
■ 관련 내용 : (EDA) 서울시 범죄 현황 데이터 분석
Visualization
범죄별 연관성
- 5대 범죄 중
강도,살인,폭력간 관계를 확인
sns.pairplot(crime_anal_norm, vars=['강도','살인','폭력'], kind = 'reg')
plt.show()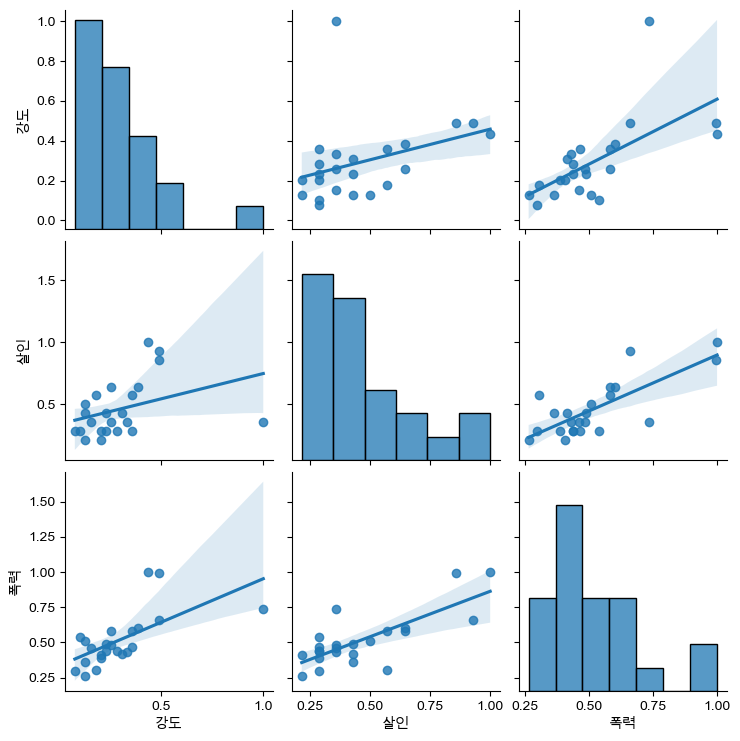
CCTV 설치와 인구수에 따른 범죄별 연관성
- CCTV 설치 갯수 및 인구수와 범죄(살인, 강도) 간 연관성 확인
def drawPlot():
sns.pairplot(
crime_anal_norm,
x_vars=['인구수', 'CCTV'],
y_vars=['살인','강도'],
kind = 'reg')
plt.show()
drawPlot()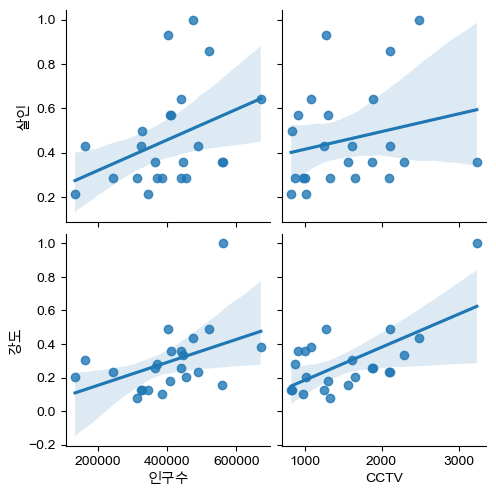
- CCTV 설치 갯수 및 인구수와 범죄(폭력, 살인) 검거율 간 연관성 확인
def drawPlot():
sns.pairplot(
crime_anal_norm,
x_vars=['인구수', 'CCTV'],
y_vars=['살인검거율','폭력검거율'],
kind = 'reg')
plt.show()
drawPlot()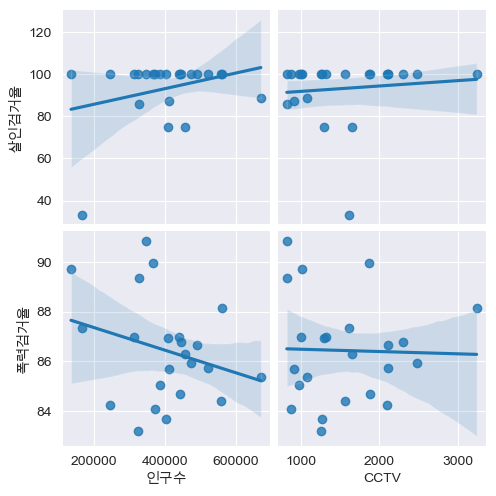
구별 범죄발생 및 검거
- 구별 범죄 검거율 시각화
def drawGraph():
target_col = ['강간검거율', '강도검거율', '살인검거율', '절도검거율', '폭력검거율', '검거']
crime_anal_norm_sort = crime_anal_norm.sort_values(by = '검거', ascending= False)
plt.figure(figsize = (10, 10))
sns.heatmap(
crime_anal_norm_sort[target_col],
annot = True,
fmt = 'f',
linewidths= 0.5,
cmap = 'RdPu'
)
plt.title('구별 범죄 검거율')
plt.show()
drawGraph()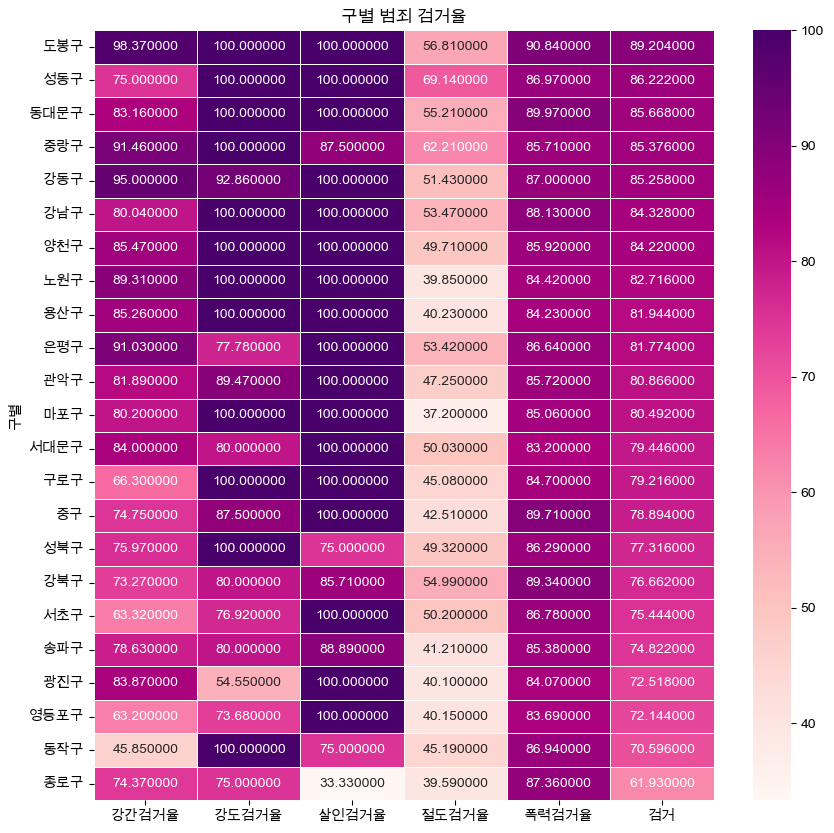
- 구별 평균 범죄 발생 건수 시각화
def drawGraph():
target_col = ['강간', '강도', '살인', '절도', '폭력', '범죄']
crime_anal_norm_sort = crime_anal_norm.sort_values(by = '범죄', ascending= False)
plt.figure(figsize = (10, 10))
sns.heatmap(
crime_anal_norm_sort[target_col],
annot = True,
fmt = 'f',
linewidths= 0.5,
cmap = 'RdPu'
)
plt.title('구별 범죄 발생 (정규화된 발생 건수의 값으로 정렬)')
plt.show()
drawGraph()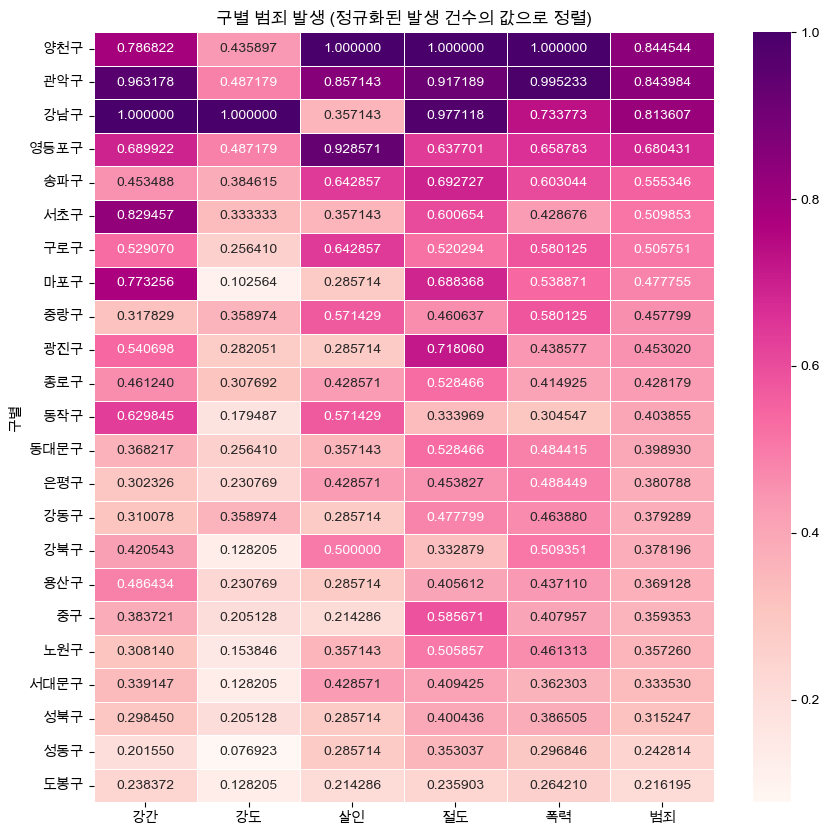
서울시 범죄율에 대한 지도 시각화
LoadPath
f_path = "/Users/min/Documents/ds_study/제로-베이스---데이터-사이언스-스쿨---강의자료---part-01---05--230120-/Part 04. EDA & Part 05. SQL/Part 04. EDA웹 크롤링파이썬 프로그래밍 - 강의자료/210923 - 02. Analysis Seoul Crime/data/"
my_path = '/Users/min/Documents/ds_study/' # 데이터 저장ModuleLoad
import folium
import json # 서울시 지역구별 좌표DataLoad
crime_anal_norm = pd.read_csv(my_path + '02.crime_anal_norm.csv', index_col = 0, encoding = 'utf-8')
geo_path = f_path + '02. skorea_municipalities_geo_simple.json'
geo_str = json.load(open(geo_path, encoding = 'utf-8'))
crime_anal_norm.head()- 서울특별시 지도 좌표 설정 및 불러오기
my_map = folium.Map(
location = [37.5502, 126.982],
zoom_start = 11,
tiles = 'Stamen Toner'
)
my_map
💡 ※ 지도에 검은색 배경으로 나타나는 이유
➣ folium 공식 문서에 의하면 choropleth 객체에 주게 되는 인자들 중 nan_fill_color는 디폴트로 검은색이 적용
- 정규화된
살인발생 건수를 지도에 시각화
folium.Choropleth(
geo_data = geo_str, # 우리나라 경계선 좌표값이 담긴 데이터
data = crime_anal_norm['살인'],
columns = [crime_anal_norm.index, crime_anal_norm['살인']],
key_on = 'feature.id',
fill_color = 'PuRd',
file_opacity = 0.7,
line_opacity = 0.2,
legend_name = '정규화된 살인 발생 건수'
).add_to(my_map)
my_map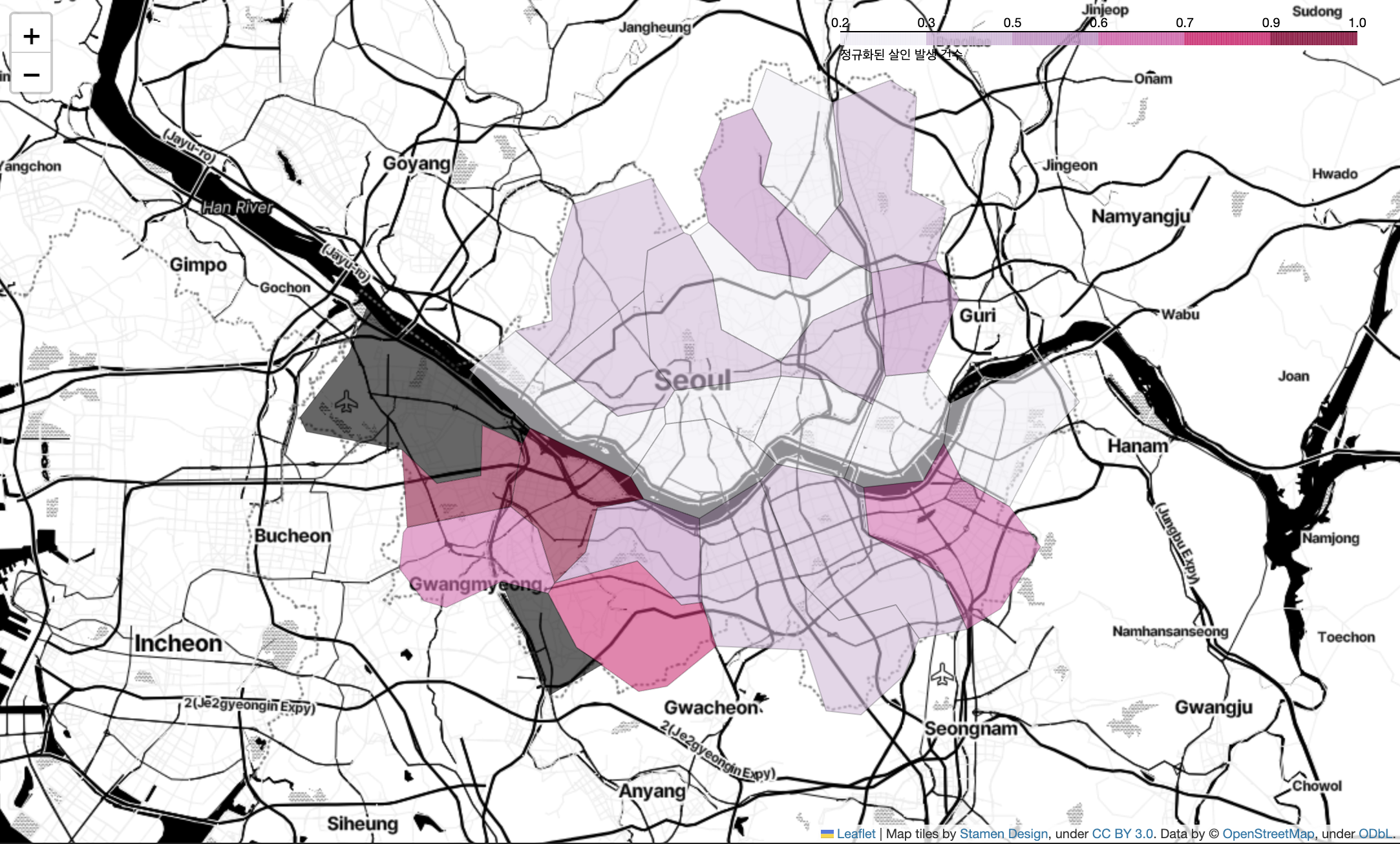
- 같은 방법으로, 정규화된 강간 발생 건수를 지도에 시각화
# 강간 범죄 발생 건수 시각화
my_map = folium.Map(
location = [37.5502, 126.982],
zoom_start = 11,
tiles = 'Stamen Toner'
)
folium.Choropleth(
geo_data = geo_str, # 우리나라 경계선 좌표값이 담긴 데이터
data = crime_anal_norm['살인'],
columns = [crime_anal_norm.index, crime_anal_norm['강간']],
key_on = 'feature.id',
fill_color = 'PuRd',
file_opacity = 0.7,
line_opacity = 0.2,
legend_name = '정규화된 강간 발생 건수'
).add_to(my_map)
my_map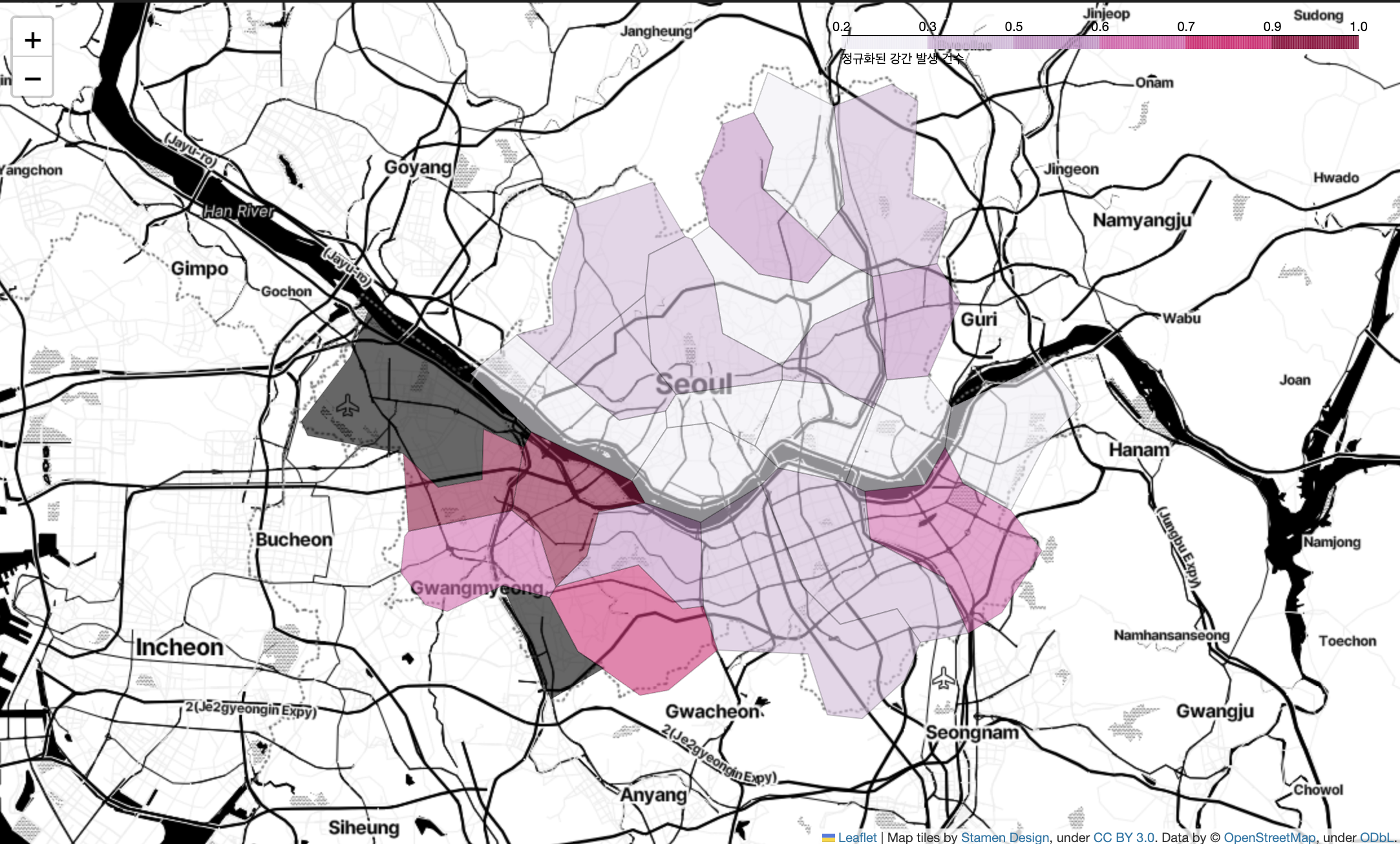
- 5대 범죄 발생 건수를 시각화
# 5대 범죄 발생 건수 지도 시각화
my_map = folium.Map(
location = [37.5502, 126.982],
zoom_start = 11,
tiles = 'Stamen Toner'
)
folium.Choropleth(
geo_data = geo_str, # 우리나라 경계선 좌표값이 담긴 데이터
data = crime_anal_norm['살인'],
columns = [crime_anal_norm.index, crime_anal_norm['범죄']],
key_on = 'feature.id',
fill_color = 'PuRd',
file_opacity = 0.7,
line_opacity = 0.2,
legend_name = '정규화된 5대 범죄 발생 건수'
).add_to(my_map)
my_map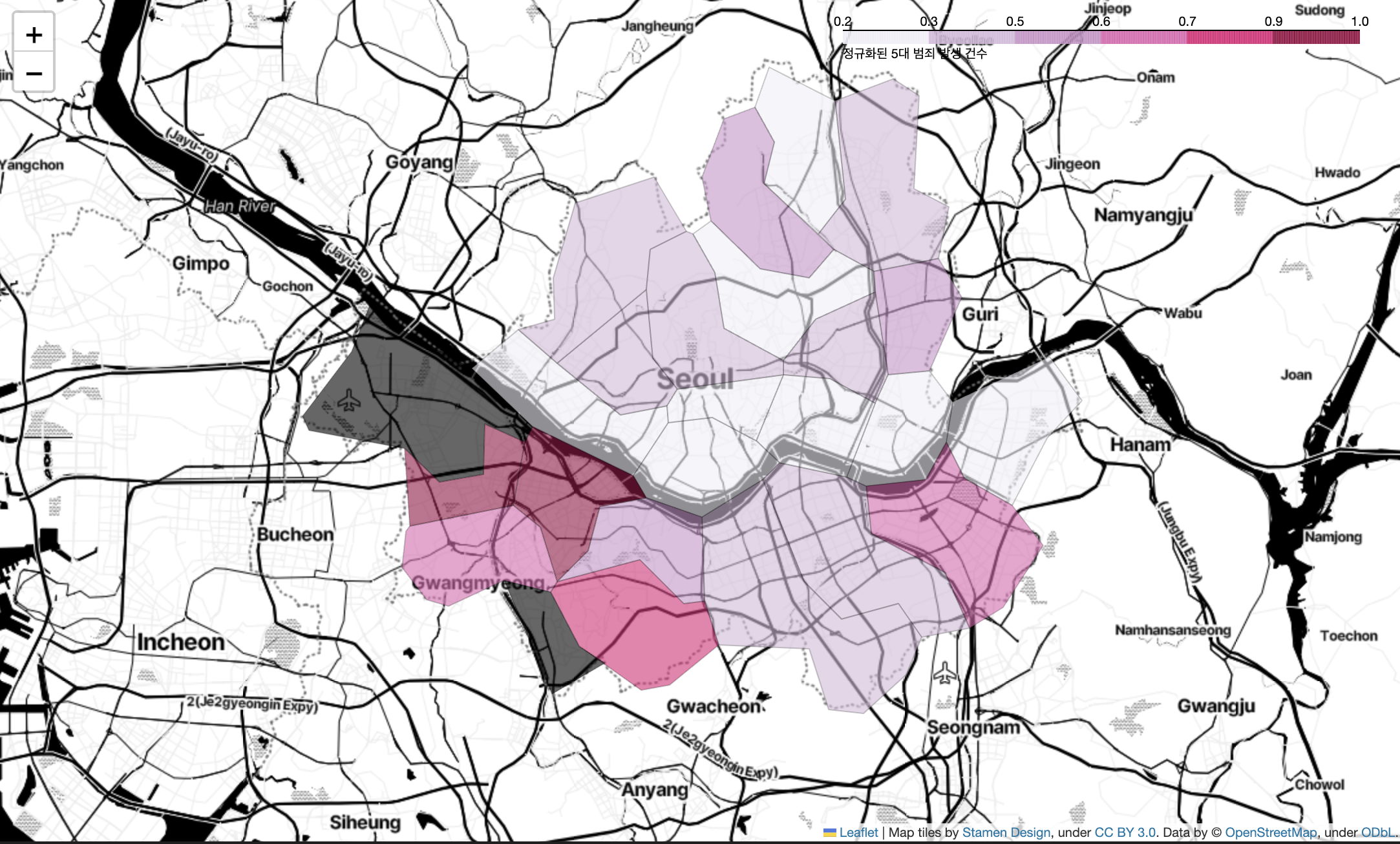
- 인구 대비 범죄 발생 건수 시각화
# 인구 대비 범죄 발생 건수 지도 시각화
tmp_criminal = crime_anal_norm['범죄'] / crime_anal_norm['인구수']
my_map = folium.Map(
location = [37.5502, 126.982],
zoom_start = 11,
tiles = 'Stamen Toner'
)
folium.Choropleth(
geo_data = geo_str, # 우리나라 경계선 좌표값이 담긴 데이터
data = crime_anal_norm['살인'],
columns = [crime_anal_norm.index, crime_anal_norm['범죄']],
key_on = 'feature.id',
fill_color = 'PuRd',
file_opacity = 0.7,
line_opacity = 0.2,
legend_name = '인구 대비 범죄 발생 건수'
).add_to(my_map)
my_map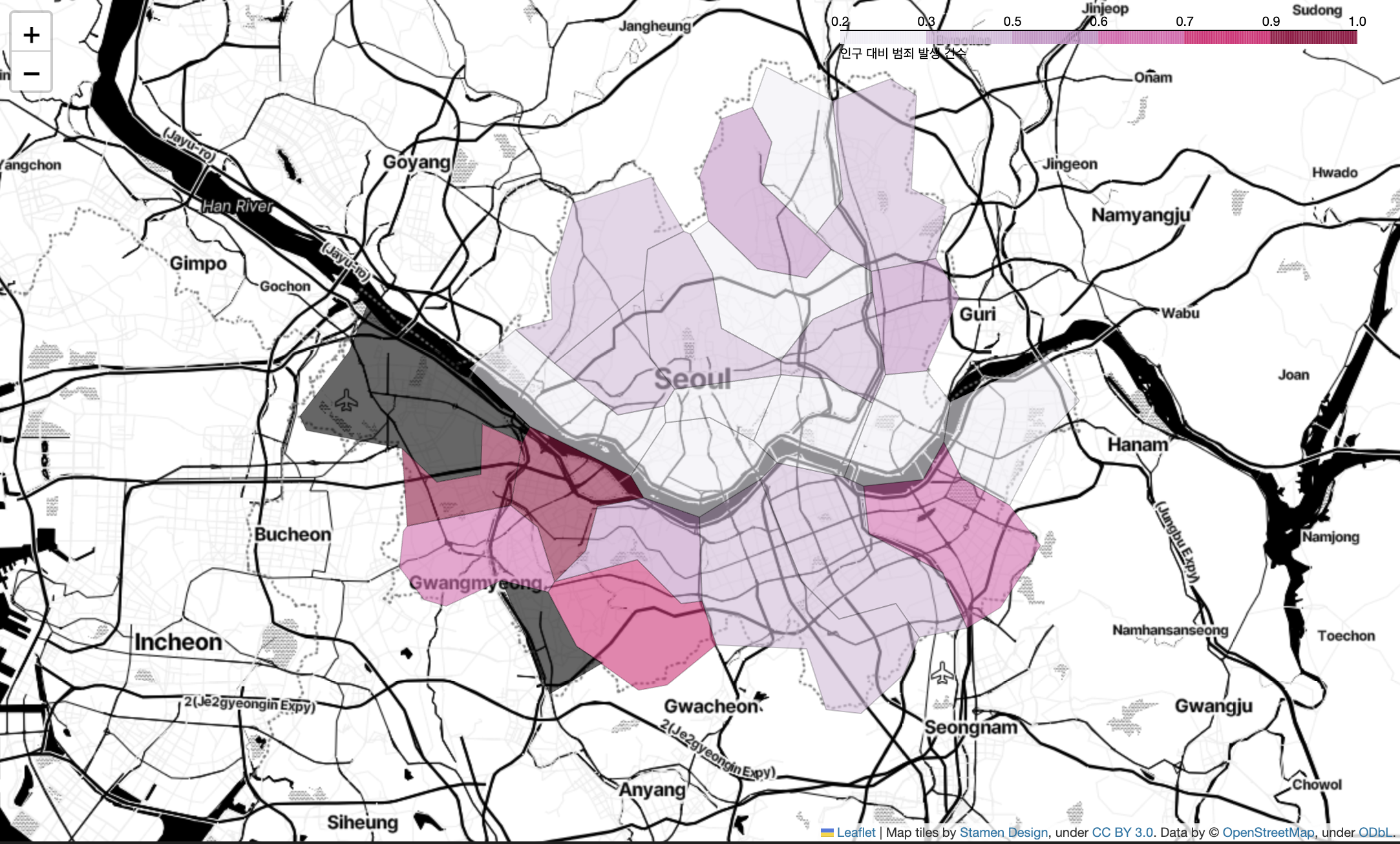
- 경찰서 정보를 범죄 발생 및 검거와 함께 표시하기 위해, 데이터프레임(DataFrame) 정리
# 경찰서별 정보를 범죄 발생과 함께 정리
crime_anal_station = pd.read_csv(
'/Users/min/Documents/ds_study/제로-베이스---데이터-사이언스-스쿨---강의자료---part-01---05--230120-/Part 04. EDA & Part 05. SQL/Part 04. EDA웹 크롤링파이썬 프로그래밍 - 강의자료/210923 - 02. Analysis Seoul Crime/data/02. crime_in_Seoul_raw.csv', encoding = 'utf-8'
)
crime_anal_station.tail()
- 모든 범죄에 대한
검거건수를 정규화(normalization)하여 평균으로 계산
col = ['살인검거', '강도검거', '강간검거', '절도검거', '폭력검거']
tmp = crime_anal_station[col] / crime_anal_station.max() #정규화 0 - 1
crime_anal_station['검거'] = np.mean(tmp, axis = 1) # numpy에서 axis = 1 : 행(가로) // pandas에서는 axis = 1 : 열(세로)
crime_anal_station.tail()
- 경찰서 위치 Marker 표시
my_map = folium.Map(
location = [37.5502, 126.982],
zoom_start = 11
)
for idx, rows in crime_anal_station.iterrows(): # 경찰서 위치 마커 표시
folium.Marker(
location = [rows['lat'], rows['lng']]
).add_to(my_map)
my_map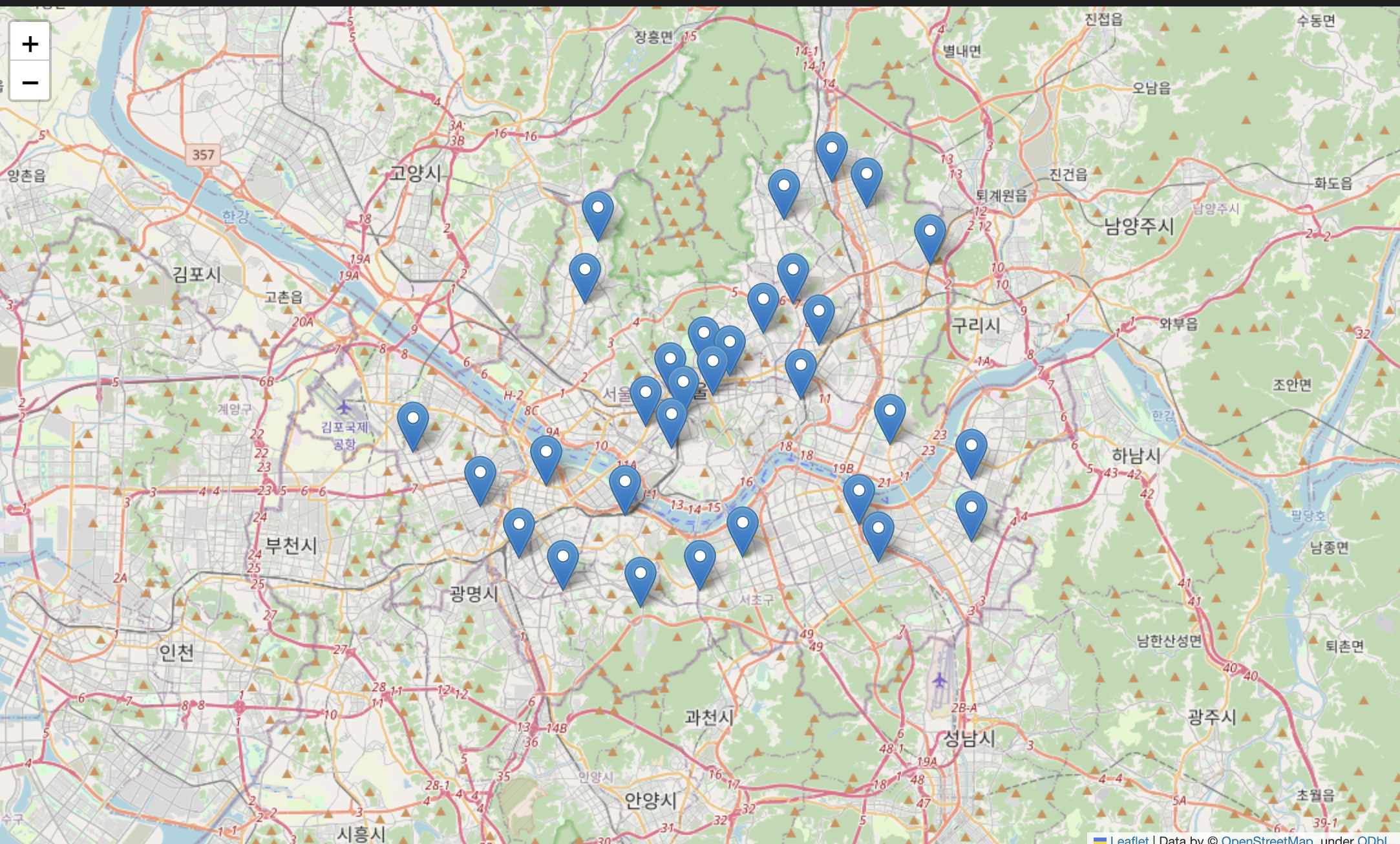
검거column에 값을 곱한 뒤, 원의 넓이 적용검거는 범죄 검거수를 기준으로 정규화(normalization) 되었으므로 검거 수가 높은 구를 표현하기 위함
my_map = folium.Map(
location = [37.5502, 126.982],
zoom_start = 11
)
folium.Choropleth(
geo_data = geo_str,
data = crime_anal_norm['범죄'],
columns = [crime_anal_norm.index, crime_anal_norm['범죄']],
key_on = 'feature.id',
fill_color = 'PuRd',
fill_opacity = 0.7,
line_opacity = 0.2
).add_to(my_map)
for idx, rows in crime_anal_station.iterrows(): # 검거에 값을 곱한 뒤 원의 넓이 적용
folium.CircleMarker(
location = [rows['lat'], rows['lng']],
radius = rows['검거'] * 50,
popup = rows['구분'] + ' : ' + '%.2f' % rows['검거'],
color = '#3186cc',
fill = True,
fill_color = '#3186cc'
).add_to(my_map)
my_map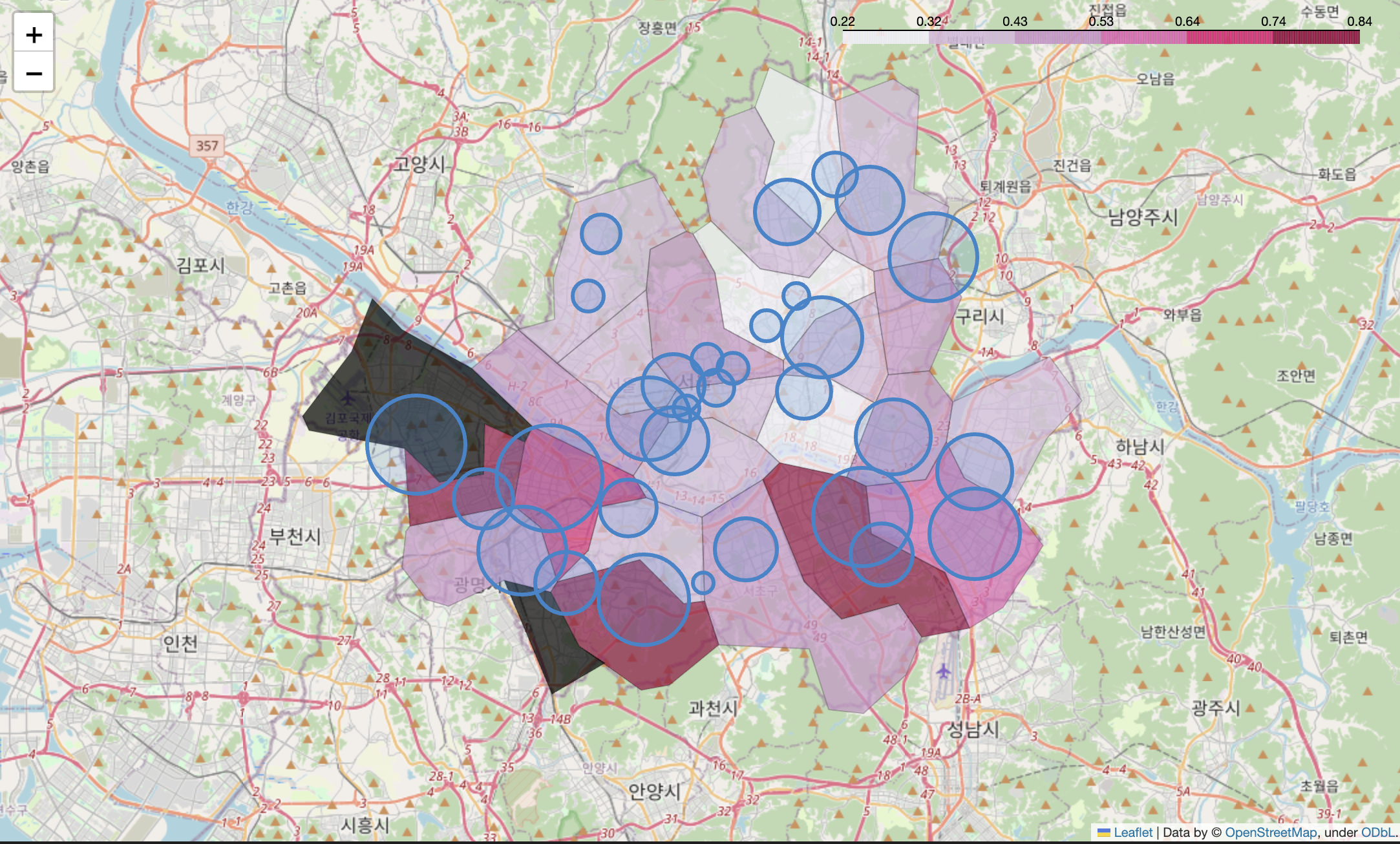
서울시 범죄현황 발생 장소 분석
DataLoad
crime_loc_raw = pd.read_csv(
f_path + '02. crime_in_Seoul_location.csv', thousands = ',', encoding = 'euc-kr'
)
crime_loc_raw.tail()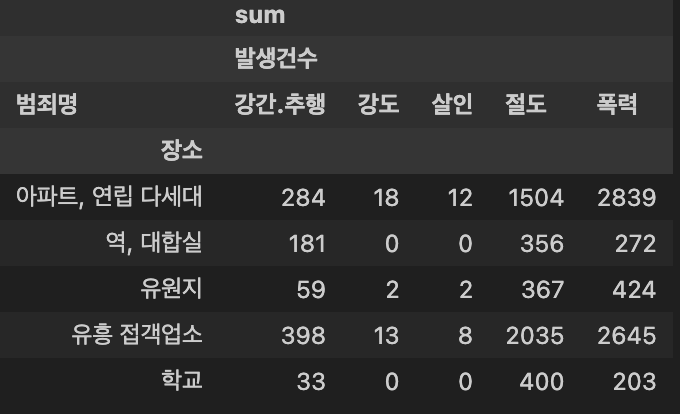
- 범죄 발생 장소 확인
crime_loc_raw['장소'].unique()Output :
array(['아파트, 연립 다세대', '단독주택', '노상', '상점', '숙박업소, 목욕탕', '유흥 접객업소', '사무실','역, 대합실', '교통수단', '유원지 ', '학교', '금융기관', '기타'], dtype=object)
- 범죄 발생 장소를 기준으로 각 범죄 발생 건수 합계를 계산
- 계산 후,
droplevel()을 사용해 불필요 column 제거
- 계산 후,
crime_loc = crime_loc_raw.pivot_table(
crime_loc_raw,
index = '장소',
columns = '범죄명',
aggfunc = [np.sum]
)
crime_loc.tail()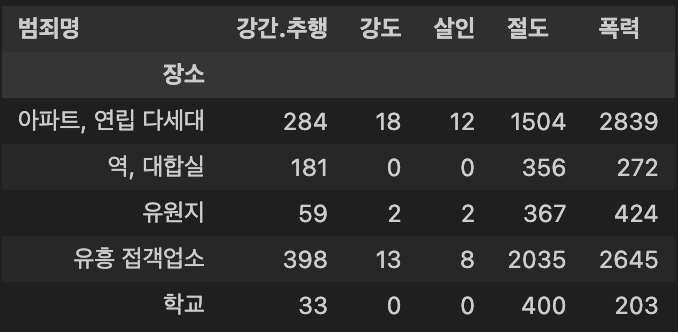
crime_loc.columns = crime_loc.columns.droplevel([0, 1])
crime_loc.tail()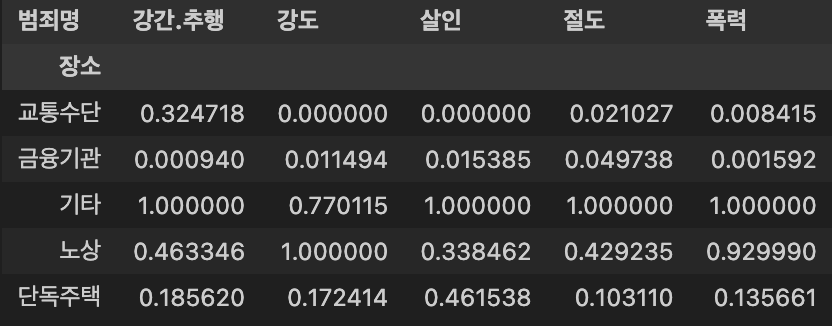
- 각 범죄별 건수에 대한 정규화 진행
crime_loc_norm = crime_loc / crime_loc.max() # 정규화
crime_loc_norm.head()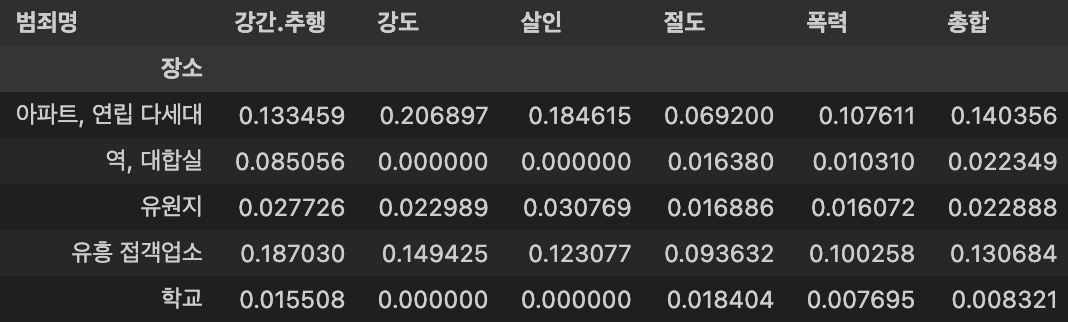
- 정규화된 값을 기준으로, 각 범죄의 평균 발생 건수를 구함
총합column에 저장
crime_loc_norm['총합'] = np.mean(crime_loc_norm, axis = 1)
crime_loc_norm.tail()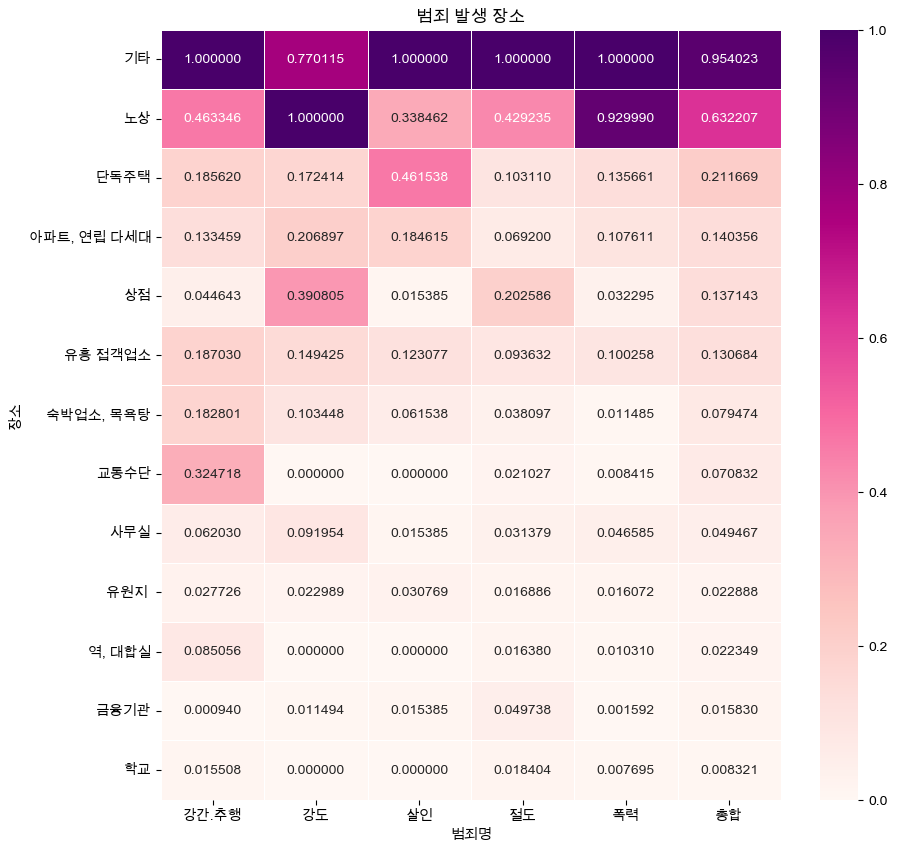
- 각 범죄와 범죄 발생장소의 연관성을 알아보기 위해, 히트맵(Heatmap)을 통해 표현
crime_loc_norm_sort = crime_loc_norm.sort_values('총합', ascending = False) # 내림차순
def drawGraph():
plt.figure(figsize = (10, 10))
sns.heatmap(
crime_loc_norm_sort,
annot = True,
fmt='f',
linewidths = 0.5,
cmap = 'RdPu'
)
plt.title('범죄 발생 장소')
plt.show()
drawGraph()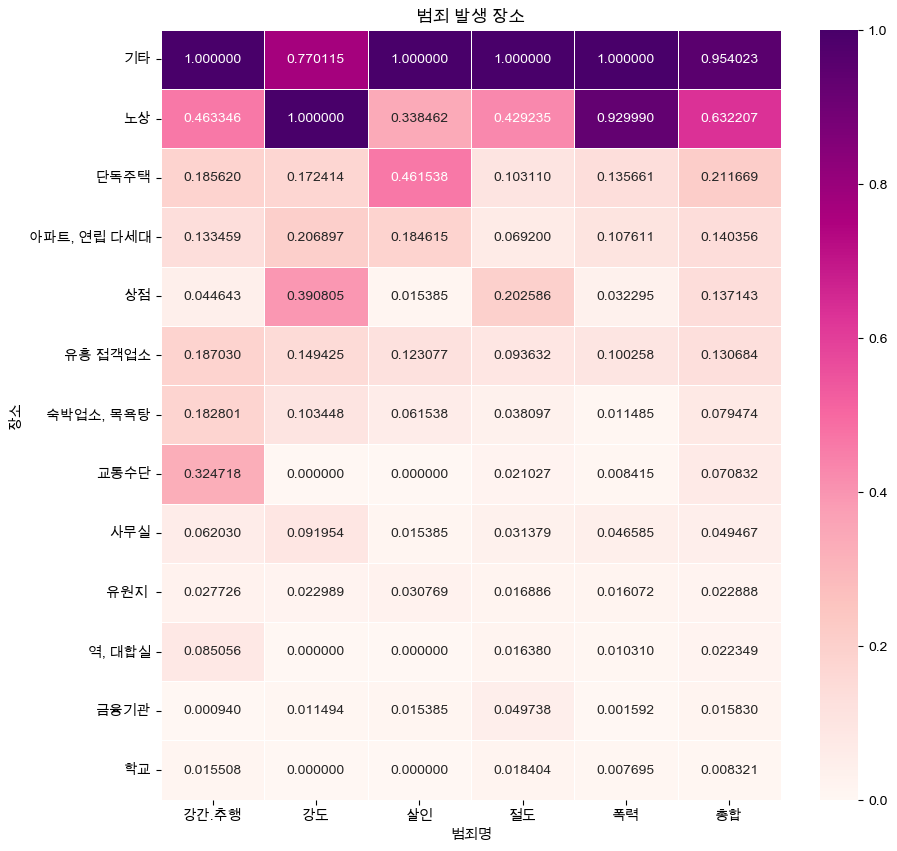

Start