
🔑 Goal
요약
- 서울시 인구수에 따른 범죄별 연관성 확인
- 서울시 범죄현황 발생 장소 분석
- 범죄별 연관성 확인
📗 세부내용
Preprocessing
ModuleLoad
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import rc
rc('font', family='Arial Unicode MS')
ds_url = "/Users/min/Documents/ds_study/제로-베이스---데이터-사이언스-스쿨---강의자료---part-01---05--230120-/Part 04. EDA & Part 05. SQL/Part 04. EDA웹 크롤링파이썬 프로그래밍 - 강의자료/210923 - 02. Analysis Seoul Crime/data/"Crime in Seoul
- DataLoad
- 숫자값들이 콤마(,)를 사용하고 있어 문자로 인식될 수 있다.
- 천 단위 구분(thousands = ',')이라고 알려주면 콤마를 제거하고 숫자형으로 읽는다
crime_raw_data = pd.read_csv(ds_url + '02. crime_in_Seoul.csv', thousands = ',', encoding='euc-kr')
crime_raw_data.head()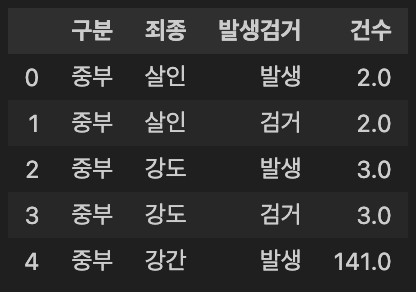
- 범죄 종류 확인
crime_raw_data['죄종'].unique()Output : array(['살인', '강도', '강간', '절도', '폭력', nan], dtype=object)
- NaN 값 제거
crime_raw_data[crime_raw_data['죄종'].isnull()].head()
crime_raw_data = crime_raw_data[crime_raw_data['죄종'].notnull()] # NaN값 제거- 제거 전과 제거 후 비교
crime_raw_data.info()| 제거 전 | 제거 후 |
|---|---|
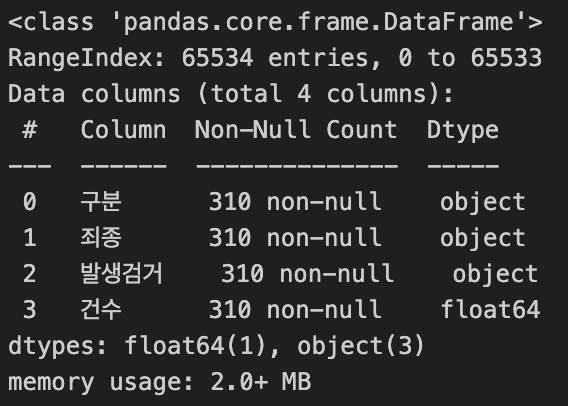 | 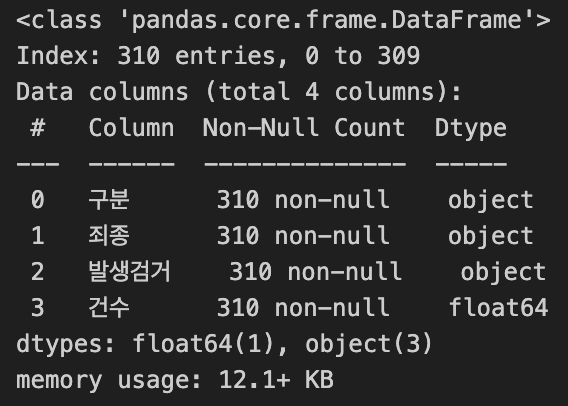 |
- 피벗테이블을 통해 구별 범죄 발생 수를 표현
crime_station = crime_raw_data.pivot_table(crime_raw_data,
index = ['구분'],
columns = ['죄종', '발생검거'],
aggfunc = [np.sum])
crime_station.head()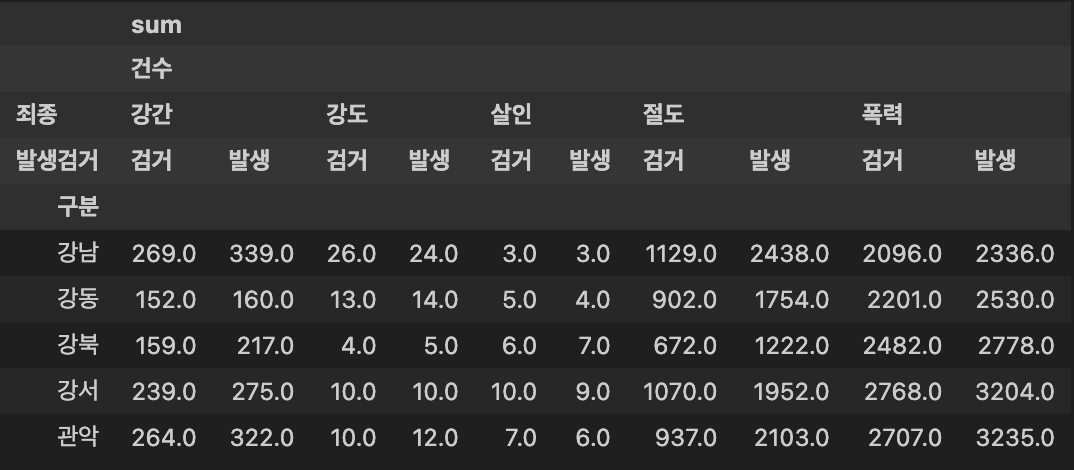
- column 구성 확인
- 피벗테이블의 경우, column이 multi로 잡힘 (단점)
crime_station.columns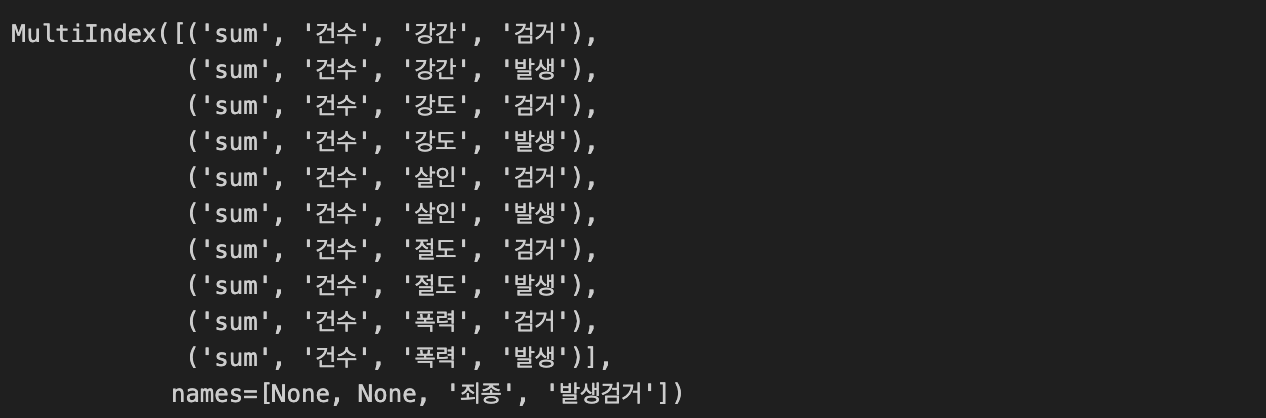
- 필요없는 column level 삭제
- columns Level은 위에서부터 0, 1, 2 ~ 순서
crime_station.columns = crime_station.columns.droplevel([0, 1]) # columns Level은 위에서부터 0 ~
crime_station.columns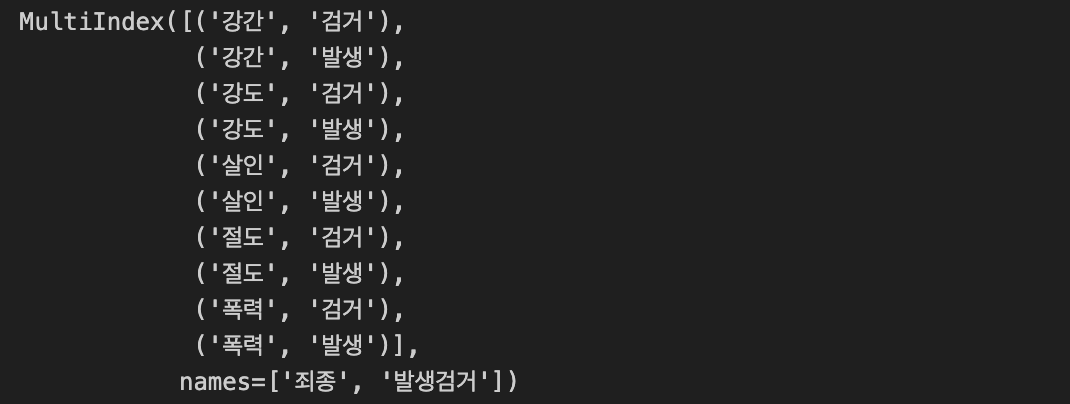
- 테이블의 index 확인
- 구분 인덱스의 경우 경찰서 이름으로 되어있다.
- 경찰서 이름으로 구 이름을 알아야 함
crime_station.index
GoogleMaps를 이용한 데이터 정리
ModuleLoad & GoogleKey
import googlemaps
gmaps_key = 'AIzaSyAyS0HZsy46gyFUhDlIwYQbHdXXCWHNpc8'
gmaps = googlemaps.Client(key = gmaps_key)gmaps.geocode()통해 들어오는 정보 확인
gmaps.geocode('서울영등포경찰서', language='ko') # Test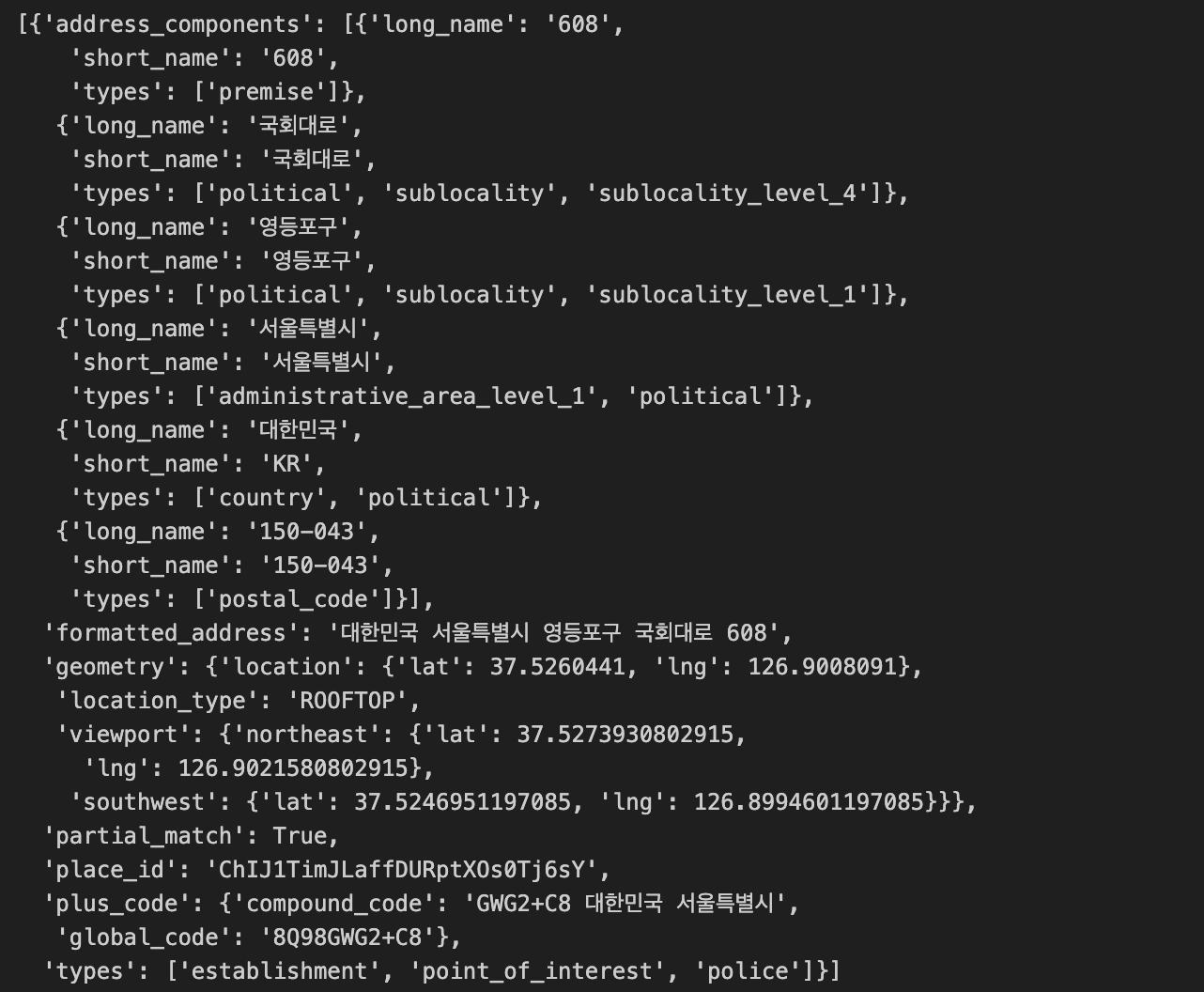
gmaps.geocode()를 통해 좌표(lat, lng)와 주소(address) 호출 여부 확인
tmp = gmaps.geocode('서울영등포경찰서', language='ko')
print(tmp[0].get('geometry')['location']['lat'])
print(tmp[0].get('geometry')['location']['lng'])
print(tmp[0].get('formatted_address'))Output :
37.5260441 126.9008091 대한민국 서울특별시 영등포구 국회대로 608
- 지역 구에 해당하는 부분 추출
tmp = tmp[0].get('formatted_address')
tmp.split()[2]Output : '영등포구’
- 추출 데이터를 저장하기 위해, 기존 데이터프레임(DataFrame)에 새 컬럼(Columns) 생성
구별,lat,lngcolumn 추가
crime_station['구별'] = np.nan
crime_station['lat'] = np.nan
crime_station['lng'] = np.nan
crime_station.head()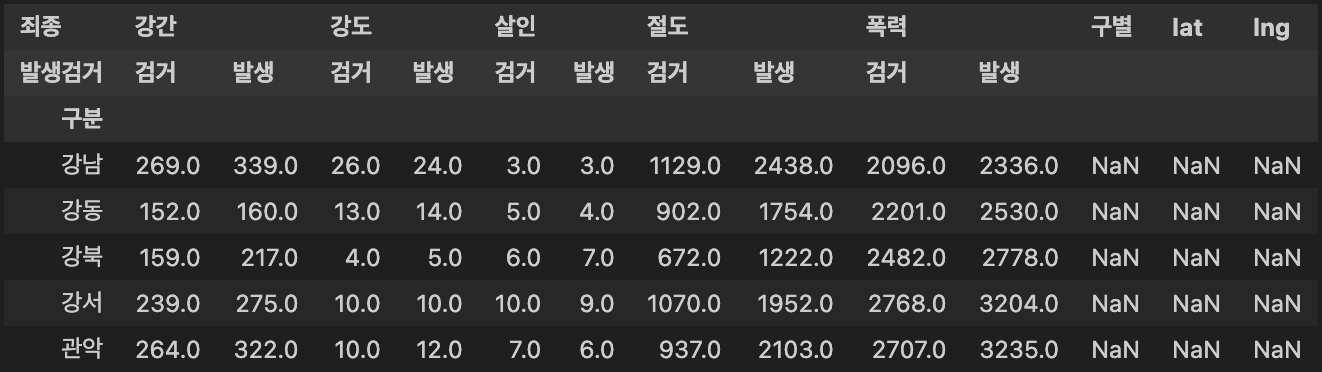
- 경찰서 이름에서 소속된 구 이름 얻기
iterrow()함수 사용- 구 이름을 얻기 위해, 경찰서 주소정보를 가져옴
for idx, rows in crime_station.iterrows():
station_name = '서울' + str(idx) + '경찰서'
tmp = gmaps.geocode(station_name, language = 'ko')
# tmp[0].get('formatted_address')
tmp_gu = tmp[0].get('formatted_address')
print(tmp_gu)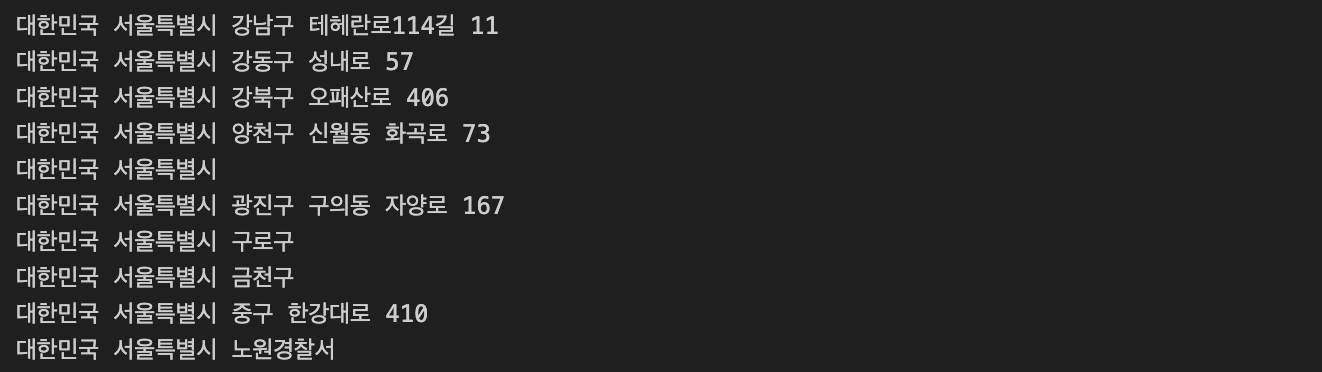
구 이름과위도(lat),경도(lon)정보를 저장- for문을 이용해서 위 표의 NaN을 모두 채워줌
count = 0
for idx, rows in crime_station.iterrows():
station_name = '서울' + str(idx) + '경찰서'
tmp = gmaps.geocode(station_name, language = 'ko')
# tmp[0].get('formatted_address')
tmp_gu = tmp[0].get('formatted_address')
lat = tmp[0].get('geometry')['location']['lat']
lng = tmp[0].get('geometry')['location']['lng']
crime_station.loc[idx, 'lat'] = lat
crime_station.loc[idx, 'lng'] = lng
try:
crime_station.loc[idx, '구별'] = tmp_gu.split()[2]
except:
crime_station.loc[idx, '구별'] = str(idx) + '구'
print(count)
count += 1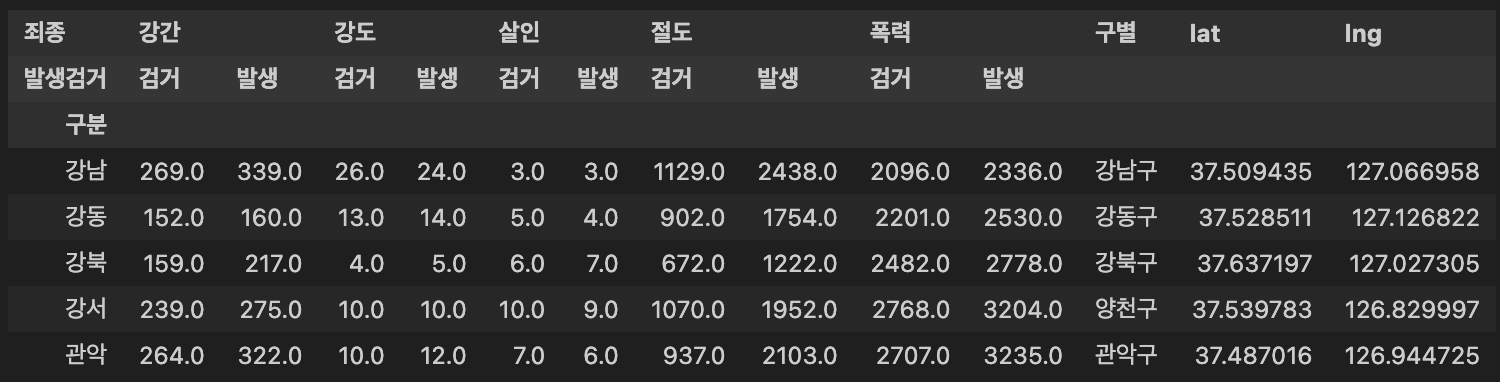
- Column명 변경
0 level,1 levelcolumn을 통해 데이터프레임(DataFrame) Column명 재설정
tmp = [crime_station.columns.get_level_values(0)[n] + crime_station.columns.get_level_values(1)[n] for n in range(0, len(crime_station.columns.get_level_values(0)))]
crime_station.columns = tmp
crime_station.head()
Save Data
# 데이터 저장
my_url = '/Users/min/Documents/ds_study/'
crime_station.to_csv(my_url + '02.crime_in_Seoul_raw.csv', sep=',', encoding='utf-8')구별 데이터로 정리
- 구별 데이터로 정리하기 위해
pivot_table
crime_anal_gu = pd.pivot_table(crime_anal_station, index = '구별', aggfunc = np.sum)
del crime_anal_gu['lat']
del crime_anal_gu['lng']
crime_anal_gu.head()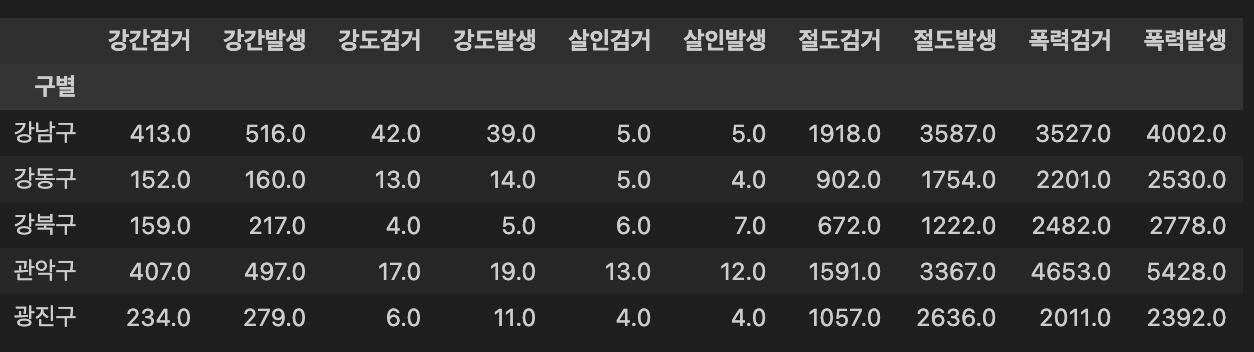
- 각 범죄별 발생 대비 검거비율을 보기 위해, 새로운 column에 계산하여 표기
# 다수의 컬럼을 다수의 컬럼으로 나누기
target = ['강간검거율', '강도검거율', '살인검거율', '절도검거율', '폭력검거율']
num = ['강간검거', '강도검거', '살인검거', '절도검거', '폭력검거']
den = ['강간발생', '강도발생', '살인발생', '절도발생', '폭력발생']
crime_anal_gu[target] = round(crime_anal_gu[num].div(crime_anal_gu[den].values) * 100, 2) # 백분율
crime_anal_gu.head()
발생 건수와검거율에 대해 볼 것이기 때문에,검거 건수는 불필요. 따라서 column 제거
# 필요 없는 컬럼 제거
del crime_anal_gu['강간검거']
del crime_anal_gu['강도검거']
crime_anal_gu.drop(['살인검거', '절도검거', '폭력검거'], axis = 1, inplace = True)- 범죄검거율의 경우, 100%를 초과하는 것이 발생
- 이전에 발생하였던 사건이 그 다음에 해결되어 카운트(count) 되었을 가능성이 있다.
- ex) 7월에 사건 발생 > 8월에 사건 해결
- 100%를 초과할 경우, 100%로 조정
- 이전에 발생하였던 사건이 그 다음에 해결되어 카운트(count) 되었을 가능성이 있다.
crime_anal_gu[crime_anal_gu[target] > 100] = 100 # 100보다 큰 숫자 찾아서 바꾸기
crime_anal_gu.head()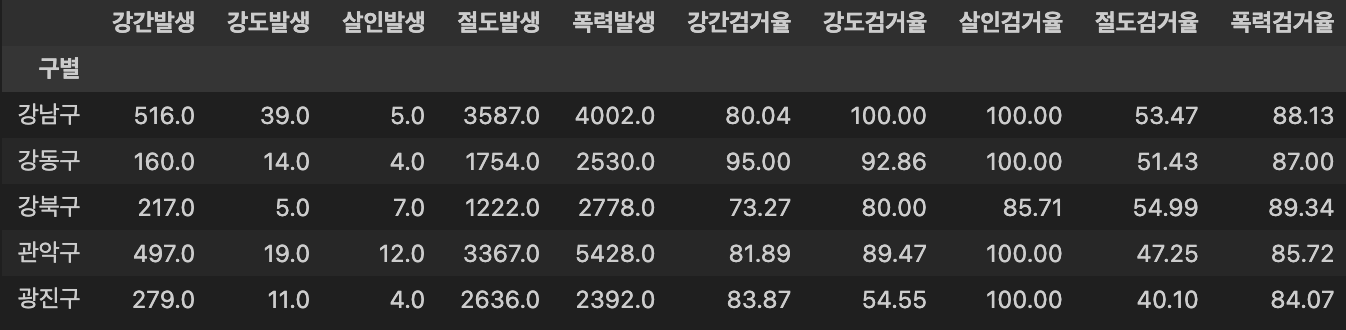
- column명 간소화
crime_anal_gu.rename(columns={'강간발생' : '강간', '강도발생': '강도', '살인발생':'살인', '절도발생':'절도', '폭력발생':'폭력'}, inplace = True)
crime_anal_gu.head() # 컬럼명 변경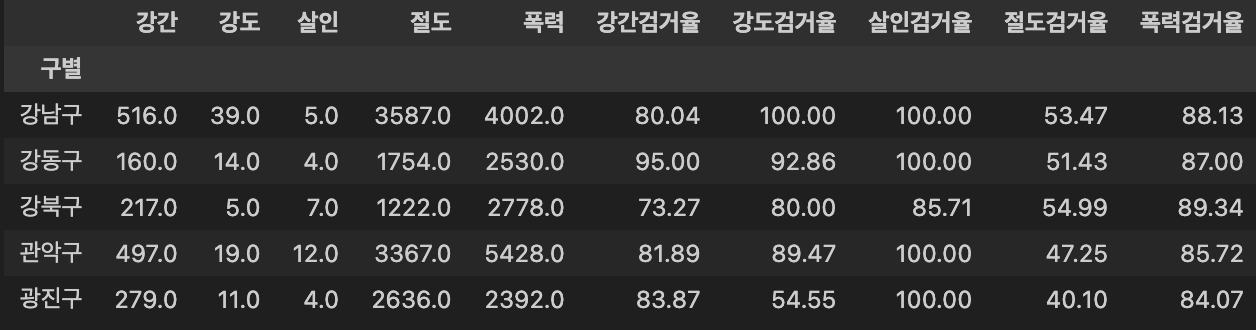
최종 정리
- 정규화 데이터 생성
- 범죄 건수의 단위 차이가 많이나기 때문에, 이를 정규화(normalization)하여 표현
col = ['살인', '강도', '강간', '절도', '폭력']
crime_anal_norm = crime_anal_gu[col] / crime_anal_gu[col].max() # 정규화 데이터 생성
crime_anal_norm.head()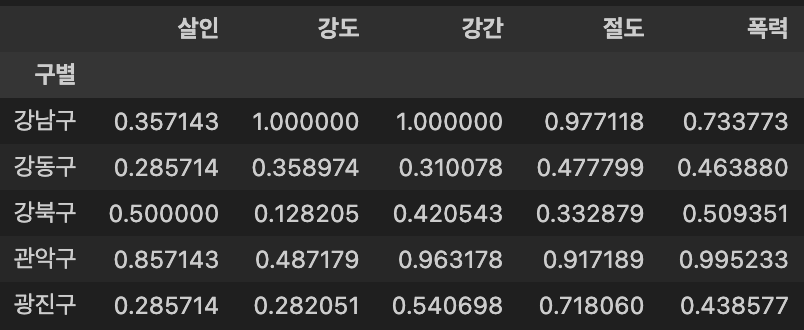
- 정규화(normalization)된 데이터와 검거율을 하나의 데이터프레임(DataFrame)으로 저장
col2 = ['강간검거율', '강도검거율', '살인검거율', '절도검거율', '폭력검거율']
crime_anal_norm[col2] = crime_anal_gu[col2]
crime_anal_norm.head()
-
CCTV 및 인구 데이터를 불러와 붙여넣기
-
DataLoad
my_url = '/Users/min/Documents/ds_study/' result_CCTV = pd.read_csv(my_url + 'CCTV_result.csv', encoding = 'utf-8', index_col = '구별') result_CCTV.head()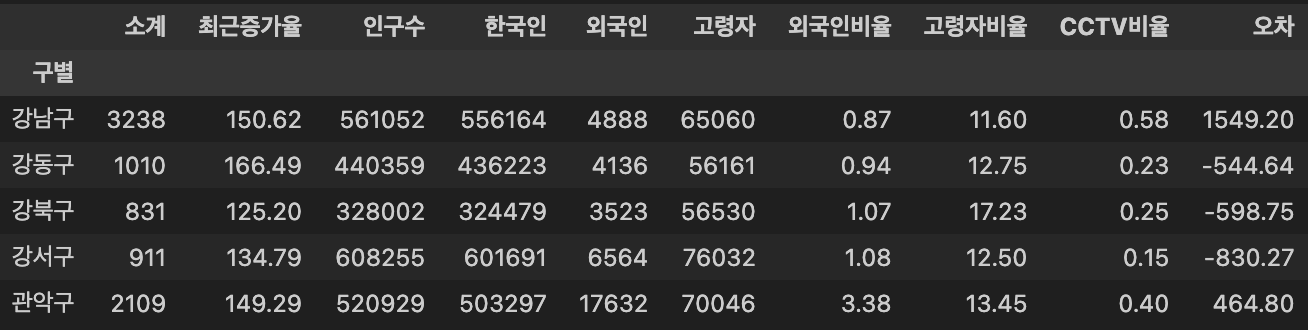
-
데이터 붙여넣기
crime_anal_norm[['인구수', 'CCTV']] = result_CCTV[['인구수', '소계']] crime_anal_norm.head()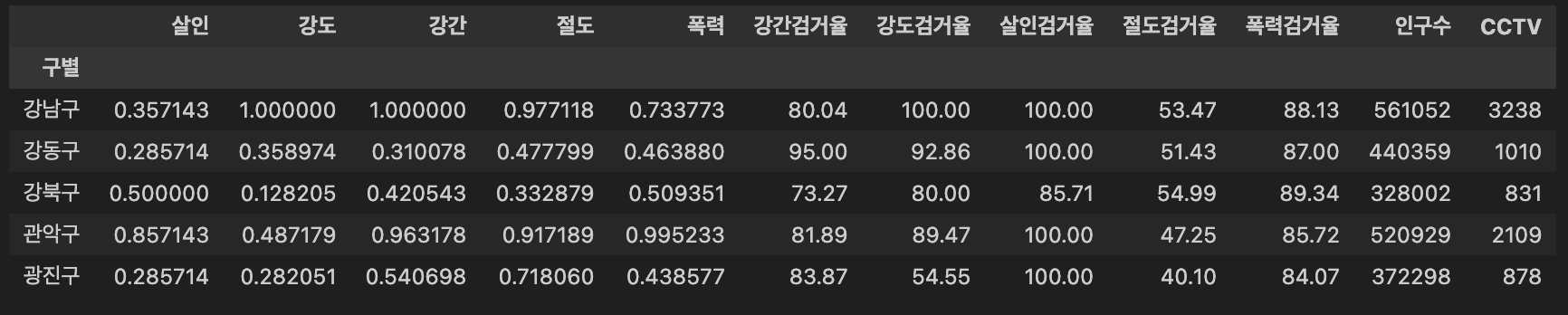
-
- 정규화된 5개 범죄 발생 평균과 검거율 평균을 새 column에 추가
col_crime = ['살인', '강도', '강간', '절도', '폭력']
col_crime_rate = ['강간검거율', '강도검거율', '살인검거율', '절도검거율', '폭력검거율']
crime_anal_norm['범죄'] = np.mean(crime_anal_norm[col_crime], axis = 1) # axis = 1 : 2차원 배열에서 행을 기준으로 연산 // axis = 0 : 열 기준
crime_anal_norm['검거'] = np.mean(crime_anal_norm[col_crime_rate], axis = 1)
crime_anal_norm.head()
Save data
crime_anal_norm.to_csv(my_url + '02.crime_anal_norm.csv', sep = ',', encoding = 'utf-8')
Start