1. Transaction
1) 개념
Transaction이란, 데이터베이스 작업을 수행하는 단위 프로세스로, 데이터 공유와 다수 사용자 처리를 위해 사용된다. Transaction이 적용되면 여러 명의 사용자가 동시에 동일한 리소스에 접근하더라도, 데이터베이스의 일관성이 보장된다. 이로써 모든 사용자가 동일한 데이터 베이스를 공유할 수 있게 되고, 동시성이 제어될 수 있다.
2) 성질
Transaction은 Jim Gray가 제안한 ACID를 따르며, 모든 데이터베이스는 ACID 원칙을 준수해야 한다.
① Atomicity(원자성)
- Transaction과 관련된 작업들이 부분적으로 실행되다가, 중단되지 않음을 보장한다.
- Begin_Trans부터 End_Trans까지의 일련의 실행 결과가 "All or Nothing"이어야 한다.
② Consistency(일관성)
- Transaction이 성공적으로 실행을 완료하면, 언제나 일관성 있는 데이터베이스 상태가 유지됨을 보장한다.
③ Isolation(격리성)
- Transaction 수행 도중 다른 Transaction의 연산 작업이 끼어들지 못함을 보장한다.
④ Durability(영속성)
- 성공적으로 수행된 Transaction은 영원히 반영되어야 한다.
2. 원자성을 위한 연산
1) 필요성
원자성을 위한 연산을 이해하기 위해선 먼저, 데이터베이스 저장 연산이 내부적으로 어떻게 이루어지는지 알아야 한다. 저장장치는 아래의 3가지 유형으로 분류될 수 있다.
① Volatile Memory
- 시스템 종료 시 저장된 데이터를 상실한다.
- RAM(메인 메모리) 등이 여기에 해당한다.
② Non-Volatile Memory
- 시스템 종료 시에도 데이터를 상실하지 않는다.
- 하지만, 자체 고장으로 인한 손실 가능성이 존재한다.
- Disk나 Tape 등이 여기에 해당한다.
③ Stable Storage
- 여러 개의 Non-Volatile Memory로 구성되어 있다.
- 데이터의 손실로부터 비교적 안전한 구조이다.
- HA(High Availability) Solution(서버 이중화)이나 RAID가 여기에 해당한다.
그 중에서도 RAM과 Disk 사이에서 일어나는 저장 연산의 프로세스를 알아보기로 하자. Disk의 latency(응답 속도)는 RAM에 비해 매우 느리기 때문에, RAM에서 연산이 수행되는 시간과 그것이 Disk에 영구적으로 반영되는 시간 사이에는 간격이 존재할 수 밖에 없다. 만약 연산은 정상적으로 수행되었지만, 디스크에는 반영되지 않았을 경우 Failure가 발생하게 된다.
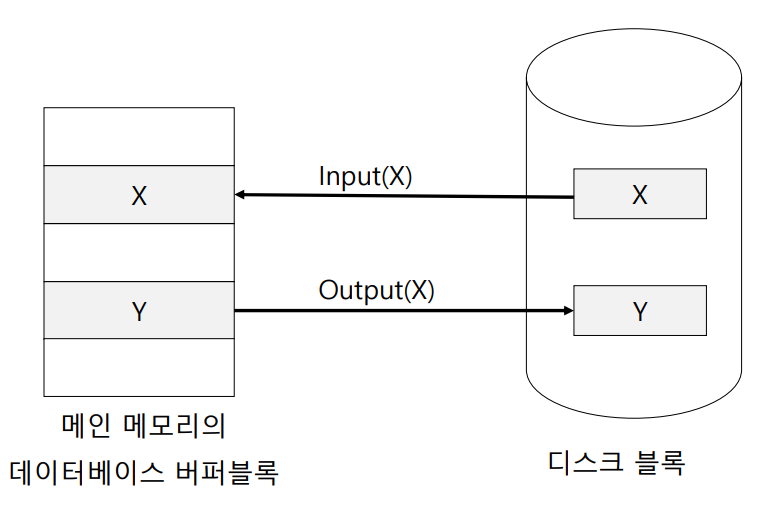
조금 더 구체적인 예시를 생각해보자. 1000원이 있는 A의 계좌에서 2000원이 있는 B의 계좌로 100원을 이체하려고 할 때, 일어나는 프로세스는 아래와 같다.
① Disk를 읽어 A의 계좌 잔액을 알아낸다.
② A의 잔액에서 100원을 빼는 연산을 수행한다.
③ 위 연산의 수행 결과를 디스크에 반영(write)한다.
④ 다시 Disk를 읽어 B의 계좌 잔액을 알아낸다.
⑤ B의 잔액에서 100원을 더하는 연산을 수행한다.
⑥ 위 연산의 수행 결과를 디스크에 반영(write)한다.
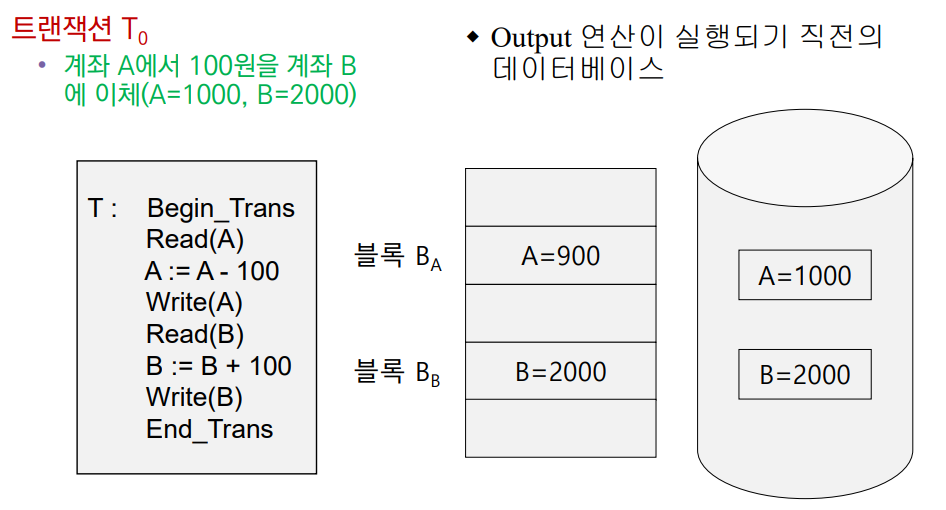
RAM에서 B의 잔액을 계산하는 연산을 성공적으로 끝마쳤지만, 이를 Disk에 write하는 과정(⑥에 해당)에서 failure가 발생했다고 하자. 그 때의 RAM과 Disk의 상태는 아래와 같을 것이다.
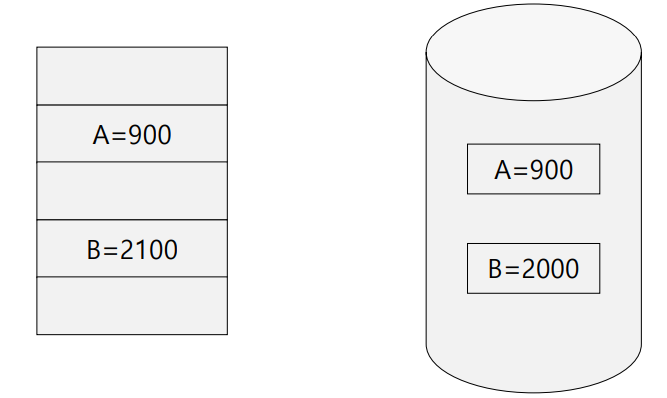
Failure가 발생함으로 인해, 100원이 손실되었다. 이처럼 Failure로 인해 데이터베이스가 일관성을 상실한 상태를, Inconsistent State라고 부른다.
2) 원자성을 보장하는 연산
Transaction의 원자성을 보장하기 위한 연산으로 Commit과 Rollback이 있다.
① Commit
- Transaction의 성공적인 실행(완료)을 의미한다.
- Consistent State를 유지한다.
- 갱신된 데이터의 영속성을 보장한다.
② Rollback
- Transaction 실행에 실패하였음을 의미한다.
- Inconsistent State 상태가 된다.
- 실행된 모든 연산 결과를 Undo 한다.
쉽게 말해, Commit한 시점에 갱신이 반영되며, Commit 하기 전에 Rollback 함으로써 갱신을 반영하지 않을 수 있다. 이를 그림으로 나타내면 아래와 같다.
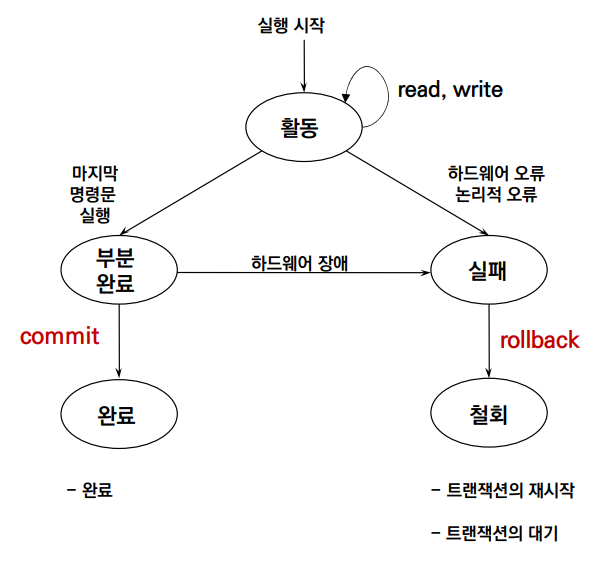
Transaction Status는 Active(활동), Partial Commited(부분 완료), Failed(실패), Commited(완료), Aborted(철회)로 구성된다. 위 그림은 100% 성공이 아니면 모두 Rollback 해야 함을 의미하고 있다. Aborted 상태에서는 Transaction을 재실행하거나 (기존 Transaction은 폐기하고) 다른 Transaction을 대기할 수 있는데, 어떤 방법을 선택할지는 DBA의 design choice에 맡긴다.
3. Transaction Recovery
Transaction Recovery란, 데이터베이스를 장애 발생 이전의 Consistent State로 복원시키는 것을 의미한다. Transaction Recovery에는 Recovery Manager라고 하는 DBMS의 Sub System이 관여하는데, 이와 관련한 코드가 전체 DBMS 코드의 10%를 차지할만큼 신뢰성 있는 회복은 매우 중요하다. Transaction의 회복을 위한 방법에는 Redo와 Undo가 있다.
① Redo
- 데이터베이스 내용 자체가 손상된 경우에 사용한다.
- 가장 최근 복제본을 가져오고, 이 복제본 이후에 일어난 변경에 대해서는 Redo 로그를 재실행하는 방식으로 데이터베이스를 복원한다.
- Redo 로그는 Transaction이 Commit 될 때마다 생성되는 것으로, 트랜잭션이 어떤 변경을 수행했는지 기록한다.
- 즉, 트랜잭션의 변경 사항을 다시 적용하여 데이터베이스를 복구하는 Forward Recovery 방식이다.
② Undo
- 데이터베이스 내용 자체가 손상된 것은 아니지만, 변경 중이거나 변경된 내용에 대한 신뢰성을 잃어버린 경우에 사용한다.
- Undo 로그를 이용하여 모든 변경을 취소하는 방식으로 데이터베이스를 복원한다.
- Undo 로그는 Transaction이 Rollback 될 때마다 생성되는 것으로, 트랜잭션이 반영되기 전의 값을 기록한다.
- 즉, 트랜잭션이 수행한 변경 사항을 취소하고 이전 상태로 돌아가 데이터베이스를 복구하는 Backward Recovery 방식이다.
4. Database Log
1) Log를 활용한 회복
Redo와 Undo 모두 Log를 활용한 회복 방식이다. Redo와 Undo의 동작 방식을 대강 살펴보면 아래와 같다.
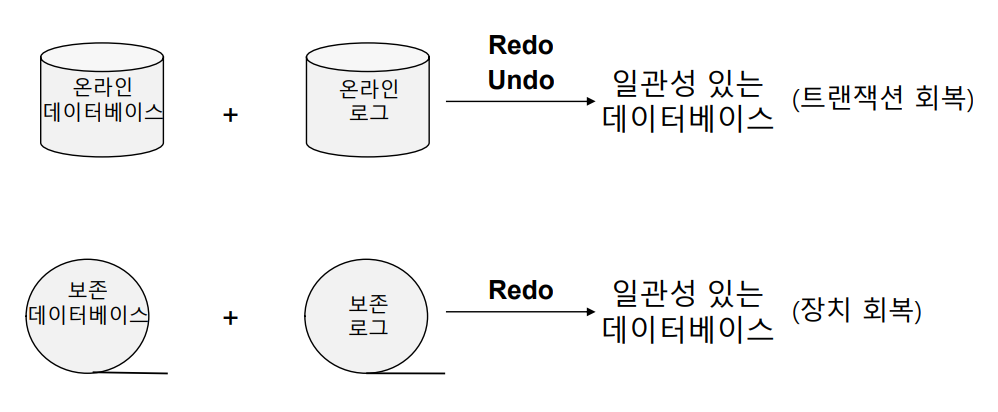
① Online Log
- 주로 트랜잭션의 Atomicity와 Durability를 보장하기 위해 사용된다.
- 트랜잭션이 수행될 때, 해당 트랜잭션으로 인한 변경 사항이 온라인 로그에 기록된다.
- Redo 또는 Undo로 데이터베이스를 복구할 때, 이 온라인 로그가 사용된다.
- 일반적으로 Disk에 기록한다.
② Archive Log
- 주로 데이터베이스의 로그 파일을 지속적으로 백업하는 데 사용된다.
- 온라인 로그가 지속적으로 생성됨에 따라 점차 용량을 차지하게 되므로, 보존 로그에서 이러한 로그 파일을 정기적으로 백업한다.
- 주로 Redo로 데이터베이스를 복구할 때, 이 보존 로그가 사용된다.
- 일반적으로 Tape에 기록한다.
이와 비슷하게 Online Database는 변경 내용을 백업 및 기록하고, Archive Database는 데이터를 오랜 기간동안 보존한다.
2) DBMS의 저장구조
DBMS의 저장 구조는 아래와 같다.
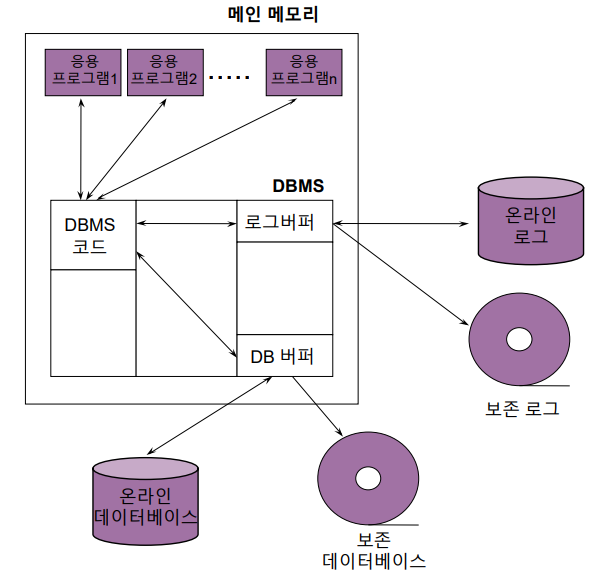
예를 들어 DBMS 코드에서 "1+1=2"라는 연산을 수행한다고 하자. 이 연산의 결과는 로그 버퍼와 DB 버퍼로 전달되는데, 반드시 로그 버퍼에 먼저 저장되어야 한다. 이것을 WAL(Write Ahead Logging)이라 한다. WAL은 Consistency와 Atomicity를 보장하기 위해 사용된다.
3) Log 압축
Database의 원활한 회복을 위해서는 Logging을 자주 해야하지만, 너무 많은 Log는 Database의 성능을 저하시킬 수 있다. 따라서, 저장장치의 효율성 및 신속한 회복을 목적으로 Log 압축을 사용한다.
Log 압축은 Log를 실제로 압축시킨다는 의미가 아니라, 불필요한 로그를 저장하지 않는다는 의미이다. 불필요한 로그에는 아래와 같은 것들이 포함될 수 있다.
① 실패한 Transaction에 대한 로그
- 해당 Transaction이 이미 Rollback 되었기 때문에 불필요하다.
② 성공한 Transaction의 갱신 전 데이터에 대한 로그
- Redo에 사용할 새로운 데이터만 있으면 충분하다.
- 여러 번의 Transaction을 통해 거듭 갱신된 데이터의 경우에도, 마지막으로 갱신된 데이터만 있으면 충분하다(오히려 Redo의 효율성도 향상됨).
4) Recovery with Checkpoints
Redo와 Undo를 이용해 데이터베이스를 복구할 때, 어떤 Transaction에 대해 Redo와 Undo가 필요한지 결정해야 한다. 하지만, 이를 위해 Log를 Full Scan하는 것은 너무나도 많은 시간을 필요로 한다.
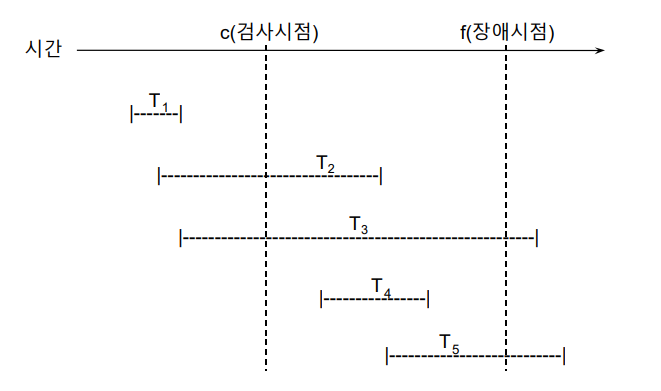
이 때, 사용할 수 있는 방법이 Recovery with Checkpoints(검사시점 회복)이다. Checkpoints는 데이터베이스 시스템에서 주기적으로 발생하는 검사시점으로, 이 시점에서 데이터베이스는 Consistent State로 간주되며, 현재까지의 트랜잭션들이 디스크에 반영된다.
Checkpoints를 활용하여 Redo와 Undo를 결정하는 방법은 아래와 같다.
- Checkpoint 이전에 완료된 Transaction은 Redo와 Undo가 필요하지 않다.
- Failure가 발생한 시점에 여전히 실행 중이던 Transaction은 Undo 대상이다.
- Failure가 발생하기 이전에 완료되었지만, CheckPoint를 지나지 못한 Transaction은 Redo 대상이다.
아래의 그림에서 T2와 T4는 Redo의 대상, T3, T5는 Undo의 대상이 되며, T1은 별도의 Recovery 작업을 필요로 하지 않는다.