2023.11.03,05 TIL
Machine Learning 개요
Training
- 모델을 학습 시키는 과정
- 데이터를 수집, 전처리
- 모델의 구조와 파라미터 정의
- 예측값과 정답 간의 차이를 최소화
- 최적화 과정 이 끝나면 가중치 저장
Inferencing / Serving
- 새로운 입력에 대해 예측값 생성
- 모델의 어떤것도 수정하지 않음
Model을 서빙하는 방법들
- 클라우드에서 실행 후, 결과만 받아오기
- 다른곳에서 training한 model을 임베디드 장치에서 실행 (보통 이거)
경량화 기술
- Data Blurring
Object Detection
CNN - Convolutional Neural Network
Input : Matrix data
컴퓨터가 계산을 통해 특징점을 뽑아내는 과정 → 특징점들을 기준으로 classification
Model
Single Shot multibox Detector
SSD-mobilenet-v3
- 비교적 빠르고 정확한 모델
- RPN(Region Proposal Network)
- image 내에서 object가 존재할만한 영역 추출
- object 검출
- 이걸 1단계로 줄인것 (single shot!) → 여러개의 특징점을 만들고, confidential score와 NMS를 사용해 최종 검출
Data
COCO(Common Objects in Context) dataset
- Huge image dataset
- 연구에서 많이 사용돼용
Weight
COCO dataset → 특징 training 통해 weight 생성
coco.names → Data label
frozen_inference_graph.pb → Model + Weight 합쳐져있음
ssd_mobilenet_v3_large_coco_2020_01_14.pbtxt → config
import 해보기
import cv2
import time64bit로 재설치했다면 opencv 다시 설치 (지난 강의 참고)
Linux의 swap system 크기 늘리기
메모리가 모자라면 disk를 이용해 메모리처럼 쓸 수 있는 기술
Disk에 임시로 저정하고 메모리 공간 확보하는 방식
(단점: 느림, emergency 상황에서 실행)
sudo dphys-swapfile swapoff
sudo vi /etc/dphys-swapfile → CONF_SWAPSIZE, CONF_MAXSWAP 변경
sudo dphys-swapfile setup
sudo dphys-swapfile swapon
htop 으로 확인가능 → Swp[ ] 맨끝에 숫자
(ex: CONF_SWAPSIZE=8096 : 8GB)
import cv2
import time
import argparse
# 클래스 이름을 저장할 리스트 초기화
classNames = []
# 클래스 이름이 저장된 파일 읽어오기
classFile = "coco.names"
with open(classFile, "rt") as f:
classNames = f.read().rstrip("\n").split("\n")
# Model, Weight 로드
configPath = "ssd_mobilenet_v3_large_coco_2020_01_14.pbtxt"
weightsPath = "frozen_inference_graph.pb"
net = cv2.dnn_DetectionModel(weightsPath, configPath) # Detection model을 opencv에서 사용하기 위한 wrapper
# Model에 들어가는 input image size와 parameter 설정
net.setInputSize(320, 320) # training된 model input size
net.setInputScale(1.0/ 127.5) # scale up, down
net.setInputMean((127.5, 127.5, 127.5))
net.setInputSwapRB(True) # BGR 을 RGB로 바꾸는것. grayscale 할때 BGR이었는데 이 순서롤 바꿔줘야함.
# 객체 검출 함수
def getObjects(img, thres, nms, draw=True, objects=[]): # Monitor에 연결되어있지 않다면 draw=False
classIds, confs, bbox = net.detect(img, confThreshold=thres, nmsThreshold=nms) # confThreshold와 nmsThreshold로 최종 검출
if len(objects) == 0: # 예측해야될 model들의 실제 classname으로 입력
objects = classNames
objectInfo = []
if len(classIds) != 0:
for classId, confidence, box in zip(classIds.flatten(), confs.flatten(), bbox):
className = classNames[classId - 1]
if className in objects:
objectInfo.append([box, className])
if draw:
cv2.rectangle(img, box, color=(0, 255, 0), thickness=2)
cv2.putText(img, classNames[classId-1].upper(), (box[0]+10, box[1]+30),
cv2.FONT_HERSHEY_COMPLEX, 1, (0, 255, 0), 2)
cv2.putText(img, str(round(confidence*100, 2)), (box[0]+200, box[1]+30),
cv2.FONT_HERSHEY_COMPLEX, 1, (0, 255, 0), 2)
return img, objectInfo # img에 draw할게 있다면 그려서 리턴, img에서 찾아낸 object info 리턴
if __name__ == "__main__":
# 명령행 인수 처리
# $ python3 object_detection.py --thres 0.1 --nms 0.1 처럼 실행할때 parameter 전달하는거
parser = argparse.ArgumentParser()
parser.add_argument("--thres", type=float, default=0.45, help="Confidence threshold for object detection")
parser.add_argument("--nms", type=float, default=0.2, help="NMS threshold for object detection")
args = parser.parse_args()
# 비디오 캡처 객체 생성
cap = cv2.VideoCapture(0)
# 해상도를 (640, 640)으로 설정. 우리가 쓰는 input은 (320, 320)임.. 어떻게 최적화할지..
cap.set(3, 640)
cap.set(4, 480)
# 반복문을 이용한 객체 검출 시간 측정
iterations = 10
avg = []
while iterations > 0:
start = time.time()
success, img = cap.read()
result, objectInfo = getObjects(img, args.thres, args.nms)
end = time.time()
loopTime = end - start
print("thres={}, nms={}, each={}".format(args.thres, args.nms, loopTime)) # image 하나 찾을때마다 걸린 시간 정보 출력
cv2.imshow("Output",img) # Monitor에 연결되어있는 경우에만 써줘야함
cv2.waitKey(1)
iterations -= 1
avg.append(loopTime)
print("thres={}, nms={}, avg={}".format(args.thres, args.nms, sum(avg) / len(avg)))Gesture Recognition
여러장의 image를 연속으로 계산하여, 현재 object가 어떤식으로 움직이고 있는지 확인하는 방법
Input image에서 object를 찾고, 그 object의 특징점들의 움직임•형태에서 의미를 코드로 추출한다.
임베디드 시스템에서 최적화 없이 가용되기는 힘들다.
다른 고수분들/다른 회사가 최적화해놓은 프레임워크를 쓰자 (그래도 느리김함)
MediaPipe
Google에서 개발한 오픈소스 framework
개발한 이유:
Model을 연구했는데 서비스에 넣으려니 리소스가 부족했다
경량화, 다양한 플랫폼 지원도 부족했다.
다양한 Library
- Object Detection
- Image classification
- Hand gesture recognition
- Hand Landmark
- Pose Detection
- Image Embedding
- Image를 data화시키는! 대박
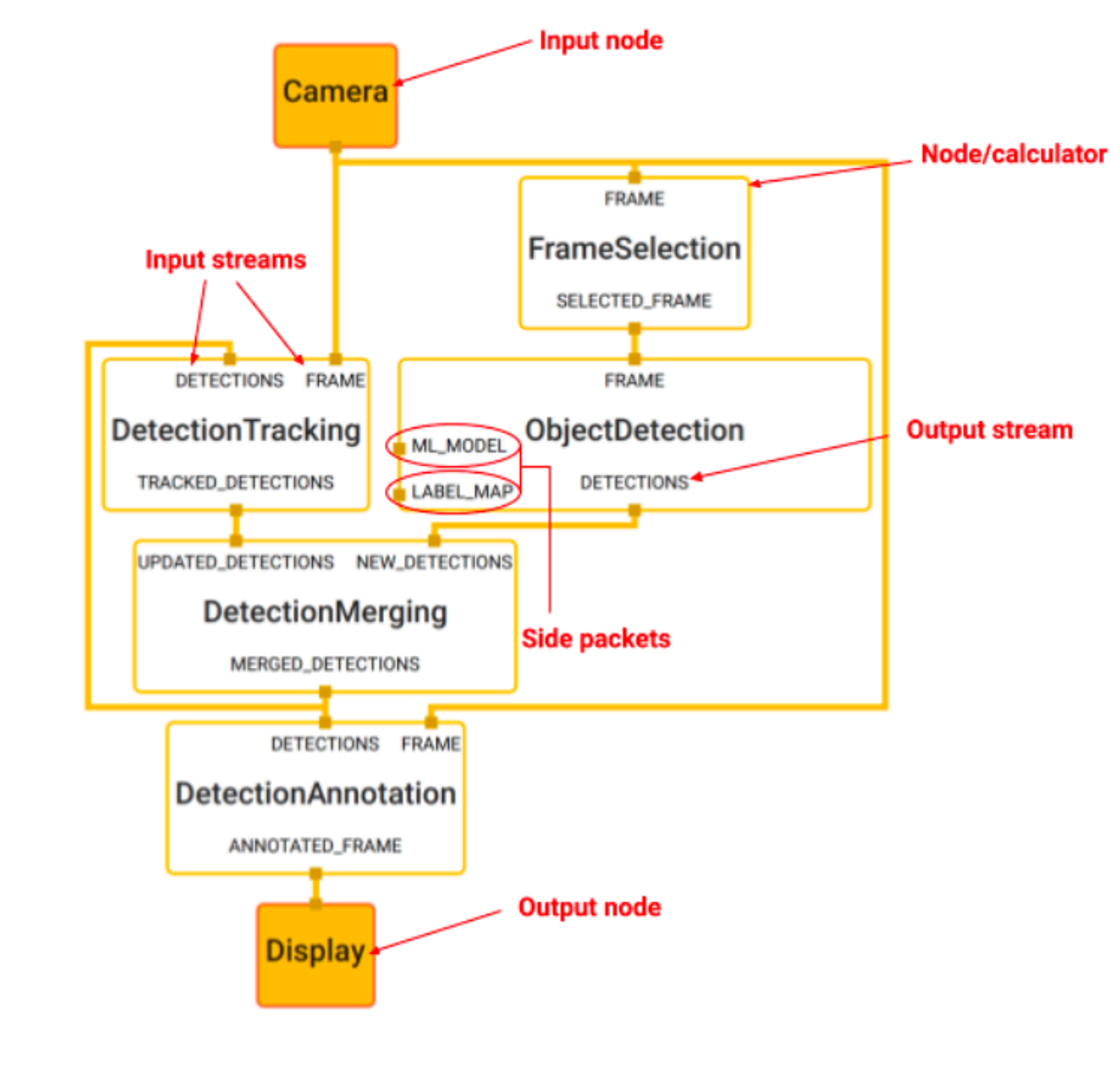
우리가 각 component들의 흐름 지정 가능
- Node : 유저가 정의한 행동을 하는 모듈 (로직을 지정할수있음)
- Calculator : 유저가 정의한 계산을 하는 모듈 (frame을 filtering 등)
- Stream : 계속해서 진행되는 데이터 (모든 노란색 선)
- Packet : 주고 받는 데이터 타입
Hand Gesture Recognition Program 구현하기
Package 설치
$ pip3 install mediapipe
(선택) $ pip3 install --force-reinstall protobuf==3.20.1 → downgrade protobuf
>>> import mediapipe
LED Dimming 구현
PWM(Pulse-Width Modulation) → 일정 주기내에서 전압이 올라가는 비율을 변경(ex: 0.25 per 1)
import RPi.GPIO as GPIO
import time
def led_dimming(led, duration, pwm_frequency=100): # pwm_frequency: 1초에 진동하는 횟수
pwm = GPIO.PWM(led, pwm_frequency) # 이 pin에서 PWM을 사용하겠다
try:
pwm.start(0)
for _ in range(int(duration * pwm_frequency)):
# 밝아지는 과정
for duty_cycle in range(0, 101, 5): # duty_cylcle: 한 주기동안 신호가 on 되어있는 비율. 0부터 5씩 높여준다
pwm.ChangeDutyCycle(duty_cycle)
time.sleep(1 / (pwm_frequency * 2))
# 어두워지는 과정
for duty_cycle in range(100, -1, -5):
pwm.ChangeDutyCycle(duty_cycle)
time.sleep(1 / (pwm_frequency * 2))
finally:
pwm.stop()
GPIO.setmode(GPIO.BCM) # Pinmap 모드 설정
led_pin = 2
GPIO.setup(led_pin, GPIO.OUT) # 2번 pin을 출력으로 사용
led_dimming(led_pin, 5)
GPIO.cleanup() # 다쓰고 정리Gesture Recognition 구현
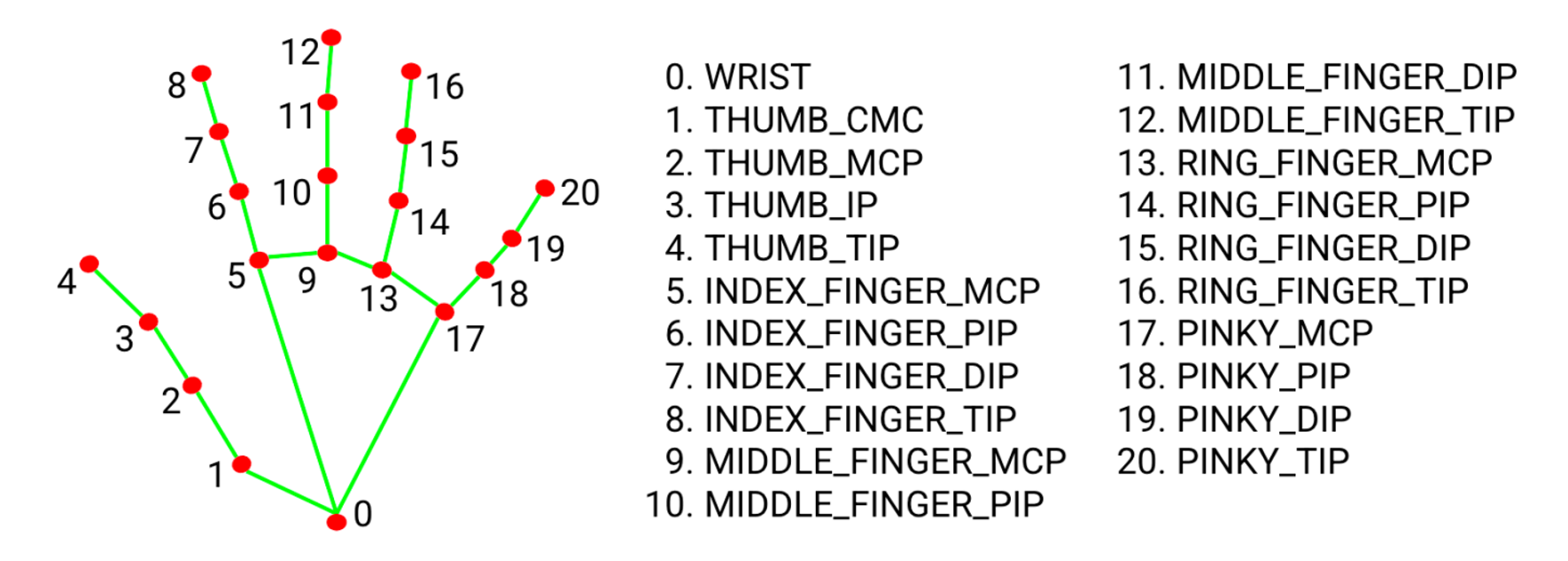
- BlazePalm model을 통한 손 위치 감지
- 손에서 hand landmark model 로 landmark 추출
- 출력된 landmark를 기준으로 gesture 탐지
import cv2
import mediapipe as mp
import time
mp_drawing = mp.solutions.drawing_utils
mp_hands = mp.solutions.hands위로 솟은 손가락 갯수 세기
손가락의 두번째 관절(DIP)보다 손끝(TIP)이 위에 있다면 손가락이 솟은것!
Ok sign 감지하기
4번이 3번보다 위에, 6번이 8번보다 위에 있다면 Ok sign이 만들어진것!
Transformer Model
Encoder-Decoder 구조
Embedding이 된 data를 model에 통과시켜서 결과를 decode
LLAMA (Large Language Model Meta AI)
Meta에서 만든 model
Raspberry Pi에서 써보기
- 적당한 곳에 alpaca.cpp GitHub repo clone
git clone https://github.com/antimatter15/alpaca.cpp
- 빌드 툴 확인
sudo apt-get install cmake
- 다운받은 weight 파일을 alpaca.cpp 폴더 안으로 옮기기
- 컴파일
make chat
- 매우 오래걸림. 그러나 돌아간다.
