
1. 활성화 함수(Activation Function) 란?
최종 출력값을 다음 레이어로 보낼지 말지를 결정하는 함수를 의미한다.
선형함수 vs 비선형 함수
| 선형 함수 | 비선형 함수 |
|---|---|
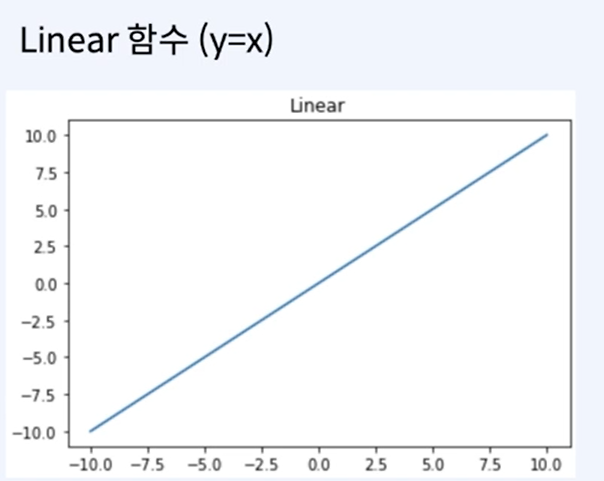 |  |
| 입력이 그대로 출력으로 나감 | 0과 1사이의 값을 가짐 |
| 네트워크를 쌓는 이점이 없어짐 | 네트워크를 쌓는 이점을 보존 |
| 선형 변환을 통해 다시 꼴로 변환 가능 |
선형 함수의 경우 위와 같이 다시 꼴로 변환 가능하기 때문에, 레이어를 쌓는 이점이 사라진다.
따라서 선형 함수는 일반적으로 뉴럴네트워크에서 활성화 함수로 사용되지 않는다.
즉, 뉴럴 네트워크에서 층을 쌓는것의 효과를 보기 위해서 비선형 함수를 활성화 함수로 사용한다.
2. 활성화 함수의 종류
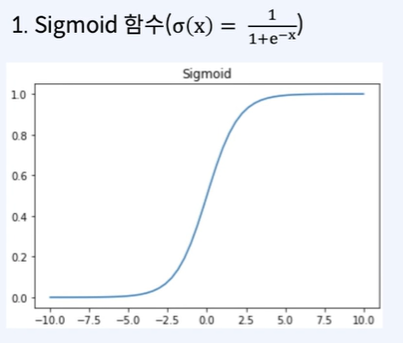
(1) Sigmoid
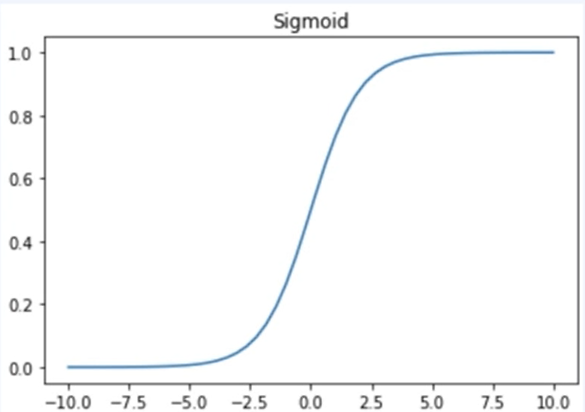
- Logistic Function
- 중심이 0.5이며, 0과 1사이의 값을 갖는다.
- gradient vanishing문제로 인해, 히든 레이어 보다는 출력 레이어에서 사용한다.
- 2개의 카테고리를 예측하는 경우에 사용한다.
(2) Tanh

- 중심이 0이며, -1과 1 사이의 값을 갖는다.
(3) ReLU
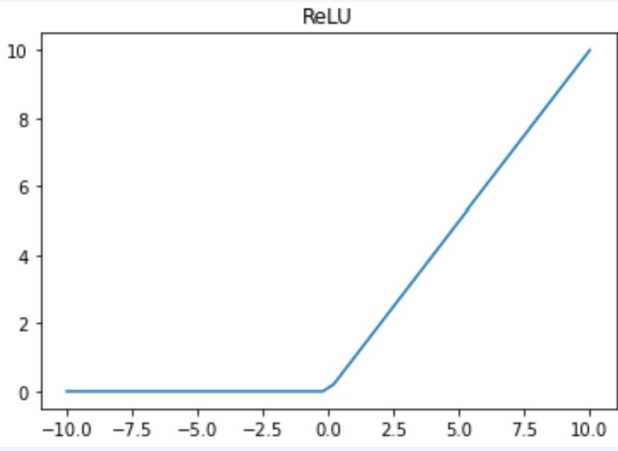
- 0보다 작은 값은 0으로, 0보다 큰 값은 그대로 값을 취한다.
- Sigmoid나 tanh보다 학습이 빠르다.
- 가장 많이 사용된다.
(4) LeakyReLU
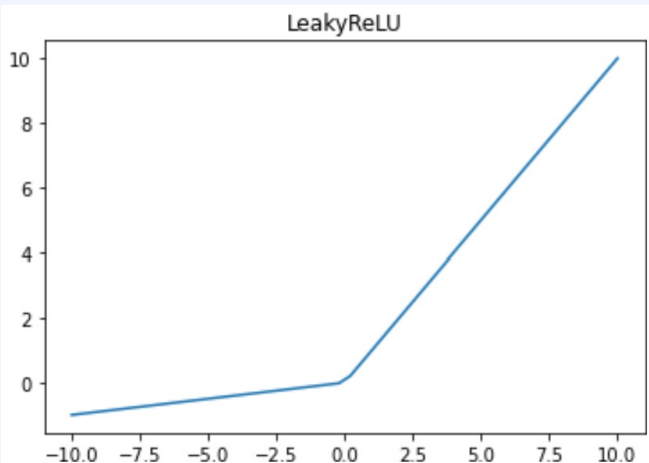
- x가 음수일 때 미분값이 0이 되는 ReLU를 변형하여 약간의 미분값을 갖게 만듦ㄴ
(5) Softmax
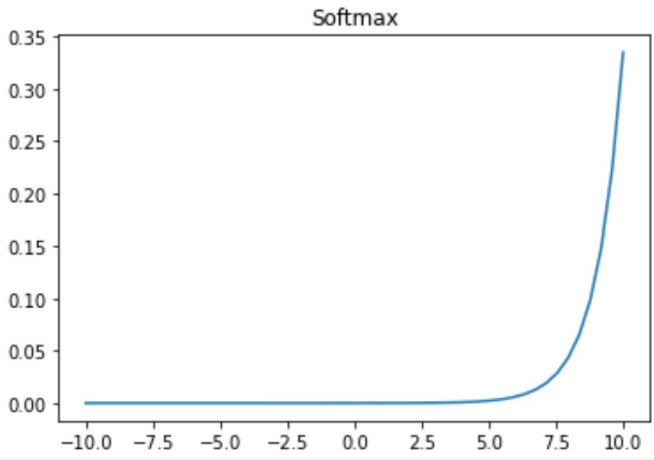
- 주로 마지막 레이어에서 class 분류를 하기 위해 사용된다.
- 입력값을 0~1 사이의 값으로 정규화 하여 합이 1인 확률분포로 만든다.

데이터 분석으로 세상을 읽어보쟈 빠샤