토이 프로젝트를 진행하면서 발생했던 문제에 대한 본인의 생각과 고민을 기록한 글입니다.
기술한 내용이 공식 문서 내용과 상이할 수 있음을 밝힙니다.
프로젝트 로직 중 redis의 caching data를 RDB로 반영시키는 과정이 있다. 그 과정에서 성능을 개선해나갔던 내용에 대해 얘기해보려고 한다.
구체적으로 어떤 로직에서 활용?
카페 메뉴를 조회할 때 베스트 메뉴, 즉 인기메뉴가 있다. 인기 메뉴 순위를 산정하기 위해 메뉴 검색 시 메뉴별 점수 1점을 부여하는데, Redis가 점수를 부여하고 DB에 반영하여 일일, 주간, 월간 인기메뉴 별 데이터를 보관하기 위해 DB에 저장하는 로직에서 성능 개선의 필요성을 느꼈다.
Write-Back 캐싱전략?
Write-Through랑 이름은 비슷하지만, 캐시 업데이트 전략이 다르다.
-
Write-Through 전략에서는 클라이언트의 요청이 들어오면, 먼저 캐시(여기서는 Redis)를 업데이트하고, 그 다음으로 RDB를 업데이트한다. 두 작업은 순차적으로 이루어지며, RDB의 업데이트가 완료된 후에야 클라이언트에게 응답이 반환되어 캐시와 백엔드 저장소 사이의 데이터 일관성을 유지할 수 있다.
-
Write-Back 전략에서는 클라이언트의 요청이 들어오면, 먼저 캐시(여기서는 Redis)를 업데이트하고 즉시 클라이언트에게 응답을 반환한다. 이후 RDB의 업데이트는 다음 두 가지 방식 중 하나로 이루어진다:
a. 일정 시간 간격으로 업데이트: 캐시에서 변경된 데이터를 일정 시간 간격으로 모아서 한 번에 백엔드 저장소에 반영
b. 특정 이벤트 발생 시 업데이트: 캐시의 데이터가 변경된 후 특정 이벤트(예: 캐시의 사용량이 특정 임계값을 초과하거나, 특정 데이터가 캐시에서 삭제되는 등)가 발생했을 때 백엔드 저장소를 업데이트
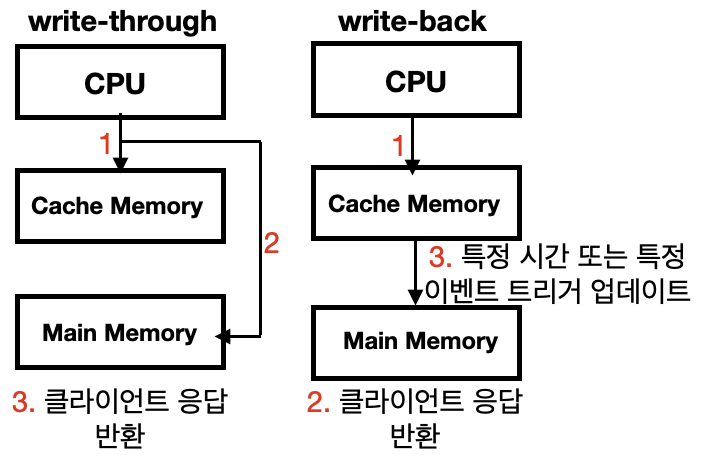
Write-Back를 선택한 이유? 일정 시간 간격 업데이트 고른 이유?
카페 서비스 라는 프로젝트의 비즈니스 측면을 고려해보자. 특정 시간 또는 점심/저녁에 메뉴 조회 시 네트워크 트래픽이 몰릴 수 있다. Write-Through를 적용한다면 레디스에서 실시간으로 RDB에 주문수와 score(인기메뉴 산정값)을 실시간으로 반영해야한다. 이는 병목현상 발생으로 성능 저하 우려가 있다.
따라서, 2가지 측면을 고민해보았다.
1. 결제, 돈과 관련된 데이터가 아니다. 인기 순위 산정을 위한 점수 데이터이기 때문에 상대적으로 데이터의 정합성이 크게 중요하지 않다.
2. 카페 영업마감 시간을 고려해 자정(00:00:00)에 RDB 데이터 반영을 진행한다. (@Scheduler 사용)
로직
메뉴 update
@Transactional
public void updateMenu(Menu menu, int orderCount, int viewCount, double score) {
menu.updatePopularScoreByWritingBack(orderCount, viewCount, score);
}1. for-each loop
@Scheduled(cron = "0 0 0 * * ") // 매일 00시 00분에 실행
public void refreshPopularMenusInRedis() {
Set<String> keys = redisTemplate.keys("menu::");
if (keys == null) {
keys = Collections.emptySet();
}
for (String key : keys) {
try {
Menu popularMenu = (Menu) objectRedisTemplate.opsForValue().get(key);
if (popularMenu != null) {
Menu findMenu = menuRepository.findByTitle(popularMenu.getTitle());
if (findMenu != null) {
Double score = redisTemplate.opsForZSet().score("ranking", popularMenu.getTitle());
if (score != null) {
updateMenu(findMenu, popularMenu.getOrderCount(), popularMenu.getViewCount(), score);
}
}
}
} catch (Exception ex) {
log.error("Failed to process key: {}", key, ex);
}
}
}이 코드는 각 key에 대해 동기적으로 작업을 수행하며, 각 작업이 완료될 때까지 다음 작업은 시작하지 않는다. 모든 작업이 순차적으로 실행되므로 처리 시간이 길어질 수 있다. Postman으로 API를 호출해보자.
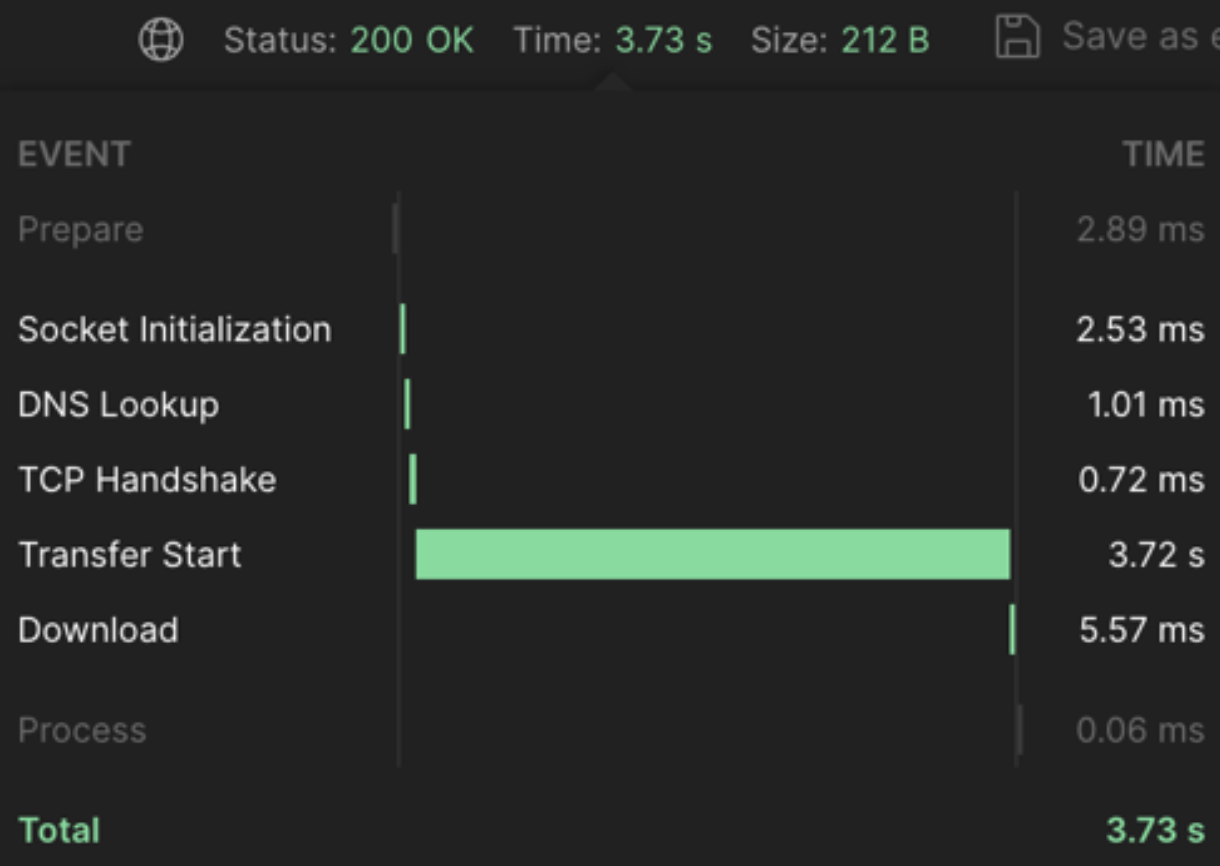 대략 3.73초가 걸린다.
대략 3.73초가 걸린다.
for-each 순차적 처리가 아닌 CompletableFuture로 비동기식으로 리팩토링 해보자.
2. asynchonized
@Scheduled(cron = "0 0 0 * * ") // 매일 00시 00분에 실행
public void refreshPopularMenusInRedis() {
Set<String> keys = Optional.ofNullable(redisTemplate.keys("menu::")).orElse(Collections.emptySet());
List<CompletableFuture<Void>> futures = keys.stream()
.map(key -> CompletableFuture.runAsync(() -> {
Optional.ofNullable((Menu) objectRedisTemplate.opsForValue().get(key))
.ifPresent(popularMenu -> {
Optional.ofNullable(menuRepository.findByTitle(popularMenu.getTitle()))
.ifPresent(findMenu -> {
Double score = redisTemplate.opsForZSet().score("ranking", popularMenu.getTitle());
Optional.ofNullable(score)
.ifPresent(sc -> updateMenu(findMenu, popularMenu.getOrderCount(), popularMenu.getViewCount(), sc));
});
});
}, threadPoolExecutor)
.exceptionally(ex -> {
log.error("Failed to process key: {}", key, ex);
return null;
})).toList();
}이 코드는 각 key에 대해 비동기적으로 작업을 수행한다.
- 비동기 처리: I/O 작업과 같은 블로킹 작업을 병렬로 수행할 수 있다는 점이다.디스크 I/O와 같은 I/O 바운드 작업을 비동기적으로 처리하면, I/O 작업이 진행되는 동안 CPU는 다른 계산 작업을 수행할 수 있다.
- CompletableFuture: CompletableFuture는 비동기 작업의 완료를 기다리는 동안 다른 작업을 수행할 수 있고 예외 처리를 위한 API도 제공하여 비동기 작업에서 발생한 예외를 로그 기록을 통해 대응이 가능하다.
- threadPoolExecutor: 스레드 풀을 사용하면 작업량에 따라 동적으로 스레드 수를 조절할 수 있으므로, 과도한 리소스 사용을 줄이고 시스템의 안정성을 높일 수 있다.
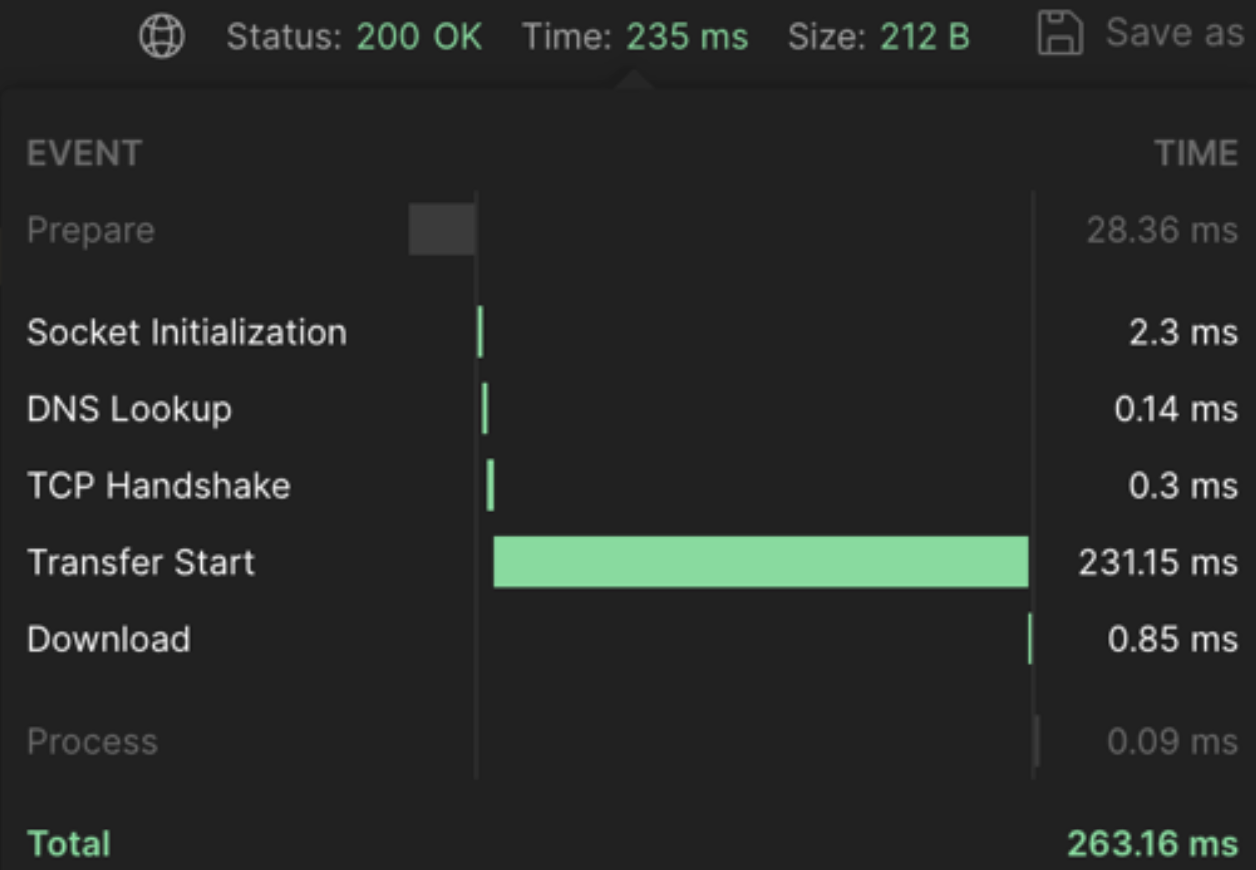 대략 263.16 ms가 걸린다.
대략 263.16 ms가 걸린다.
ThreadPoolExecutor
threadPoolExecutor를 사용하면, 공용 쓰레드 풀(commonPool)과 독립적인 스레드 풀을 사용할 수 있다. 공용 쓰레드 풀을 사용하면, 다른 작업에 의해 쓰레드 풀의 리소스가 고갈될 수 있다. 쓰레드들이 모두 사용 중일 때 추가 작업이 들어오면, 쓰레드가 사용 가능해질 때까지 대기해야 하므로 별개의 customThreadPool를 빈등록하였다.
@Bean
public ThreadPoolExecutor threadPoolExecutor() {
int corePoolSize = 8; // mac M1 CPU 8코어 기준
int maxPoolSize = 16;
long keepAliveTime = 60L;
TimeUnit unit = TimeUnit.SECONDS;
return new ThreadPoolExecutor(
corePoolSize, maxPoolSize, keepAliveTime, unit, new LinkedBlockingQueue<>(), new ThreadPoolExecutor.CallerRunsPolicy());
}3. scan 명령어
@Scheduled(cron = "0 0 0 * * *") // 매일 00시 00분에 실행
public void refreshPopularMenusInRedis() {
ScanOptions options = ScanOptions.scanOptions().match("menu::*").count(500).build();
RedisConnection connection = redisTemplate.getConnectionFactory().getConnection();
try {
Cursor<byte[]> cursor = connection.scan(options);
while (cursor.hasNext()) {
String key = new String(cursor.next());
CompletableFuture.runAsync(() -> {
Optional.ofNullable((Menu) objectRedisTemplate.opsForValue().get(key))
.ifPresent(popularMenu -> {
Optional.ofNullable(menuRepository.findByTitle(popularMenu.getTitle()))
.ifPresent(findMenu -> {
Double score = redisTemplate.opsForZSet().score("ranking", popularMenu.getTitle());
Optional.ofNullable(score)
.ifPresent(sc -> updateMenu(findMenu, popularMenu.getOrderCount(), popularMenu.getViewCount(), sc));
});
});
}, threadPoolExecutor)
.exceptionally(ex -> {
log.error("Failed to process key: {}", key, ex);
return null;
});
}
cursor.close();
} catch (Exception e) {
log.error("Error occurred while scanning keys", e);
} finally {
connection.close();
}
}이 코드는 keys 명령어가 아닌 scan 명령어로 cache key를 가져온다. redis는 단일 쓰레드 구조로 명령을 처리 하고 있는데, keys 명령어는 모든 key를 다 찾을 때 까지 blocking 하기 때문에 다른 client들의 명령어를 수행 하지 못하고 Timeout이 발생 할 확률이 높다.
반면, scan 명령어는 정해진 count개수 만큼 결과를 가져오고, offset 값을 반환 하기 때문에 keys 명령어 처럼 오랜 시간을 block 하지 않는다.
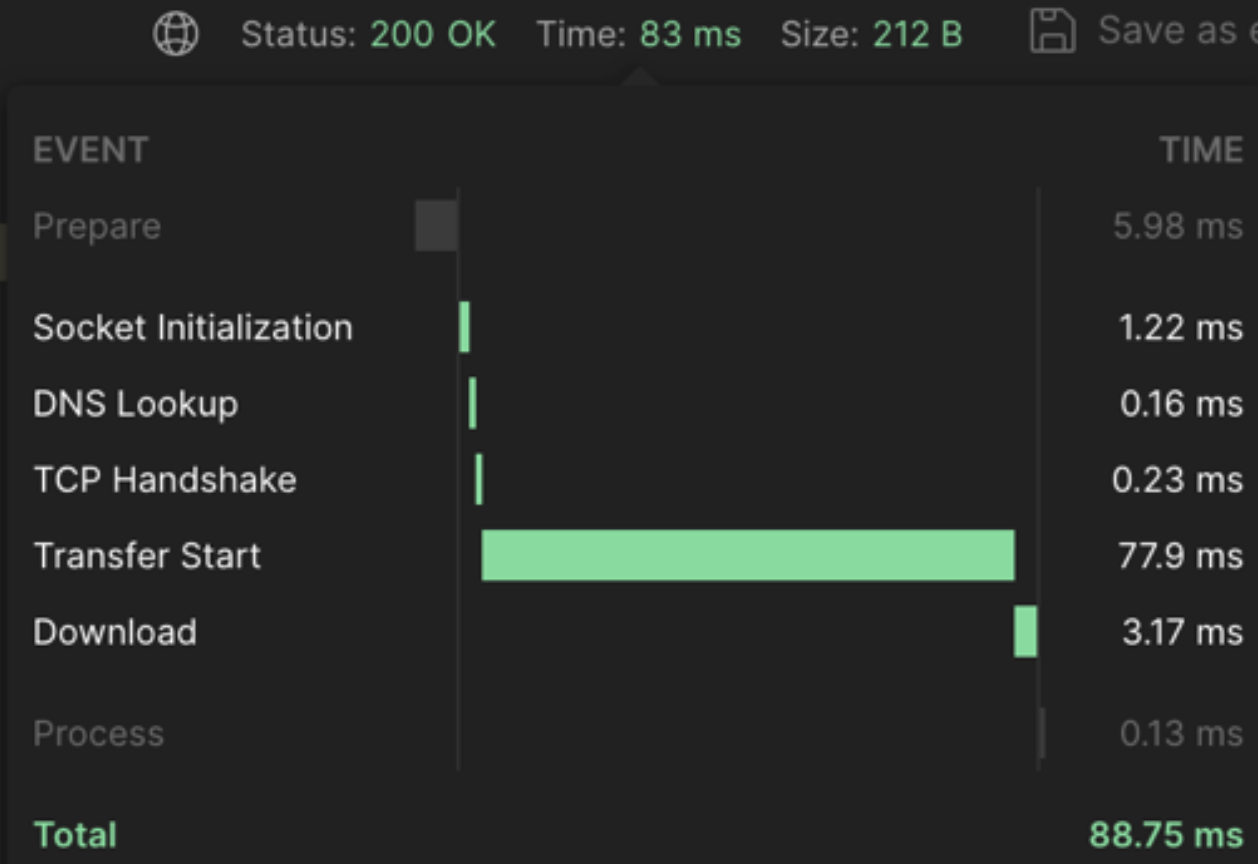 대략 88.75 ms가 걸린다.
대략 88.75 ms가 걸린다.
scan할 때 count 조정은 어떻게?
카페 메뉴가 1,000개가 넘을수는 없다고 생각하고 메뉴 갯수를 최대 1,000개라고 가정하고 시작했다. count를 100, 200, 400순으로 테스트 해본 결과 각각 200 ~ 400ms 사이에서 응답시간이 측정되었다. count=500으로 설정 시 80 ~ 100ms로 가장 적절한 count개수라고 판단되었다.
테스트 평균 수치 (메뉴 1000개 기준)
| count | AVG: 응답시간(ms) |
|---|---|
| 100 | 310 |
| 200 | 280 |
| 400 | 480 |
| 500 | 90 |
궁금점
Q. Redis key값들을 전부 가져와서 CompletableFuture를 사용하여, 여러 Redis 요청을 동시에 보내고 있지만 Redis 서버는 single thread event loop로 처리하면 CompletableFuture를 사용하는 이점이 없는건가?
A. 그렇지 않다. Redis는 싱글 스레드 모델을 사용하지만, 이는 Redis 서버 내부의 동작 방식에 관한 것이며, 비동기적으로 여러 요청을 보내는 것은 유의미하다.
비동기적으로 여러 요청을 보낼 때, 클라이언트는 다음 요청을 보내기 위해 이전 요청의 완료를 기다리지 않아도 된다. 즉, 첫 번째 요청을 보낸 후 그 요청의 응답을 기다리는 동안, 두 번째, 세 번째 요청 등을 계속해서 보낼 수 있다. 이렇게 함으로써, 네트워크 지연 시간을 최소화하고, 전체적인 처리 시간을 단축시킬 수 있다.
또한, CompletableFuture를 사용하면, 각각의 요청이 별도의 스레드(customThreadPool)에서 처리되므로, 한 요청이 오래 걸리더라도 다른 요청들의 처리가 지연되지 않아 시스템의 병렬성을 높이고, 전체적인 처리 성능을 향상시킬 수 있다.
결과
최종적으로 14배 → 42배 로 응답 시간이 단축됐다. 2번의 리팩토링 과정을 거쳐 유의미한 성능 개선이 이루어진 것 같다. RDB에서 캐싱 데이터의 key값으로 메뉴를 조회해야 하는 쿼리는 아직 미해결된 과제긴하다. 선제적으로 모든 데이터를 조회해 영속화하면 더 빠르지 않을까라는 생각이 든다.
