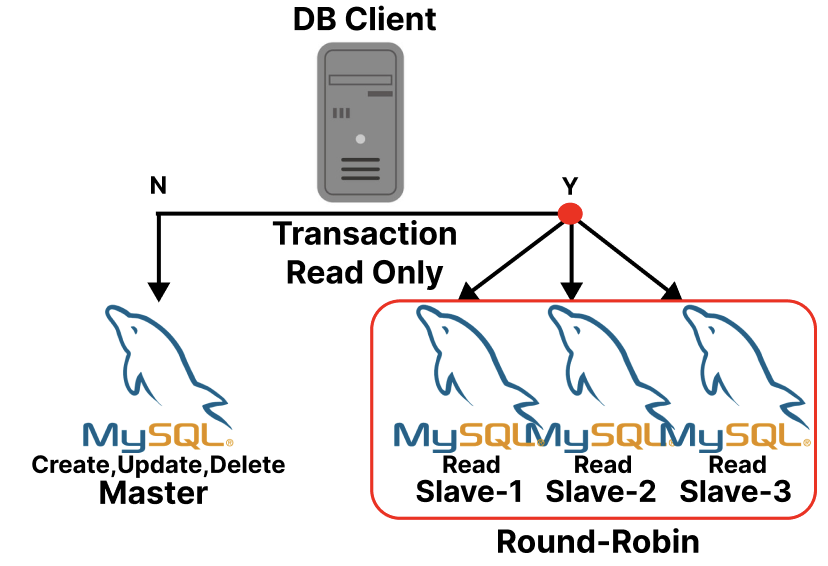
(이전글을 통해 Master-Slave 설정 및 SpringBoot 연동에 대해서 참고할 수 있습니다.)
보조 서버(Slave)를 2대 이상으로 늘릴 경우, 애플리케이션 코드에서는 데이터베이스 연결을 관리하기 위한 추가적인 로직이 필요하다.
순서
- Slave Configuration File 설정
- Docker Image 및 Container 구성
- Slave DB 설정
- SpringBoot MultiDataSource, RoutingDataSource Rafactoring
Slave Configuration File
# /Users/Docker/mysql/slave2
[mysqld]
server-id=3 // DB 식별자 ID Docker Image 및 Container 구성
docker run --name mysql-slave2 -v /Users/Docker/mysql/slave2:/etc/mysql/conf.d --link mysql80 --network db_network -e MYSQL_ROOT_PASSWORD=1234 -p 3308:3306 -d mysql:8
// master 3306:3306, slave-1 3307:3306 slave-2 3308:3306Slave DB 설정
// vim /etc/my.cnf
[mysqld]
skip-host-cache
skip-name-resolve
datadir=/var/lib/mysql
socket=/var/run/mysqld/mysqld.sock
secure-file-priv=/var/lib/mysql-files
user=mysql
bind-address=0.0.0.0 // 추가 - 외부 접속 출처 허용
mysqlx-bind-address=127.0.0.1 // 추가 - MySQL X Plugin 연결에 대해 localhost만 허용
pid-file=/var/run/mysqld/mysqld.pid
[client]
socket=/var/run/mysqld/mysqld.sock(권한 설정을 해주지 않아서 slave-2가 3시간동안 스키마 및 데이터 복제가 안 됐었다.)
GRANT REPLICATION SLAVE ON *.* TO 'root'@'%'; // root 권한 허용
FLUSH PRIVILEGES;SpringBoot Logic Refactoring
yml
datasource:
master:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/yunni_bucks_traffic?rewriteBatchedStatements=true
username: root
password: 1234
auto-commit: false
connection-test-query: SELECT 1
maximum-pool-size: 40
pool-name: mysqlM-example-cp
hibernate:
ddl-auto: validate
slaves:
- name: slave-1
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3307/yunni_bucks_traffic?rewriteBatchedStatements=true
username: root
password: 1234
hibernate:
ddl-auto: validate
- name: slave-2
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3308/yunni_bucks_traffic?rewriteBatchedStatements=true
username: root
password: 1234
hibernate:
ddl-auto: validateDatabaseProperties
@Slf4j
@Data
@Component
@ConfigurationProperties(prefix = "spring.datasource")
public class DatabaseProperties {
private DatabaseDetail master, postgres;
private List<DatabaseDetail> slaves;
@Data
public static class DatabaseDetail {
private String driverClassName;
private String url;
private String username;
private String password;
}
}yml로 설정된 Datasource를 가져온다. (변수명이 일치해야 yml의 속성과 매핑된다.) Slave는 List Collection로 가져와야 이후에 N대 이상 확장을 해도 코드 수정을 할 필요가 없다고 판단하였다.
DataSourceConfig
@Configuration
@Slf4j
public class DataSourceConfig {
@Bean
public DataSource routingDataSource(@Qualifier("masterDataSource") DataSource masterDataSource,
@Qualifier("slaveDataSources") List<DataSource> slaveDataSources) {
Map<Object, Object> dataSources = new LinkedHashMap<>();
dataSources.put("master", masterDataSource);
IntStream.range(0, slaveDataSources.size())
.forEach(i -> {
DataSource slaveDataSource = slaveDataSources.get(i);
dataSources.put(String.format("slave-%d", (i + 1)), slaveDataSource);
});
List<Object> onlySlaveDataSources = new ArrayList<>(dataSources.values());
onlySlaveDataSources.remove(masterDataSource);
List<String> slaveDataSourceNames = dataSources.keySet().stream()
.map(Object::toString)
.filter(key -> key.startsWith("slave")).toList();
RoutingDataSource routingDataSource = new RoutingDataSource(onlySlaveDataSources, slaveDataSourceNames);
routingDataSource.setTargetDataSources(dataSources);
routingDataSource.setDefaultTargetDataSource(masterDataSource);
return routingDataSource;
}
...
@Bean("slaveDataSources")
public List<DataSource> createSlaveDataSources(DatabaseProperties databaseProperties) {
List<DataSource> slaveDataSources = new ArrayList<>();
for (DatabaseDetail slave : databaseProperties.getSlaves()) {
slaveDataSources.add(createDataSource(slave));
}
return slaveDataSources;
}
...
@Slf4j
private static class RoutingDataSource extends AbstractRoutingDataSource {
private final AtomicInteger index = new AtomicInteger(0);
private final List<Object> slaveDataSources;
private final List<String> slaveDataSourceNames;
public RoutingDataSource(List<Object> slaveDataSources, List<String> slaveDataSourceNames) {
this.slaveDataSources = slaveDataSources;
this.slaveDataSourceNames = slaveDataSourceNames;
}
@Override
protected Object determineCurrentLookupKey() {
String dataSourceName = TransactionSynchronizationManager.isCurrentTransactionReadOnly()
? slaveDataSourceNames.get(index.getAndIncrement() % slaveDataSources.size())
: "master";
log.info("[DATA_SOURCE_NAME] : {}", dataSourceName);
return dataSourceName;
}
}
}-
createSlaveDataSources()
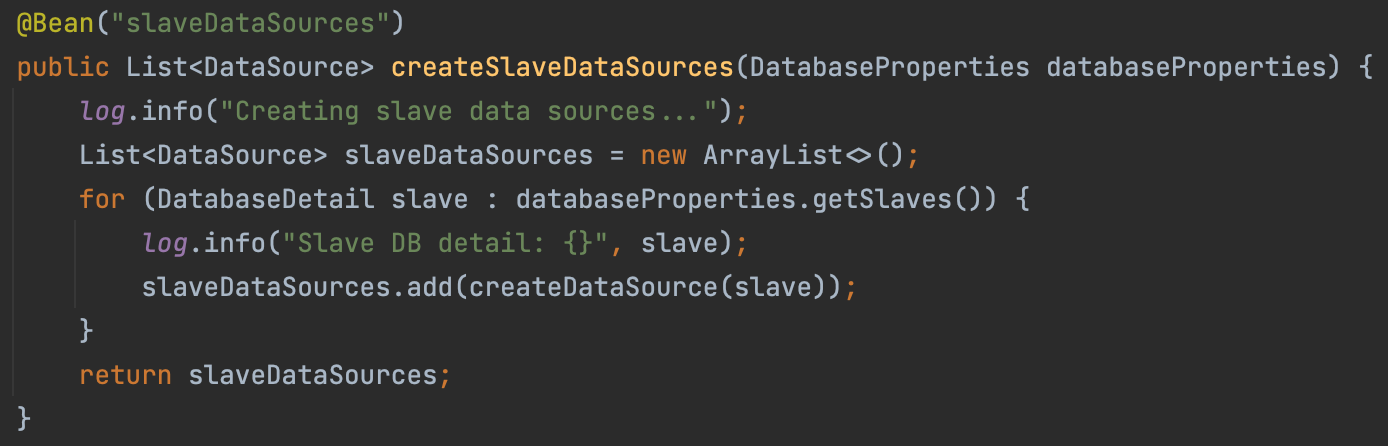
이전 코드에서는 단일 slave 데이터베이스에 대한 DataSource 객체를 생성했지만, 이 코드에서는 여러 slave 데이터베이스에 대한 DataSource 객체들을 생성할 수 있다. 서비스가 확장됨에 따라 데이터베이스 서버의 수가 증가할 수 있음을 대비한 것이다.
DatabaseProperties의 getSlaves() 메서드는 slave 데이터베이스 상세 정보의 리스트를 반환한다. 리스트의 각 요소에 대해 createDataSource 메서드를 호출하여 DataSource 객체를 생성하고, slaveDataSources 리스트에 추가한다.
-
determineCurrentLookupKey()
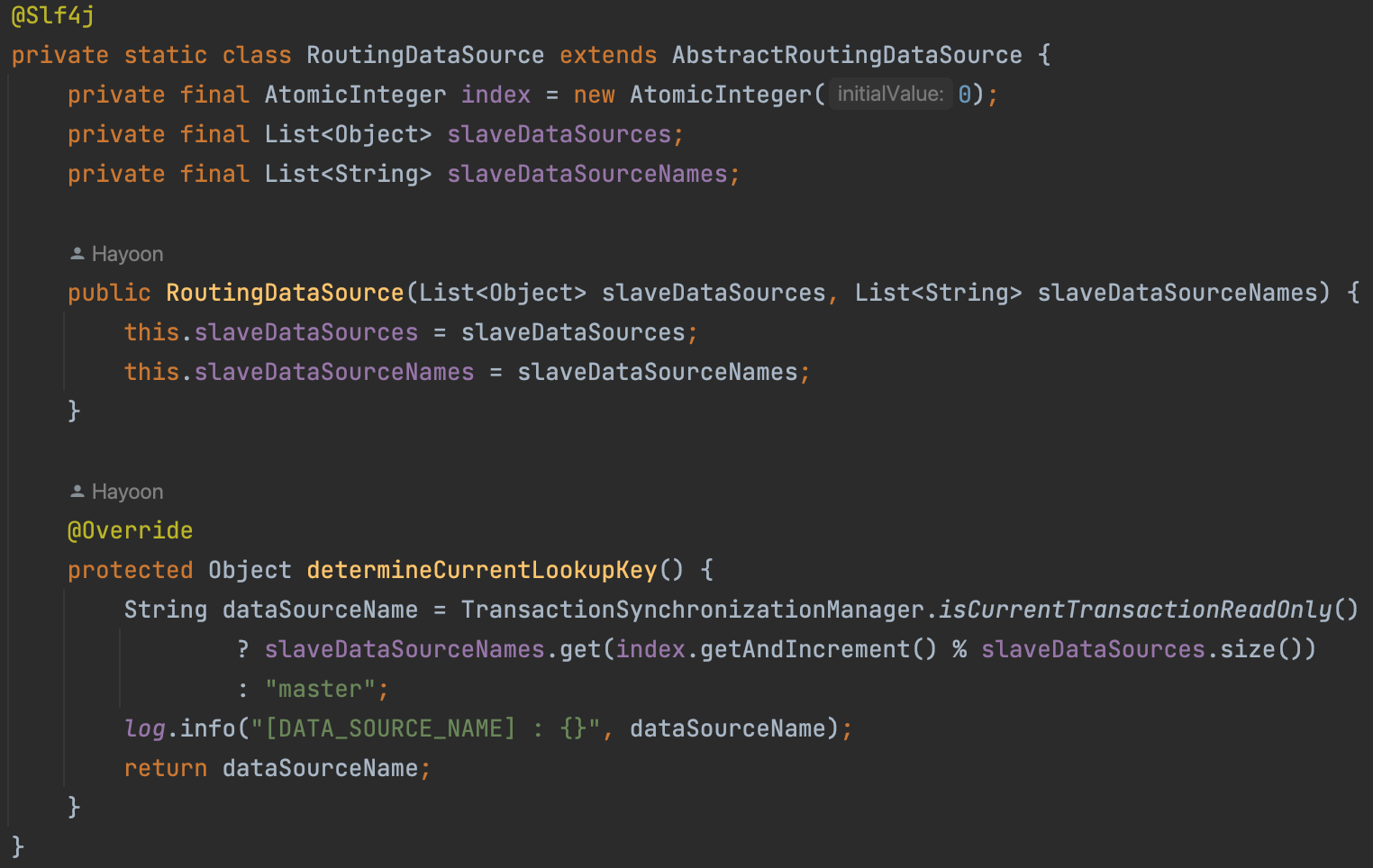
이 클래스는 트랜잭션의 읽기 전용 여부에 따라 사용할 DataSource를 결정한다.
determineCurrentLookupKey() 메서드는 현재 트랜잭션의 읽기 전용 여부를 확인하여 사용할 DataSource의 이름을 결정한다.
트랜잭션이 읽기 전용인 경우 → index를 사용하여 slaveDataSourceNames 리스트에서 DataSource의 이름을 선택한다. 이때, index는 증가하며, slaveDataSources 리스트의 크기로 나눈 나머지를 사용하여 리스트의 범위를 넘어가지 않도록 하여 Round-Robin 방식으로 순차적으로 slave DataSource를 선택한다.
트랜잭션이 읽기 전용이 아닌 경우 → 즉 쓰기 작업인 경우, master를 반환하여 master DataSource를 사용하도록 한다.AtomicInteger index = new AtomicInteger(0)를 사용한 이유?
여러 스레드가 동시에 determineCurrentLookupKey() 메서드를 호출할 수 있다. AtomicInteger의 getAndIncrement() 메서드를 사용하면 동시에 여러 스레드가 getAndIncrement() 메서드를 호출하더라도 각 스레드는 다른 값을 얻게 된다. 따라서, 각 스레드는 서로 다른 slave DataSource를 선택하여 제대로 된 로드 밸런싱을 가능하게 한다.
-
routingDataSource()
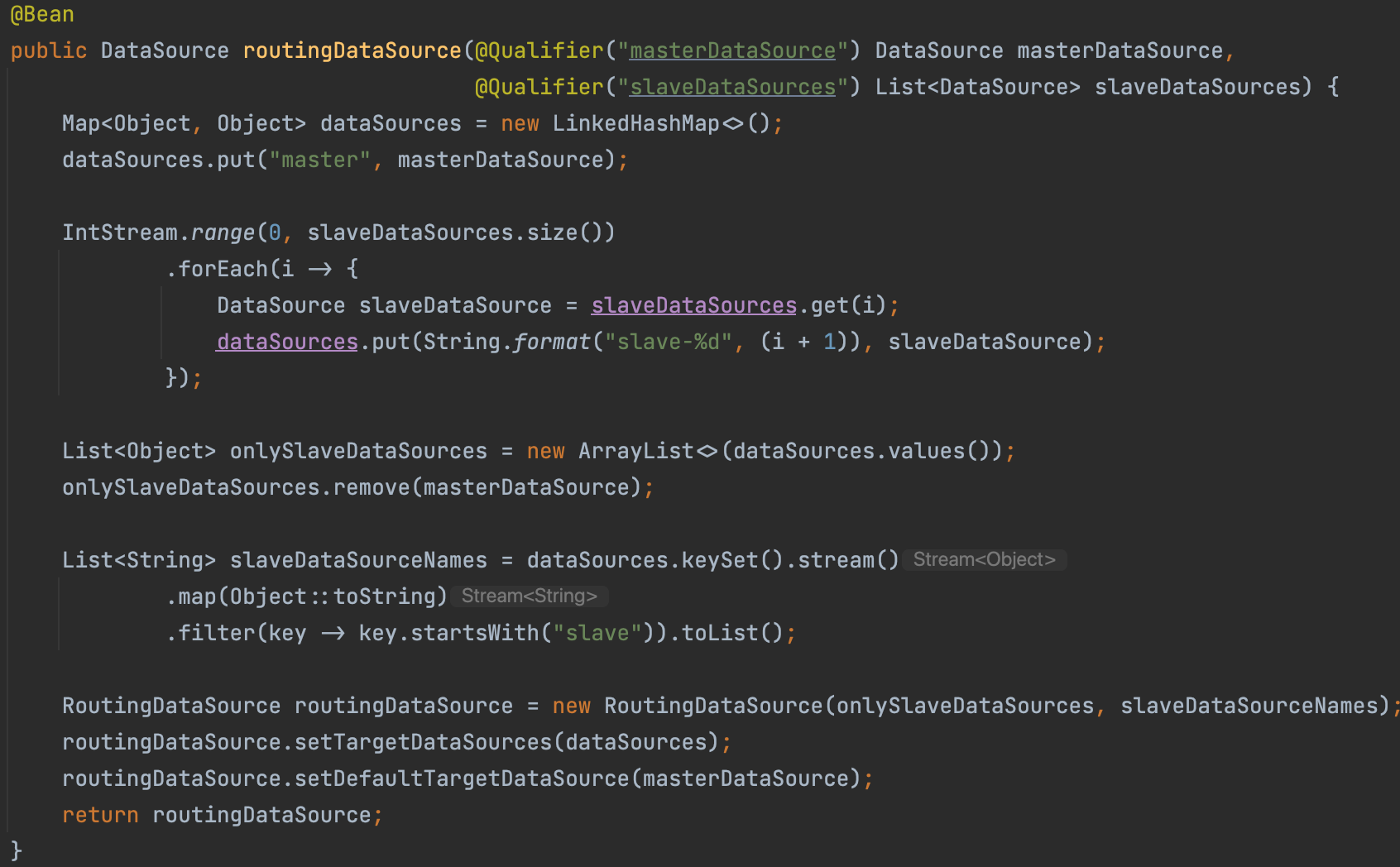
이 코드는 master DataSource와 여러 slave DataSource를 관리하는 RoutingDataSource를 생성하는 Spring Bean을 정의한 것이다.a. master DataSource와 slave DataSource들을 모두 포함하는 dataSources Map을 생성한다. master DataSource의 이름은
master로 고정되어 있고, slave DataSource들의 이름은slave-1,slave-2등으로 설정한다.b. onlySlaveDataSources 리스트를 생성하여 slave DataSources 추출한다. 이 리스트는 나중에 RoutingDataSource 생성자에 전달되어, 읽기 전용 트랜잭션에서 사용할 DataSource를 결정하는 데 사용된다.
c. RoutingDataSource 객체를 생성하고, setTargetDataSources 메서드와 setDefaultTargetDataSource 메서드를 호출하여 dataSources Map과 master DataSource를 설정한다. 이렇게 생성된 RoutingDataSource 객체는 Write/Read 트랜잭션에 따라 적절한 DataSource를 선택한다.
TEST
@PostConstruct
public void init() throws IOException {
member = userRepository.save(member());
menu = menuRepository.save(bread());
Faker faker = new Faker(new Locale("ko"));
for (int i = 0; i < 10; i++) {
String comments = faker.lorem().sentence(); // 랜덤한 문장 생성
MenuReview menuReview = MenuReview.builder()
.id((long) (i + 1))
.comments(comments)
.member(member)
.menu(menu)
.now(now())
.build();
menuReviews.add(menuReview);
}
menuReviewJdbcMysqlRepository.saveReviewsByJdbc(menuReviews, member.getId(), menu.getId());
}
@Test
void MasterSlavesTest() {
for (MenuReview menuReview : menuReviews) {
System.out.println("--saveStart--");
menuReviewRepository.save(menuReview);
System.out.println("--saveEnd--");
}
System.out.println("--findAll--");
for(int i = 1; i <= 10; i++) {
menuReviewRepository.findAll();
}
}save()와 findAll()을 통해서 Master과 Slave들이 제 역할을 하는지 확인해보자. 예상대로라면 save()는 master이, findAll()은 Slave 서버들이 돌아가면서 수행할 것이다.
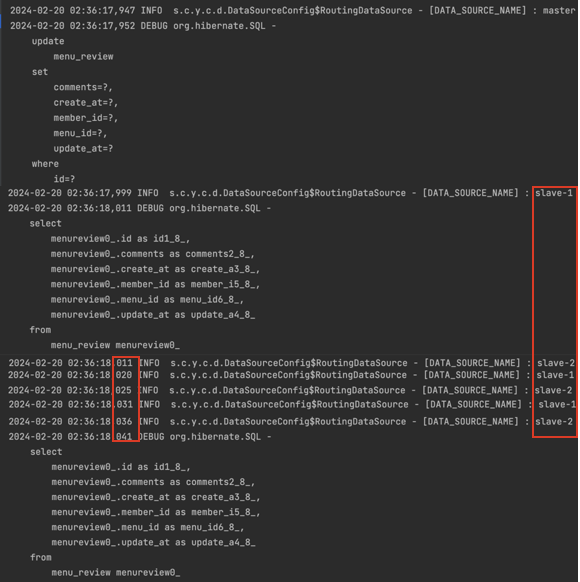 slave 1-2-1-2-1-2로 순환하면서 공평하게 자원을 사용하는 Round Robin 방식이 잘 적용된 것 같다.
slave 1-2-1-2-1-2로 순환하면서 공평하게 자원을 사용하는 Round Robin 방식이 잘 적용된 것 같다.
Round-Robin을 채택한 이유는 아래와 같다.
공평성: Round-Robin 방식은 각 슬레이브 데이터 소스를 동일하게 사용하여, 특정 데이터 소스에 과도한 부하가 가지 않도록 하는 장점이 있다.
단순성: Round-Robin은 로직이 간단하다. 복잡한 알고리즘에 비해 버그 발생 확률이 낮고, 유지보수도 쉽다.
효율성: Round-Robin은 요청을 고르게 분산시키므로, 전체적인 시스템 성능을 향상시킬 수 있다.
Slave DB를 증설한 것 뿐이라 RoutingDataSource 이외 로직이 이전과 크게 다르지 않다.
다음에는 MHA를 사용하여 Master-Slave Failover를 구축해보겠다.
