도전주제
제공된 데이터셋을 분석하여 도전 주제에 맞춘 비전 기술을 개발하라!
챌린지 배경
- 명함 관리 전문 서비스를 운영하고 있는 A사에서는 기존에 카메라로만 등록 처리했던 명함 이미지 서비스를 확장할 계획을 세우고 있습니다.
- 기존에 사용자들이 촬영해 둔 명함 이미지도 불러와 인식할 수 있도록 만드는 것이 새로운 서비스의 목표입니다.
- 하지만 기존 촬영본의 경우 이미지 크기, 방향, 배경과의 대비, 조명 등 다양한 환경 조건으로 인해 일관된 OCR 적용이 어려운 상황입니다.
- 따라서 다양한 조건으로 촬영된 주어진 명함 이미지들을 자동으로 전처리해 OCR을 적용하는 코드를 작성해야 해야 합니다.
데이터셋
images.zip: 다양한 조건에서 촬영된 명함 이미지 36장
데이터 분석
데이터로는 명함이미지 36장이 주어졌는데, 이미지들의 특성이 각각 제각각이었다. 어떤 이미지는 거꾸로 찍힌 이미지도 있었고 어떤 이미지는 명함이 잘려서 찍힌 이미지도 있었고, 또 어떤 이미지는 여러 명함이 동시에 찍힌 이미지도 있었다.
이러한 상황에서 명함의 네 모서리를 정확히 탐지해서 투시변환하는 작업이 어렵다고 생각했고, 직접 수동으로 OCR을 진행할 부분을 지정하는게 좋겠다고 생각했다.
따라서 마우스 이벤트를 이용해 명함 이미지를 띄운 후 OCR을 진행할 꼭짓점 네 군데를 지정하는 방식으로 진행했다.
# 마우스 클릭 이벤트 콜백 함수
def mouse_callback(event, x, y, flags, param):
# 마우스 왼쪽 버튼을 클릭할 때
if event == cv.EVENT_LBUTTONDOWN:
if len(coords) == 0:
print(f"좌상단: ({x}, {y})")
coords.append((x, y))
elif len(coords) == 1:
print(f"우상단: ({x}, {y})")
coords.append((x, y))
elif len(coords) == 2:
print(f"좌하단: ({x}, {y})")
coords.append((x, y))
elif len(coords) == 3:
print(f"우하단: ({x}, {y})")
coords.append((x, y))
# 좌표가 4개가 되면
if len(coords) == 4:
# 종료
cv.destroyAllWindows()
이런식으로 클릭할 때마다 해당 좌표가 출력되는 방식으로 구성했다.
프로그램을 실행할 때 OCR을 진행할 이미지 파일을 두번째 인자로 주는 방법을 선택했고, 좌표를 지정한 후 해당 좌표로 명함 비율에 맞춰 투시변환을 진행했다.
투시변환 이후 그레이 스케일 변환, 가우시안 블러링, 가우시안 쓰레쉬홀딩 및 침슥과정을 진행해 글자를 더욱 선명하게 만들고 테서랙트 OCR을 이용해서 변환 진행하였다.
# 이미지 투시 변환
pts1 = np.float32([coords[0], coords[1], coords[2], coords[3]])
# 해당 좌표로 투시변환 가로 세로 90:50 비율로
pts2 = np.float32([[0, 0], [900, 0], [0, 500], [900, 500]])
m = cv.getPerspectiveTransform(pts1, pts2)
card_image = cv.warpPerspective(img_resized, m, (900, 500))
# to gray scale
gray = cv.cvtColor(card_image, cv.COLOR_BGR2GRAY)
# apply gaussian blur
blurred = cv.GaussianBlur(gray, (3, 3), 0)
# adaptive thresholding
thresh = cv.adaptiveThreshold(blurred, 255, cv.ADAPTIVE_THRESH_GAUSSIAN_C, cv.THRESH_BINARY, 9, 5)
# erode
kernel = np.ones((1, 3), np.uint8)
erode = cv.erode(thresh, kernel, iterations=1)
# OCR 수행
options = "-l kor+eng --oem 3 --psm 6"
text = pyt.image_to_string(erode, config=options)
# output
print(text)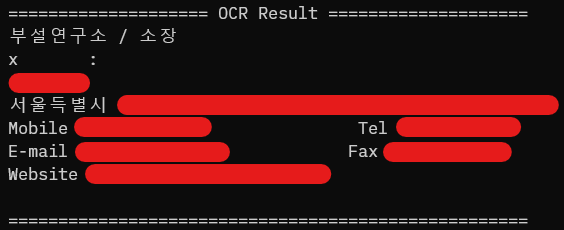
다음과 같이 OCR이 잘 진행되었음을 볼 수 있다.
하지만 이러한 방식의 파이프라인의 한계점은 명확한데, 명함의 비율로 고정 변환을 하기 때문에 한장에 명함 여러징이 있는 경우 해당 명함들의 배치가 리사이즈 비율과 맞지 않다면 한번에 여러장을 처리할 수 없고 해당 이미지 한장을 처리하기 위해 이미지 내의 명함 개수만큼 프로그램을 실행해야 한다는 단점이 있다.
