1. Index 유무에 따른 검색 시간 비교
백만명의 Employee가 존재하는 테이블을 생성해보자. (sql의 길이가 길어서 sql문을 제공해줄 수 없기 때문에, 아래의 Dummy Data 생성 방법에 대한 설명을 읽고 직접 만들어보기 바란다.)
① million_insert_quries.sql이라는 이름으로 sql문을 저장한다.
② cmd에서 sql파일이 존재하는 디렉토리로 이동한 후 mysql을 실행한다. 아래의 명령을 입력해 백만 개의 데이터가 존재하는 Employee 테이블을 생성한다.
cd Desktop/db/Database
mysql -u root -p
source ./million_insert_quries.sql③ DB에 데이터가 잘 들어갔는지 확인해보자.
select count(*) from Employee;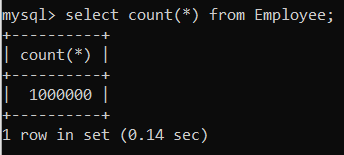
④ 쿼리 실행에 앞서 explain 명령을 사용하여 Query Execution Plan을 확인해보자.
explain select count(Fname) from Employee where Lname="Lee";
- type 필드의 값이 ALL이라는 것은 Table을 Full Scan하여 조건에 맞는 반환 값을 탐색할 계획임을 의미한다.
- possible_keys나 key 필드의 값이 모두 NULL이라는 것은 사용할만한 인덱스가 없기 때문에 아무런 인덱스도 사용하지 않을 계획임을 의미한다.
⑤ 이제 쿼리를 실행하여 인덱스가 없는 상태에서의 실행 시간을 확인해보자.
- 평균적으로 0.97초 정도 걸리는 것 같다.
select count(Fname) from Employee where Lname="Lee";
select count(Fname) from Employee where Lname="Kim";
select count(Fname) from Employee where Lname="Park";
select count(Fname) from Employee where Lname="Brown";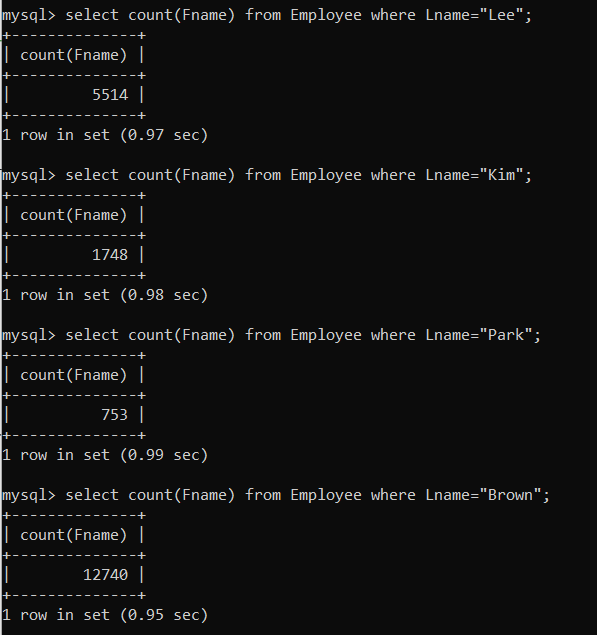
⑥ 탐색 시간을 단축하기 위해선 인덱스를 적용해야 한다. 아래의 명령을 입력하여 Index를 적용해보자.
- create index {인덱스 명} on {테이블 명}({인덱스를 적용할 Column})
- 여기서는 Lname, Sex, Dno에 대한 다중 컬럼 인덱스를 적용할 것이다.
- 다중 컬럼 인덱스를 적용해도 조건이 인덱싱 순서에 맞으면 인덱스를 이용해 검색을 수행한다.
create index employee_on_Lname_Sex_Dno
on Employee(Lname, Sex, Dno) using BTree;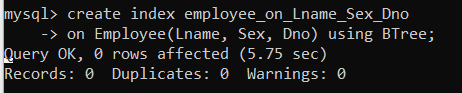
⑦ 만약 Index를 제거하고 싶다면 아래의 명령을 입력하면 된다.
- drop index {인덱스 명} on {테이블 명}
drop index employee_on_Lname_Sex_Dno on Employee;
⑧ 적용된 Index를 확인해보고 싶으면 아래의 명령을 입력하면 된다.
- show index from {테이블 명}
- primary key와 unique key에 대해서는 자동으로 Index가 생성된다. (이 Index는 삭제할 수 없다.)
- 인덱스의 Cardinality를 확인하여 인덱스의 효율을 가늠할 수 있다. (Cardinality가 높을수록 인덱스의 효율이 증가함)
show index from Employee;
⑨ 이제 Index가 적용된 상태에서의 Query Execution Plan을 확인해보자.
explain select count(Fname) from Employee where Lname="Lee";
- possible_keys나 key 필드의 값을 통해 where 절에 Lname만 사용되었음에도 Lname, Sex, Dno에 대한 다중 컬럼 인덱스가 적용됨을 확인할 수 있다.
- type 필드의 값이 ref로 변경되었는데, 이는 where 절에 사용된 컬럼이 인덱스에 의해 참조됨을 의미한다.
⑩ 다시 위 쿼리를 실행하여 실행시간을 비교해보자.
- 평균적으로 0.04초 정도 걸리는 것 같다.
select count(Fname) from Employee where Lname="Lee";
select count(Fname) from Employee where Lname="Kim";
select count(Fname) from Employee where Lname="Park";
select count(Fname) from Employee where Lname="Brown";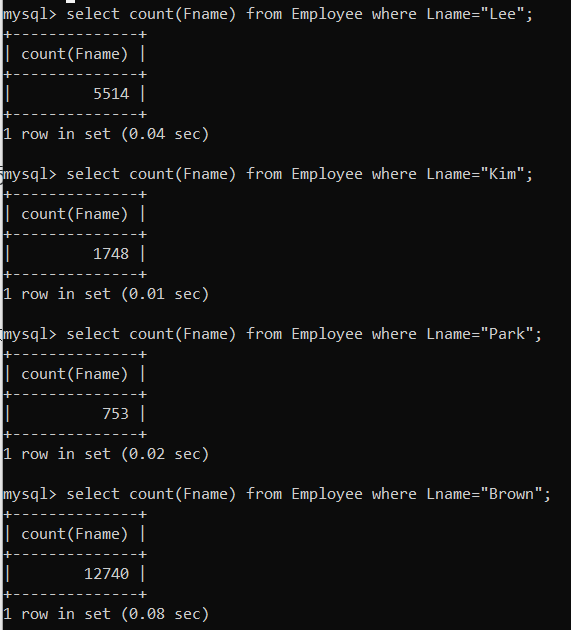
이와 같이 Index를 적용하면, 보다 효율적으로 레코드를 탐색할 수 있다.
2. 파이썬 Faker 모듈을 이용하여 더미 데이터 생성하기
① db 폴더 > Database > week12 폴더를 생성한다.
② cmd에서 week12 디렉토리로 이동한 후 mysql을 열어 아래의 명령을 입력한다.
create database week12;
use week12; ③ VSCode에서 week12 폴더를 연다.
④ 터미널을 열고, 아래의 명령을 입력하여 Faker 모듈과 pymysql 모듈을 설치한다.
python -m pip install Faker
python -m pip install pymysql⑤ week12.py라는 이름으로 파일을 생성한 후 아래의 내용을 입력한다.
from faker import Faker
import pymysql
fake = Faker()
conn = pymysql.connect(
host='localhost',
user='root',
port=3306,
password='{비밀번호}',
database='week5'
)
cursor = conn.cursor()
max_id = 10 # 기존에 존재하는 id
for _ in range(200000):
max_id += 1
name = fake.name()
email = fake.email()
phone_number = fake.phone_number()
department_id = fake.random_int(min=1, max=5)
# 학생 데이터 삽입
cursor.execute('''
INSERT IGNORE INTO student (id, name, email, phone_number, department_id)
VALUES (%s, %s, %s, %s, %s)
''', (max_id, name, email, phone_number, department_id))
# 변경사항 커밋
conn.commit()
# 연결 종료
conn.close()- week5에 생성한 Inha DB의 Student 테이블에 insert한다.
- 이전에 생성한 Student 테이블에 이미 10까지 id를 사용했기 때문에 10에서 1씩 늘려가는 auto-increment 방식으로 id를 할당한다.
- email이 unique 해야 한다는 제약조건이 존재하기 때문에 더미 데이터 삽입 과정에서 오류가 날 수 있다. 이를 방지하기 위해 INSERT IGNORE를 사용하였다. INSERT IGNORE를 사용하면, 에러 없이 해당 데이터를 무시한다.
⑥ 위 파일을 실행시킨다. cmd에 아래의 명령을 입력하여 DB에 데이터가 잘 입력되었는지 확인하자.
- 20만번의 루프를 돌았지만, 13만명만 채워진 이유는 이메일이 중복되는 데이터를 버렸기 때문이다.
select count(*) from student;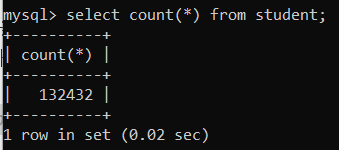
⑦ 정확히 10만개의 데이터가 요구되는 상황에서는 아래의 코드를 사용하면 된다.
- 이번 포스팅에서는 대량의 데이터가 필요한 것일 뿐 정확히 10만 개의 데이터가 필요한 것은 아니므로, ⑥의 코드를 이용할 것이다.
from faker import Faker
import pymysql
fake = Faker()
conn = pymysql.connect(
host='localhost',
user='root',
port=3306,
password='{비밀번호}',
database='week5'
)
cursor = conn.cursor()
max_id = 10 # 시작 id를 10으로 초기화
inserted_count = 0 # 삽입된 데이터 수를 카운트하는 변수 추가
while inserted_count < 100000: # 10만개의 데이터가 삽입될 때까지 반복
max_id += 1
name = fake.name()
email = fake.email()
phone_number = fake.phone_number()
department_id = fake.random_int(min=1, max=5)
# 생성된 이메일이 이미 데이터베이스에 존재하는지 확인
cursor.execute('SELECT COUNT(*) FROM student WHERE email = %s', (email,))
existing_count = cursor.fetchone()[0]
if existing_count == 0:
# 학생 데이터 삽입
cursor.execute('''
INSERT INTO student (id, name, email, phone_number, department_id)
VALUES (%s, %s, %s, %s, %s)
''', (max_id, name, email, phone_number, department_id))
inserted_count += 1 # 데이터 삽입 성공 시에만 카운트 증가
# 변경사항 커밋
conn.commit()
# 연결 종료
conn.close()3. Index 성능 평가
1) 평가 방법
Index를 사용하는 것이 항상 좋은 것은 아니다. 그렇다면 Index는 언제 사용해야 하는 것이며, 어떻게 해야 효율을 최대화할 수 있을까? 11주차 이론에서 이미 다룬 내용이지만, 중요한 내용이므로 한번 더 다루도록 하겠다.
- Selectivity 및 Cardinality가 높은 Column에 적용한다.
- 조회에 자주 사용될만한 Column에 적용한다.
- 변경될 여지가 적은 Column에 적용한다.
- Single Column Index보다는 신중히 고려된 Multiple Column Index를 사용한다.
- Join 연산이 필요한 쿼리에는 필수적으로 Index를 적용한다.
- 너무 많은 Index를 적용하지 않는다.
Index의 성능은 Show Index의 Cardinality와 Explain의 Rows, Filtered로 평가될 수 있다.
Index의 Cardinality란, 해당 Index가 가리키는 Column의 고유한 값들의 개수를 의미한다. Cardinality의 값이 커질수록 인덱스의 사용 효율은 높아지는데, 이는 인덱스가 다양한 값을 가지고 있을수록 원하는 값을 빠르게 찾을 수 있기 때문이다. primary key와 unique key에 대해서는 자동으로 Index가 생성되는 이유가 바로 이것이다. 기본 키와 Unique Key는 모두 높은 카디널리티를 갖기 때문에 자동으로 Index를 적용해주는 것이다. (참고로, foreign key를 인덱싱하는 이유는 조인 성능 향상시키기 위함이다.)
또한, Explain에서 Rows는 쿼리에서 검색해야 할 것으로 예측되는 행의 수를 의미하고, Filtered는 Where이나 Join 등에서 얼마나 많은 행이 실제로 선택되었는지를 % 단위로 나타낸 것이다. 즉, Filtered 값이 100에 가까울수록 조건에 부합하는 행의 비율이 높다(Selectivity가 낮다). 따라서 Rows가 매우 큰 값일 때 Filtered 값이 100에 가깝다면, 해당 컬럼에는 인덱스를 적용하지 않는 편이 좋은 것이다.
2) 성능 평가
① cmd에 아래의 명령을 입력해, student Table에 존재하는 Index의 목록을 확인할 수 있다.
show index from student;
- 아직 아무런 index도 추가해주지 않았음에도 높은 Cardinality를 갖는 primary key와 unique key에 대해 자동으로 Index가 생성되었음을 확인할 수 있다.
- 참고로, foreign key가 자동으로 인덱싱되는 이유는 조인 성능을 향상시키기 위함이다.
② 이번에는 Explain의 Rows, Filtered를 분석해보자.
explain select count(name) from student where name="Danny Tucker";
- type 필드의 값인 ALL은 Table을 Full Scan하여 조건에 맞는 값을 반환할 계획임을 의미한다. 이는 사용할만한 인덱스가 없음을 의미하기도 한다.
- 실제로 possible_keys나 key 필드의 값이 모두 NULL이므로, 아무런 인덱스도 적용하지 않은 상태에서 쿼리를 수행할 것이다.
③ 인덱스가 없는 상태에서 쿼리의 실행시간을 확인해보자.
select count(name) from student where name="Danny Tucker";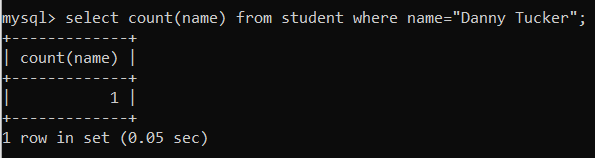
④ 이제 Index를 적용한다.
- Index를 적용하기 전, 인덱스의 효율을 평가하는 과정이 선행되어야 한다.
- ②에 나타난 filtered 값을 확인해보니 name에 대한 Selectivity가 높은 편임을 알 수 있다.
- 이번에도 마찬가지로 다중 컬럼 인덱스를 적용해보기로 한다.
create index student_on_name_email_department_id on Student (name, email, department_id) using BTree;
⑤ Index가 잘 적용되었는지 확인해보자.
show index from student;
- name에 대한 Cardinality가 약 86000이므로, 어느 정도의 인덱싱 효율을 기대해볼 수 있을 것이다.
⑥ 이번에는 Explain 명령을 이용해 Query Execution Plan을 확인해보자.
explain select count(name) from student where name="Danny Tucker";
- where 조건에 name만 사용되었음에도 name, email, department_id에 대한 다중 컬럼 인덱스를 사용하고 있음을 확인할 수 있다.
- 인덱스가 적용되었기 때문에 type이 ALL에서 ref로 개선되었다.
⑦ Index 적용 후의 쿼리 실행 시간을 확인해보자.
select count(name) from student where name="Danny Tucker";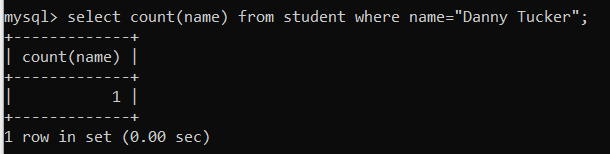
- Index를 적용한 후 약 0.05초 정도의 Query Performance 향상이 있었음을 확인할 수 있다.
4. 다양한 Index 적용해보기
1) Index 추가 적용
아래의 5개의 Index를 추가로 적용해보고 적용 전과 성능을 비교해보자.
① department_name 인덱스
create index department_name on Department (name) using BTree;
② student_on_email_name 인덱스
create index student_on_email_name on Student (email, name) using BTree;
③ student_on_name_phone_number 인덱스
create index student_on_name_phone_number on Student (name, phone_number) using BTree;
④ student_on_name_email_phone_number 인덱스
create index student_on_name_email_phone_number on Student (name, email, phone_number) using BTree;
⑤ student_on_name 인덱스
create index student_on_name on Student (name) using BTree;
지금까지 적용한 총 5개의 인덱스를 확인해보자.
show index from student;
show index from department;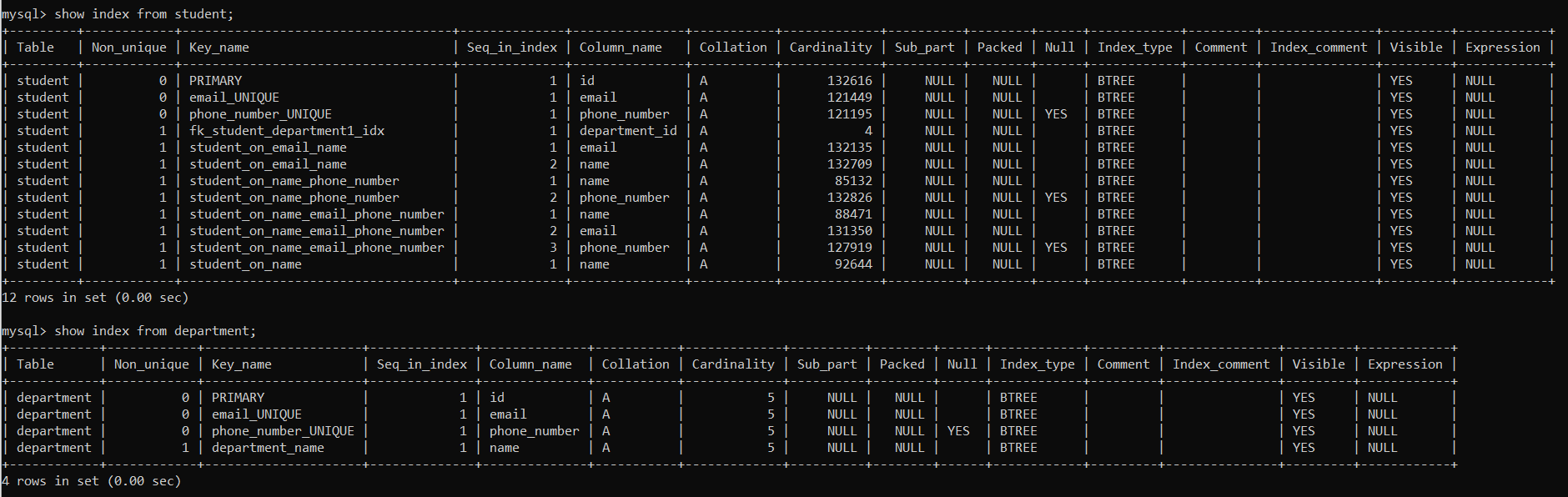
2) Index의 유무에 따른 성능 평가
① department_name 인덱스를 이용한 쿼리
select count(*) from Student s, Department d where s.department_id=d.id and d.name='BusinessAdministration';-
Index 적용 전
- Query Execution Plan

- 실행 시간

- Query Execution Plan
-
Index 적용 후
- Query Execution Plan
→ Index가 잘 적용되었음을 확인할 수 있다.

- 실행 시간
→ Department 테이블의 Row가 5개밖에 안 되다보니 실행시간은 Table Full Scan과 큰 차이가 없다. (Department 테이블의 크기가 매우 컸다면 Query Performance가 향상됐을 것이다.)

- Query Execution Plan
② student_on_email_name 인덱스를 이용한 쿼리
select count(*) from student where email like'%jo%' and name like '%an%';-
Index 적용 전
- Query Execution Plan

- 실행 시간
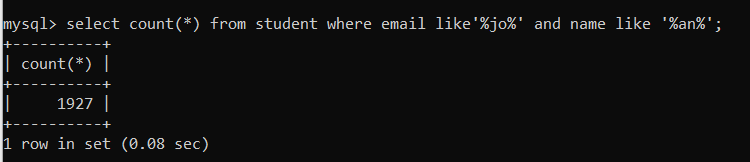
- Query Execution Plan
-
Index 적용 후
- Query Execution Plan
→ Index가 잘 적용되었음을 확인할 수 있다.

- 실행 시간
→ Index Full Scan으로 인해 오히려 실행시간이 증가하였다. 즉, Like 연산에 Index를 적용하는 것은 좋지 않은 선택이다.
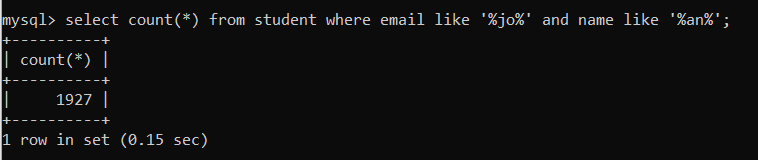
- Query Execution Plan
③ student_on_name_phone_number 인덱스를 이용한 쿼리
select count(*) from student where name='hyunseop' and phone_number='010-1111-1234';- Index 적용 전
- Query Execution Plan

- 실행 시간

- Query Execution Plan
- Index 적용 후
- Query Execution Plan
→ student_on_name_phone_number 인덱스가 아닌 기존의 phone_number_UNIQUE 인덱스를 사용하고 있다.

- 실행 시간
→ Query Optimizer가 추가된 Index보다 unique한 phone_number를 이용하는 편이 더 빠르다고 판단했기 때문에 실행시간이 그대로이다.

- Query Execution Plan
④ student_on_name_email_phone_number 인덱스를 이용한 쿼리
select count(*) from student where name='hyunseop' and email='hyunseop123@naver.com';-
Index 적용 전
- Query Execution Plan

- 실행 시간

- Query Execution Plan
-
Index 적용 후
- Query Execution Plan
→ 마찬가지로 student_on_name_email_phone_number 인덱스가 아닌 기존의 email_UNIQUE 인덱스를 사용하고 있다.

- 실행 시간
→ Query Optimizer가 추가된 Index보다 unique한 email을 이용하는 편이 더 빠르다고 판단했기 때문에 실행시간이 그대로이다.

- Query Execution Plan
⑤ student_on_name 인덱스를 이용한 쿼리
select count(*) from student where name='Michael Smith';- Index 적용 전
- Query Execution Plan

- 실행 시간
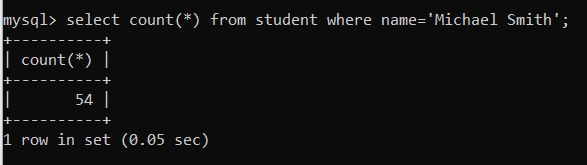
- Query Execution Plan
- Index 적용 후
- Query Execution Plan
→ student_on_name 인덱스가 적용되었다.

- 실행 시간
→ student_on_name 인덱스를 적용함으로써 쿼리 성능이 향상되었다. 이는 name이 unique하지는 않으면서, Cardinality가 높은 값이기 때문이다.
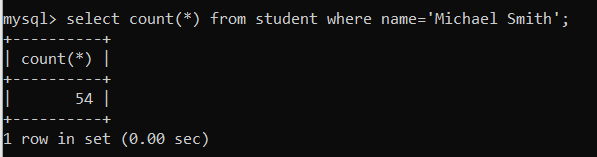
- Query Execution Plan
3) 고찰
지금까지 살펴본 내용을 토대로 Index의 성능을 평가하면 아래와 같다.
① Unique Key 또는 Primary Key에 해당하는 Column을 이용하는 Index는 별도로 등록할 필요가 없다.
- Unique Key 또는 Primary Key의 Selectivity는 항상 최고이기 때문에 Query Optimizer가 가장 먼저 수행한다.
- Query Optimizer는 조건에 해당하는 Row를 단번에 결정지을 수 있다.
- 그러므로 별도의 인덱스가 없어도 쿼리 성능에 전혀 문제가 되지 않는다.
② Index는 Like 연산 성능에는 전혀 도움이 되지 않는다.
- 부분 일치를 검색하는 Like 연산의 특성과 정확한 일치에서 효율이 높은 B-Tree Index의 특성이 서로 상충한다.
- 오히려 Index가 오버헤드로 동작한다.
③ Unique 하지는 않지만 Cardinality가 높고, 조건문에 자주 사용되는 Column이라면, Index를 별도로 등록하는 것이 좋다.
