Visual SLAM/VSLAM
visual 정보를 사용하는 SLAM
장점
- 저렴한 센서를 사용
- 센서의 성능을 조절하기 쉬움(ex 렌즈교체 - 시야각, 초점 조절, 노출 시간)
- 이미지 기반 딥러닝 적용 가능 - Object detection / segmentation
- 이미지로 사람이 이해하기 쉬운 시각화 기능
단점
- 갑작스러운 빛 변화에 대응 불가능
- 시야가 가려지거나 어두운 곳에서 사용 불가능
Camera = Camera device + Lens
Camera configuration
- RGB camera
- Grayscale camera
- Multi-spectral camera
- Polarized camera
- Event camera
Lensconfiguration
- Perspective camera
- Wide FOV camera
- Telecentric camera
- Fisheye camera
- 360 degree camera
Type of camera configuration
- Monocular camera - 1 camera
- Stereo camera - 2 camera/Multi camera - N cameras
- RGB-D camera(Depth camera)
Monocular VSLAM
특징
- 1대의 카메라에서만 이미지를 받음
- (연구용 알고리즘이라는 인식이 있음)
장점
- Stereo / Multi camera VSLAM 보다 저렴함 (센서 가격, 전력 소비량, 이미지 데이터 송수신 대역폭)
단점
- Scale ambiguity - 3D 공간을 실제 스케일로 추정할 수가 없다(up-to-scale 로만 추정 가능)
- 이 문제를 풀기 위해선 metric scale을 가진 proprioceptive sensor가 필요
- 최근 딥러닝 기반 monocular depth estimation으로 문제를 해결하려는 시도가 있음

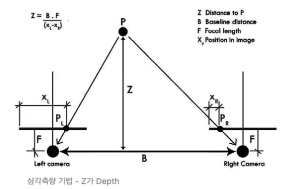
Stereo / Multi camera VSLAM
특징
- Stereo - 2대의 카메라를 사용
- Multi-camera - N대의 카메라 사용
- 민첩한 카메라들간의 baseline 거리를 이용하여 삼각측량을 통해 거리/길이 추정 가능
장점
- 두 이미지 간의 disparity 정보를 이용해서 픽셀마다 depth를 추정할 수 있음
- Metric scale의 3D 공간을 복원 가능
단점
- 카메라 설정 및 캘리 브레이션이 어려움
- 모든 카메라는 동시에 이미지를 취득해야함- Baseline이 충분히 길어야 먼 거리의 3D 공간을 정확하게 측정할 수 있음
- 카메라 들 마다 intrunsic/Extrinsic 캘리브레이션을 정확하게 해야함. 이 과정이 거의 불가능에 가깝기도 하다
- 모든 픽셀마다 disparity 정보로 depth를 계산하는데에는 많은 계산량이 필요하며 이를 위해 GPU나 FPGA 계산이 요구되기도 함

RGB-D VSLAM
Structured light(구조광), 또는 Time-of-Flight(ToF) 센서를 이용한 카메라를 사용
센서가 Depth 값을 직접 얻어주기 때문에 계산이 필요하지 않음
Dense mapping을 많이 하는 편
장점
- Depth 데이터를 통해 3D 공간을 metric scale로 실시간 복원 가능
단점
- ~10m 정도에서만 depth 데이터가 정확함
- Field of view가 작용
- 실외에서 사용 불가(적외선 파장이 햇빛과 간섭)

LIDAR SLAM
LIDAR 정보를 이용한는 SLAM
Exteroceptive senso = LIDAR
RADAR SLAM
RADAR 정보를 이용하는 SLAM
Exteroceptive sensor = RADAR
