
손실 함수(Loss Function)
모델의 출력(예측값)이 정답(실제 값)과 얼마나 가까운지 측정하기 위해 사용하는 함수.
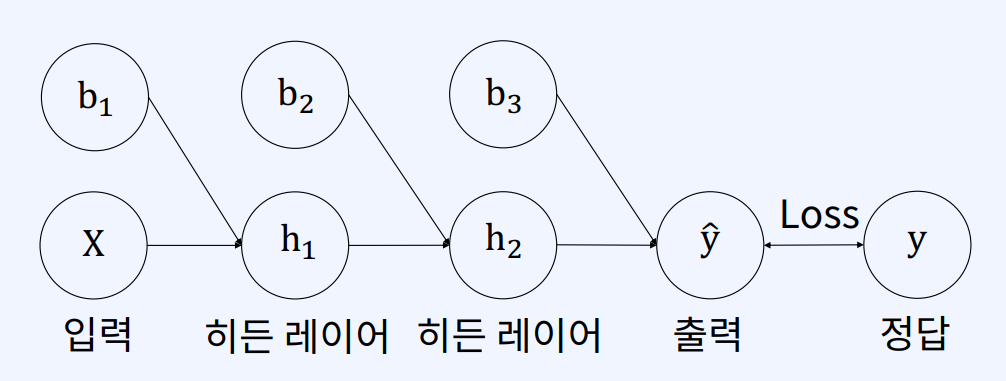
- 손실(모델의 출력 값과 실제 값 간의 차이)를 수치화 한다.
- 오차가 작을수록 손실 함수 값이 작다.
- 손실 함수 값이 작은 방향으로 모델을 학습시키는 것이 모델의 목표다.
- 회귀(Regression)/분류(Classification) 에 따라 사용하는 함수의 종류가 다르다.
1. 회귀(Regression)
(1) MAE (Mean Absolute Error, 평균 절대 오차)
 (y=0 일때)
(y=0 일때)
- 모든 데이터의 예측값()과 실제 값() 차이에 절대값을 취한 후 평균을 구한 값
- 이상치에 조금 덜 예민하다.
(2) MSE (Mean Squared Error, 평균 제곱 오차)
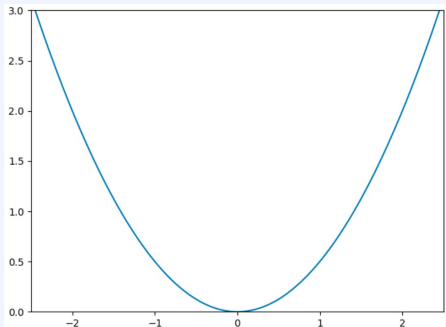 (y=0 일때)
(y=0 일때)
- 모든 데이터의 예측값()과 실제 값() 차이에 제곱을 취한 후 평균을 구한 값
- 차이의 제곱을 취한 값이기 때문에 이상치에 예민하다.
- 오차가 커질수록 손실 함수(Loss Function)가 빠르게 증가한다.
2. 분류(Classification)
(1) Binary Cross-Entropy (이진 교차 엔트로피)
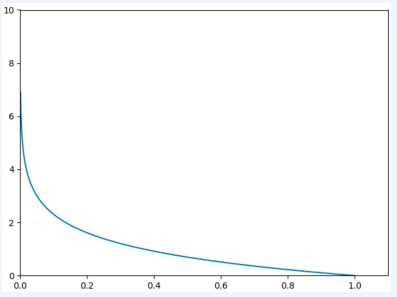 (y=1 일때)
(y=1 일때)
- 이진 분류 문제에서 사용한다.
- 이진 분류 문제이기 때문에, 일반적으로 (예측값)은 Sigmoid함수를 거친 0과 1 사이의 확률 값이다.
- 예측값이 1에 가까우면 True/양성 일 확률이 크고, 0에 가까우면 False/음성 일 확률이 크다.
(2) Categorical Cross-Entropy (범주 교차 엔트로피)
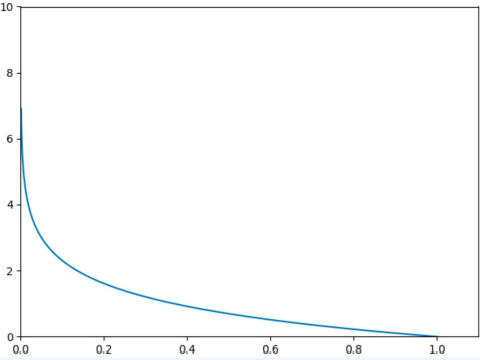 (y=1 일때)
(y=1 일때)
- class의 수가 3 이상인 분류에 사용한다.
- 때문에 (예측값)은 Softmax함수를 거친 0과 1 사이의 확률 값을 갖는다.
- 레이블()는 one-hot encoding 된 상태이다.
(one-hot encoding: 정답에 해당하는 class만 1이고 나머지는 class가 0)

데이터 분석으로 세상을 읽어보쟈 빠샤