Vision Transformer
관련 글 - Transformer
Transformer-Background
Transformer
논문 : AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
Abstract
Transformer은 등장 이후 NLP 분야에서 실질적인 기본 기술이 되었다. Transformer가 NLP 분야에서 기존의 RNN 구조가 필수가 아님을 보였듯이, 비전 분야에서도 기존의 CNN 구조는 필수가 아니다. 이 논문에서는 일련의 image-patch를 transformer에 넣는 방식으로 최신 CNN 구조를 넘어서는 성과를 보였다.
Introduction
Transformer을 Vision에 적용하려는 노력은 다양했다. 그러나, 모델의 특성상 대규모 모델이 난해했다.
ImageNet과 같은 중형 구조의 데이터셋에서 regularization을 강하게 걸지 않으면, 비슷한 규모의 ResNet 모델에 비하여 좋지 않은 성능을 보였다. 이는 Transformer가 CNN에 비하여 일종의 inductive bias - 특히 전이에 대하여 동등하며, 지역의 위치 정보 부족 - 이 부족하여 충분한 정보가 학습되지 않았기 때문으로 보인다.
하지만, 대규모 데이터셋(14M-300M images)을 사용할 경우, inductive bias가 충분히 학습되어 CNN 구조의 성능을 이기는 것이 발견되었다.
Method
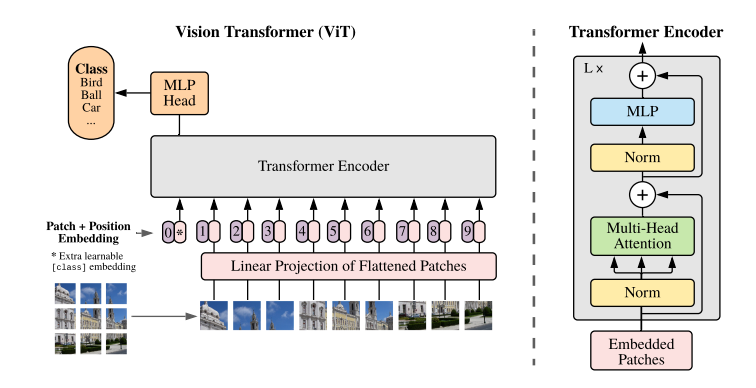
3.1 Vision Transformer
Transformer 원본은 기본적으로 1D sequence를 input으로 받는다. 따라서, 2D image를 input으로 넣기 위해서는 이를 1D sequence로 넣어 주어야 한다. Vision Transformer은 이미지를 여러 개의 크기의 patch들로 나누고, 이를 flatten시켜 Transformer의 input으로 사용한다.
image > patches > flattened 2D patches
Transformer은 크기의 latent vector을 가지므로, 각 patch를 flatten한 뒤 D dimention으로 linear projection을 실행한다
Vision Transformer의 전체 구조를 식으로 표현하면 다음과 같다.
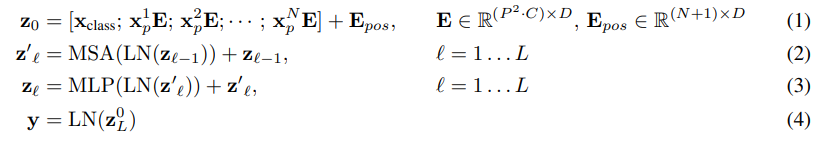
식 4는 classification 부분을 의미한다.
BERT의 class 토큰과 유사하게, Transformer encoder의 결과가 image classification의 결과를 출력하도록 만든다. pre-training과 fine-tuning 동안, classification head는 encoder의 결과인 의 뒤에 붙는다.
classification head는 pre-training에서는 하나의 hidden layer을 가진 MLP, fine-tuning에서는 single linear layer으로 사용된다?
식 1은 Embedding 과정을 의미한다.
Positional embedding은 patch embedding 과정 후에 처리된다. Appendix D.4의 결과에서 보다시피 2D positional embedding이 좋은 성과를 내지 않았기에, 고전적인 1D positional embedding을 사용한다.
식 2, 3은 Transformer의 encoder 부분을 설명한다.
Trnasformer 원본의 encoder은 multihead self-attention의 alternating layer(MSA, Appendix A)와 MLP block으로 구성되어 있다. (eq 2, 3) Layernorm(LN)은 모든 블럭의 앞에 추가되며, residual connection은 모든 블럭의 후에 추가된다.
Inductive bias
Vision Transformer은 CNN에 비하여 더 적은 inductive bias를 가진다.
CNN에서는 지역적인 2d의 이웃 관계가 존재하며, 각 레이어 간 translation equivariance가 생성된다.
그러나, ViT에서는 MLP layer만이 local이자 translationally equvariant하다. 반면, self-attention은 global한 구조를 가진다. 게다가 모델의 첫 부분에서 이미지를 patch로 자르기에, 2d에서의 이웃 정보(위치 정보)가 positional embedding 외에 존재하지 않는다.
translation equivariance : 입력의 위치 변화에 따라 출력 또한 입력과 동일하게 변화하는 것.
Hybrid Architecture
hyprid model에서는 input sequence에 raw image patch 대신 CNN의 feature map을 넣는다.
Fine-Tuning and Higher Resolution
일반적으로는 ViT를 large dataset에서 pre-train 후 smaller dataset에서 fine-tuning한다. 이를 위하여, pre-train된 prediction head를 제거하고 크기의 zero-initialized된 feedforward layer을 붙인다.(K : downstream class의 수). 이처럼 pre-train 후 fine-tuing하는 것은 종종 이점이 있다. 이미지가 고해상도일 경우, patch size를 유지하는 대신 seq length를 늘린다. 이는 공간 정보가 깨져 pre-train의 positional embedding이 무의미해진다. 이 때문에 pre-trained position embedding에 2d interpolation을 시행한다고 한다.
Experiment
Datasets
학습 데이터셋
- ImageNet 1k class, 1.3M images
- ImageNet-21k with 21k classes and 14M images
- JET, 18k classes, 303M high-resolution images
검증 데이터셋(transfer)
- ImageNet with (original validation label + ReaL label)
- CIFAR-10/100
- Oxford-IIIT Pets
- Oxford Flowers-102
- 19-task VTAB classification suite
- task당 1000개의 예제만 존재하는 다양한 테스크.
- Natural(일반), Specialized(medical, satellite), Structured(기하학적 구조)
Basic
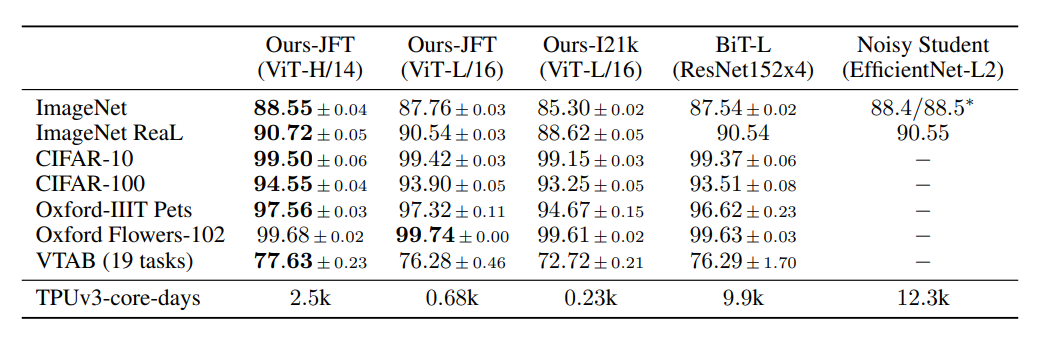
19-task VTAB classification suite
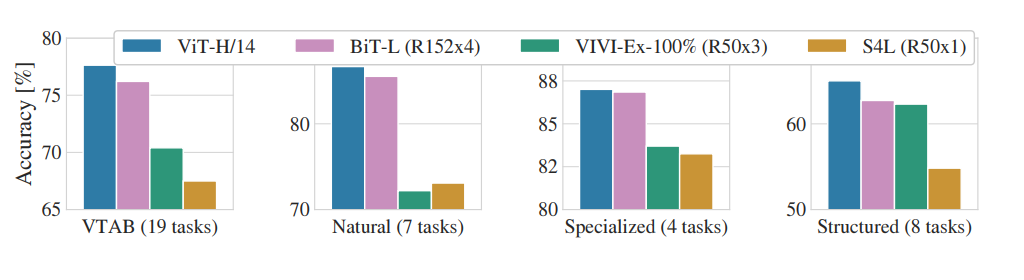
Pre-Training Data Requirement
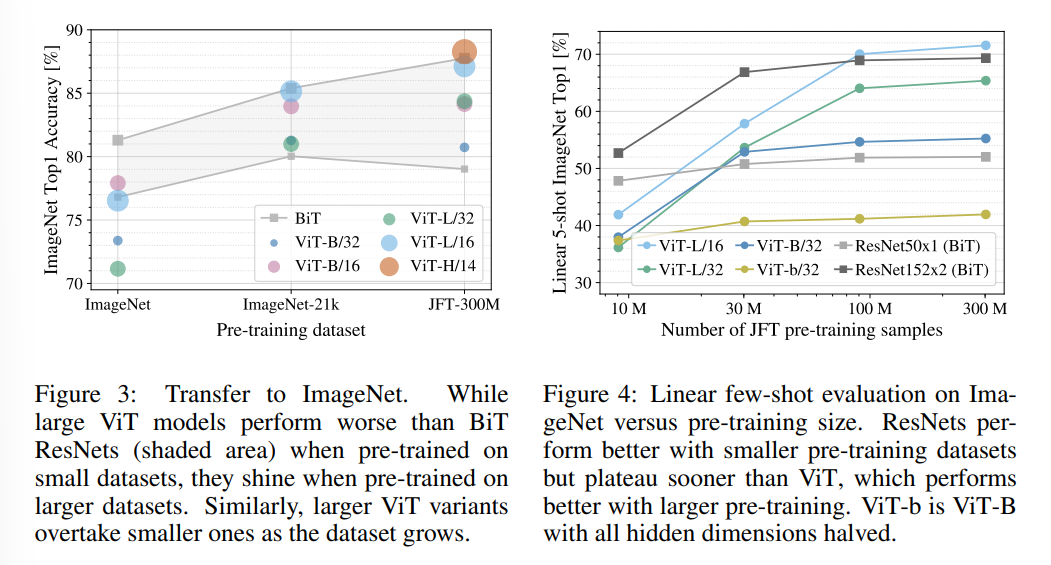
Scaling Study
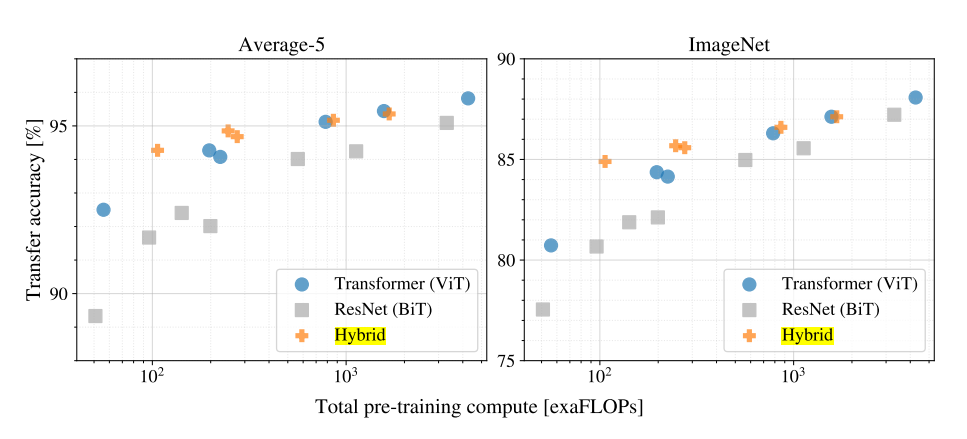
여러 크기의 ViT, ResNet, Hybrid 모델을 실험한 결과.
- ViT가 성능/계산 비용 측면에서 ResNet보다 뛰어남. ViT는 평균적으로 2~4배 적은 계산량이 소모된다.
- CNN의 feature map을 이용한 hybrid는 작은 경우 ViT를 능가하나, 모델이 커질수록 차이가 사라진다. 이는 CNN의 feature extraction 과정이 ViT의 어딘가에서 동작한다고 추정할 수 있다.
- 모델의 성장에 따라 계속해서 성능이 올라가므로, 추가적인 확장을 기대할 수 있다. (후속연구 - Scaling Vision Transformer)
Inspecting Vision Transformer
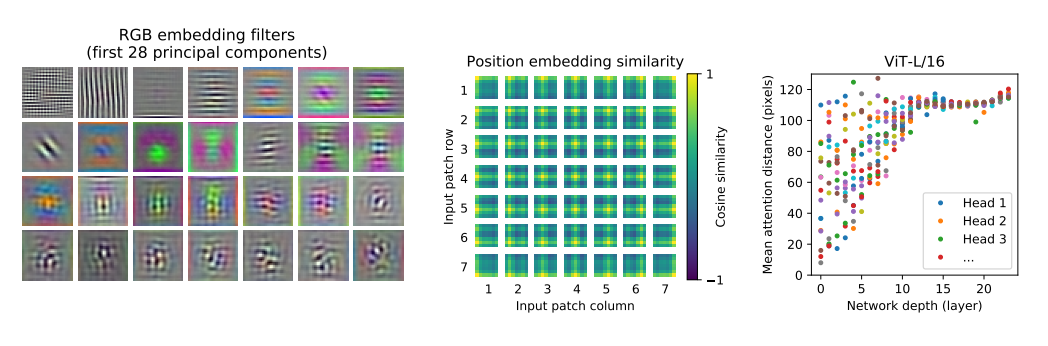
오른쪽 그림은 각 head의 attended distance를 의미한다. self-attention은 CNN과 달리, 낮은 단계에서도 멀리 떨어진 patch에게 영향을 줄 수 있다. 이를 확인하기 위하여 각 층의 attention weight를 이용하여 평균적으로 attend하는 pixel과의 거리, attention distance를 계산하였다. (CNN의 receptive field size 역할). 오른쪽 그림을 보면, 낮은 단계에서는 attention distance가 퍼져 있고, 높은 단계로 갈수록 점차 커지는 것을 알 수 있다. 이는 기본적으로 CNN의 작동 방식과 유사하나, 낮은 단계에서 근처의 영역만 확인하는 것이 아니라 global 한 영역도 확인한다는 차이를 보여준다.

Conclusion
이전 연구와의 차별점
initial patch extraction step과 별개의 image-specific inductive biases를 사용하지 않았다. 대신 이미지를 일련의 patch로 나누어 Trnasformer encoder의 input으로 사용하였다. 이는 대규모 dataset에 pre-train하는 방식에 적합하다.
추가 연구 사항
- ViT를 Detection, Segmentation에 적용하기
- self-supervised pre-training 기법 확장하기
