1. Big Data 개요
1) 핵심 속성
예전에는 Big Data의 핵심 속성을 3Vs라고 불렀다.
- Volume: 데이터의 크기
- Velocity: 데이터의 생성 및 처리 속도
- Variety: 데이터의 다양성
그러나 나중에 아래의 2가지 속성이 추가되면서, 현재는 5Vs로 Big Data의 핵심 속성을 정의하고 있다.
- Veracity: 데이터의 정확성 및 신뢰성
- Value: 데이터로부터 얻을 수 있는 가치
2) OLTP와 OLAP
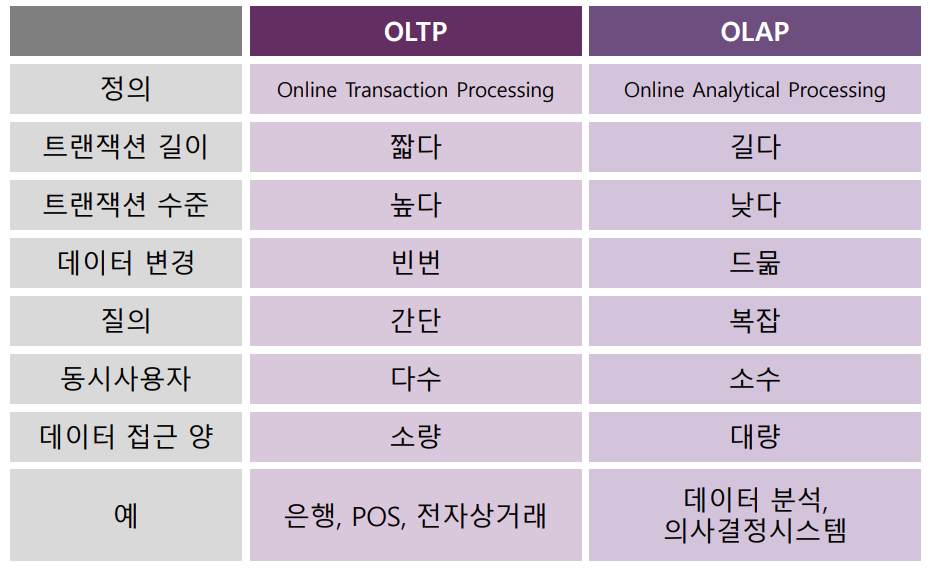
Database 작업은 크게 두 종류로 구분된다. 바로 OLTP(Online Transaction Processing)와 OLAP(Online Analytical Processing)이다.
① OLTP
- 주로 실시간 트랜잭션 처리에 사용된다.
- 데이터베이스에 새로운 데이터를 입력하고 업데이트하는 등 간단하고 짧은 트랜잭션을 반복적으로 수행한다.
- 트랜잭션 간의 높은 격리 수준이 필요할 수 있다.
- 데이터 중복을 최소화하고 일관성을 유지하기 위해 데이터베이스 정규화가 요구된다.
- 읽기보다는 쓰기 작업에 중점을 두고 있으며, Consistency를 중시한다.
- ATM 거래, 전자상거래, 예약 시스템 등에 활용된다.
② OLAP
- 주로 데이터 분석의 목적으로 사용된다.
- 대규모 Data Set에 대한 복잡한 Query 및 분석을 수행한다.
- 동시 사용이 거의 일어나지 않기 때문에 트랜잭션 간의 높은 격리 수준이 요구되지 않는다.
- 쓰기 작업에 비해 읽기 작업이 훨씬 더 빈번하게 일어나며, 대량의 데이터에 대한 분석을 중시한다.
- BI(Business Intelligence), Data Warehouse 등의 데이터분석 시스템에 활용된다.
2. Hadoop
1) 개념
Hadoop은 대규모 Data Set을 분산 처리하기 위한 Apache의 소프트웨어 프레임워크이다. 대용량의 데이터를 분산시켜 효율적으로 분석하기 위해 클러스터링(여러 대의 컴퓨터가 분담하여 일을 처리하는 방식)을 사용한다. 이처럼 대용량 데이터를 분산 환경에 저장하고 처리하는 방식을 Distributed Processing이라 한다.
2) 구성 Module
Hadoop에는 총 4개의 Module이 존재한다.
① Hadoop Common
- Hadoop의 핵심 라이브러리와 유틸리티를 제공한다.
② HDFS
- Hadoop Distributed File System의 약어이다.
- 여러 컴퓨터에 대용량 파일을 저장하기 위한 분산 파일 시스템이다.
③ Hadoop YARN
- Hadoop 클러스터의 자원 관리 및 작업 스케줄링을 담당하는 Framework이다.
④ Hadoop M/R
- Map Reduce의 약어로, Map은 Problem을 Sub-Problem으로 분할하는 것을 의미하고, Reduce는 Sub-Problem 별 결과를 취합하는 것을 의미한다.
- 데이터의 병렬 분산 처리를 위한 프로그래밍 모델이다.
- 저장된 분산 파일을, 분산된 서버의 리소스(CPU, Memory)를 이용하여 빠르게 분석한다.
3) 장점
Hadoop은 전통적인 RDB에서 처리하기 어려울 정도로 큰 규모의 데이터를 다뤄야 할 때 유용하다.
- TB~PB(2^40~2^50 바이트) 정도의 Big Data도 문제 없이 저장하고 처리할 수 있다.
- Horizontal Scaling(Scale-Out) 방식을 사용하므로, Computing Node 수에 비례하여 Computing Power가 증가한다.
- Data Replication 및 Recovery에 용이하여 Fault Tolerance 하다(내결함성이 높다).
- Static Schema를 요구하지 않아, Flexibility가 높다.
- Open Source이면서 상용 HW이므로, 비용 부담이 적다.
4) RDBMS와의 비교
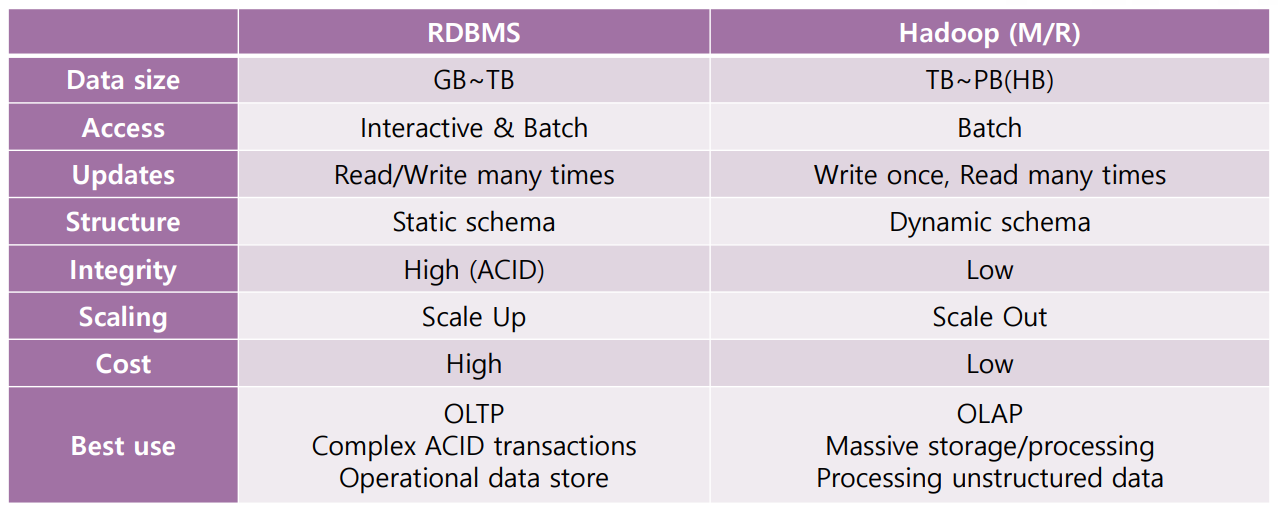
Hadoop은 NoSQL과 마찬가지로 BASE 속성을 갖기 때문에 Integrity는 낮은 편이다. Hadoop의 중요한 특징 중 하나는 Scale-Out 방식으로 확장된다는 것이다. Scale-Up(Vertical Scaling)보다 Scale-Out이 유리한 이유는, Scale-Up 방식의 확장에서는 투자 비용과 성능이 비례하지 않기 때문이다. 다시 말해 성능을 10배 올리기 위해, Scale-Out에서는 비용을 10배 증가시키면 되지만, Scale-Up에서는 비용을 수십 배 증가시켜야 한다.

4) 생태계
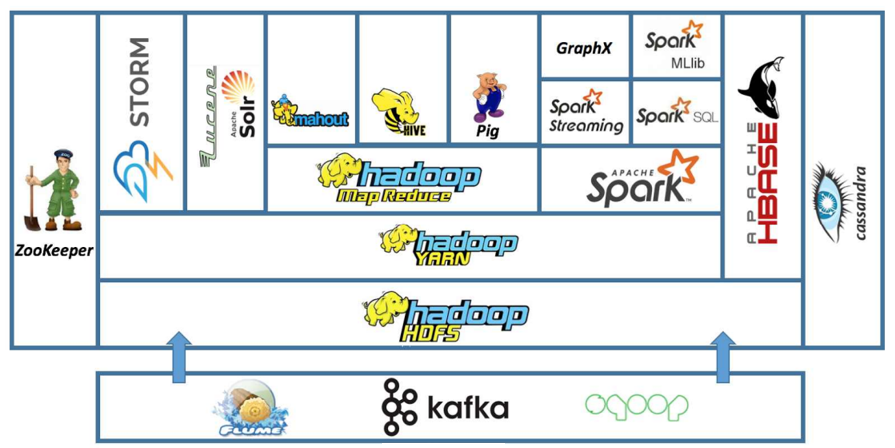
① Flume, Sqoop, Kafka
- Data Collection에 사용되는 시스템이다.
- Flume은 Log 또는 실시간 데이터 수집에 사용되고, Sqoop은 RDBMS와 Hadoop 간의 데이터 전송 및 변환(Data Exchanger)에 사용되며, Kafka는 대용량 실시간 데이터 스트림을 처리하기 위해 사용된다.
② HDFS
- 수집된 대용량 데이터를 분산 저장한다.
③ YARN
- Hadoop 클러스터의 자원 관리 및 작업 스케줄링을 담당한다.
- Map Reduce나 Spark 등의 애플리케이션이 YARN 위에서 실행된다.
④ Map Reduce, Spark
- 대규모 데이터 처리를 위한 분산 처리 프레임워크로, 데이터를 처리하고 분석하는 데 사용된다.
⑤ HBase
- NoSQL 데이터베이스로, 대용량 Data Set을 실시간으로 읽고 쓰기 위한 목적으로 사용한다.
- Hadoop의 HDFS 위에 구축된다.
⑥ Apache HIVE, Apache PIG, Apache ZooKeeper
- Map Reduce의 Framework이다.
3. Big Data를 처리하는 방법
1) 대용량의 데이터를 저장하는 방법
데이터의 크기가 매우 큰 경우, 하나의 서버에 저장할 수 없다.
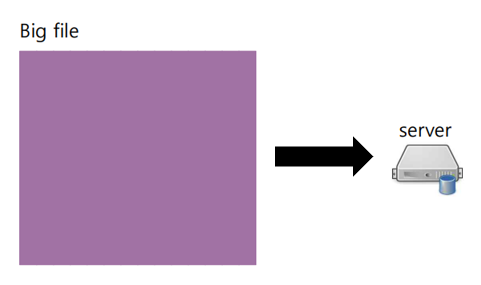
따라서, 적당한 크기의 Block으로 분할하여 여러 대의 컴퓨터에 나누어 저장하는 방식을 사용한다. 이때, Data Block을 가지고 있는 서버 각각을 Data Node라고 한다.
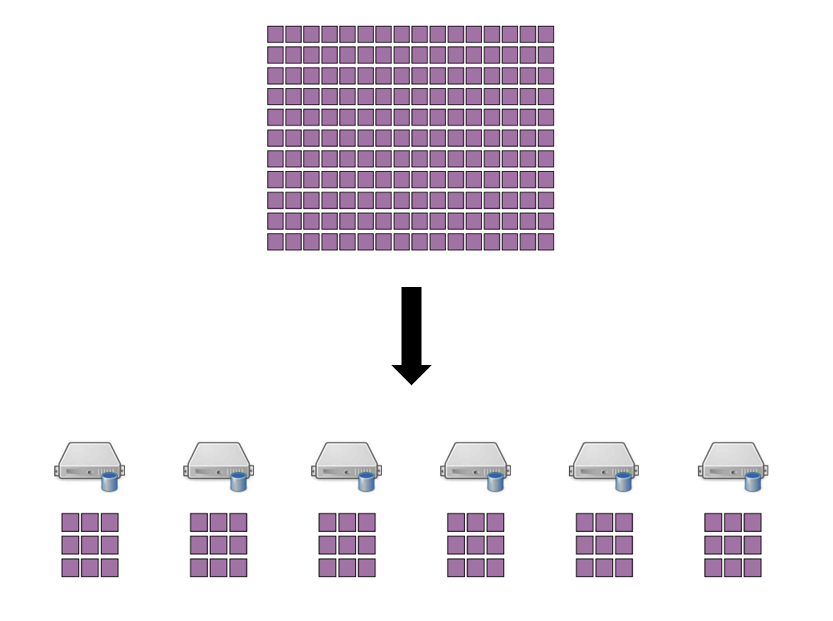
2) Data Block의 위치를 알아내는 방법
이와 같은 방식을 사용하기 위해선, 어떤 서버에 어떤 Data Block이 저장되어 있는지 알고 있어야 한다. 그러므로 이러한 정보를 관리하는 Name Node가 별도로 필요하다.
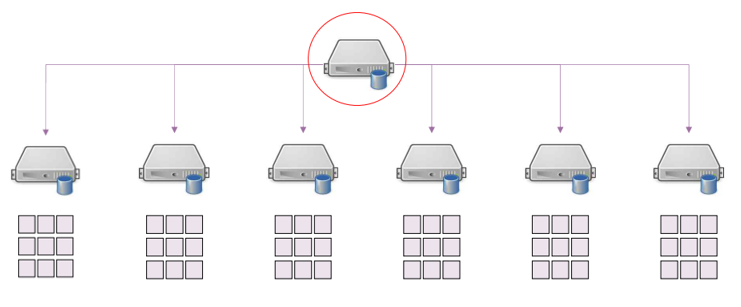
3) SPoF(Single Point of Failure)를 해결하는 방법
위와 같은 구조의 치명적인 단점은 하나의 노드만 고장나도, 전체 시스템에 문제를 초래할 수 있다는 것(SPoF)이다. 이러한 문제를 해결하기 위해서 데이터 블록을 Replication(각 서버에 중복해서 저장)한다.
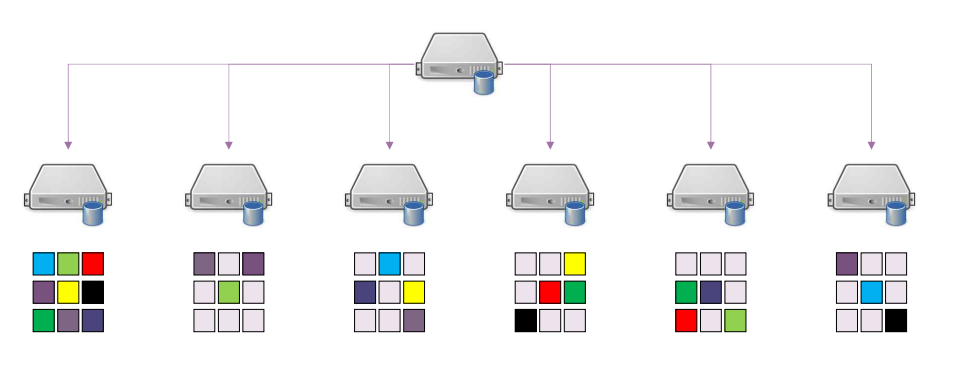
Data Block을 중복해서 저장하기 때문에 한 대의 컴퓨터가 고장나더라도, 크게 문제가 되지 않는다.
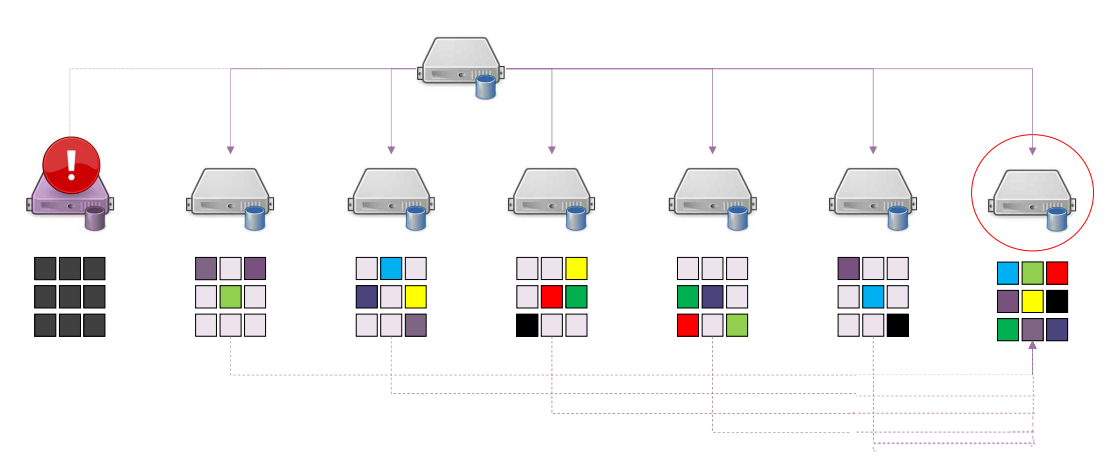
하지만, 여전히 Name Node로 인한 SPoF 가능성이 존재한다. 당연히 이에 대해서도 여러가지 해결책이 있는데, 여기서는 생략하기로 한다.
4. Data Mining
1) 정의
대규모 데이터로부터 데이터의 패턴이나 규칙 등의 유용한 정보를, 자동으로 발견하는 방법으로, Knowledge Discovery라고도 한다.
2) 구분
① Association Rules
- Data Set에서 아이템 간의 관계를 찾아내는 기법이다.
- X가 발생할 때, Y가 어느 정도의 빈도로 발생하는지 등을 분석한다.
② Clustering
- 비슷한 속성이나 특성을 가진 데이터 포인트들을 그룹으로 나누는 기법이다.
- Unsupervised Learning 방식으로, 학습용 데이터가 없다.
- Hierarchical Clustering(데이터를 계층구조로 나타내어 군집화)과 Partitive Clustering(데이터를 서로 교집합이 없는 부분집합으로 분할)으로 구분된다.
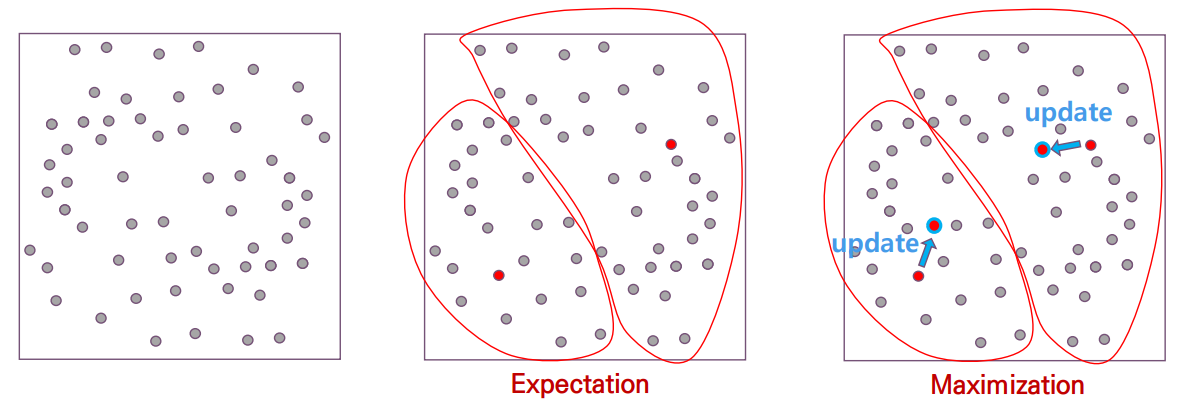
- Partitive Clustering에 사용되는 대표적인 알고리즘으로, EM(Expectation-Maximization) 알고리즘이 있다. EM 알고리즘은 E 단계와 M 단계를 반복적으로 수행하는 Iterative Optimization Algorithm이다.
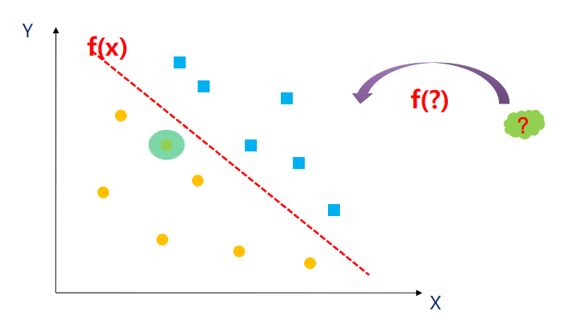
③ Classification
- 데이터를 미리 정의된 클래스 또는 범위로 분류하는 기법이다.
- Supervised Learning 방식으로, 학습용 데이터가 필요하다.
- 어떤 증상을 갖는 환자를 암환자로 분류할 수 있는지 등을 분석한다.
- SVM(Support Vector Machines)과 Decision Tree 알고리즘을 사용한다.
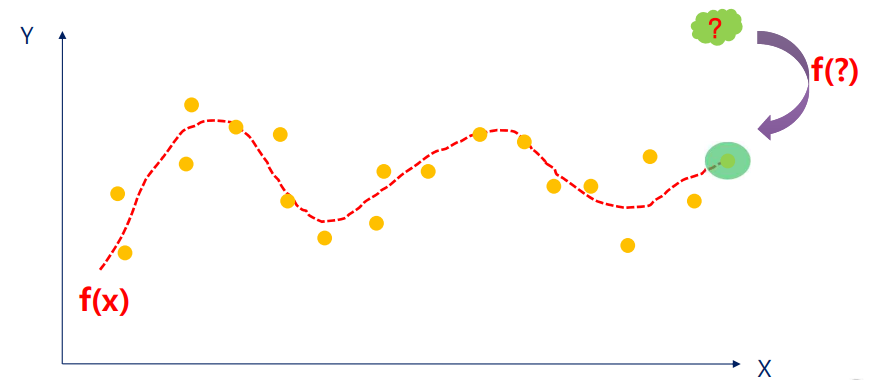
④ Regression
- 데이터의 패턴을 파악하여, 입력 변수 변화에 따른 출력 변수 변화를 예측하는 기법이다.
- Supervised Learning 방식으로, 학습용 데이터를 필요로 한다.
- Categorical Value(ex: Yes/No)를 취급하는 Classifiaction과 달리, Numerical Value를 취급한다.
- 어떤 증상을 갖는 환자의 기대 수명 등을 분석한다.
5. SVM과 Decision Tree
1) SVM(Support Vector Machines)
SVM은 데이터를 n차원의 공간으로 매핑하여 클래스 간의 경계를 찾고, 이를 최대화하는 초평면을 찾아내는 알고리즘이다. SVM은 두 클래스 간의 Decision Boundary를 찾는 방식이므로, 두 클래스 사이의 Margin(거리)이 커질수록 Classifiacation의 정확성이 향상된다. Decision Boundary가 최대일 때, Decision Boundary와 가장 가까이에 위치한 Data Point를 Support Vector라고 한다.
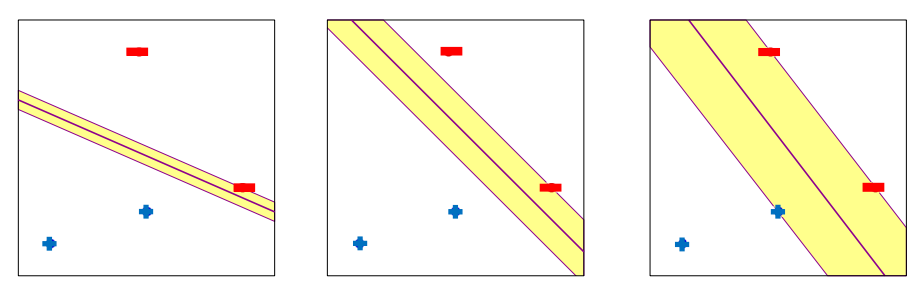
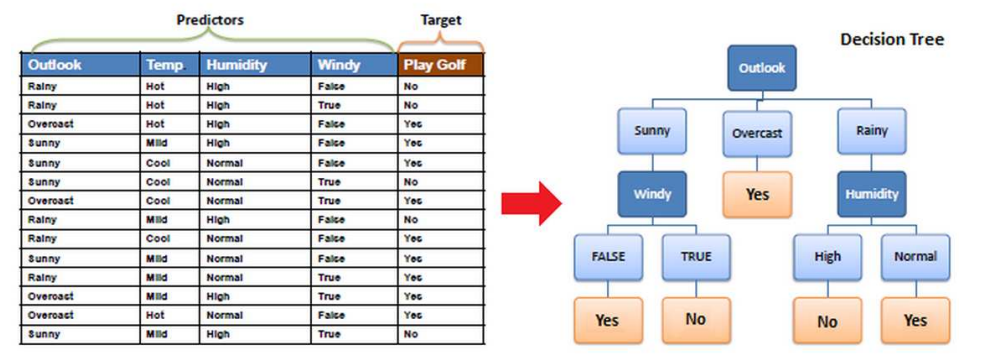
2) Decision Tree
Information Gain이 높은 순으로 분류한다. 여기서 Information Gain이란 Entropy의 감소량으로, Selectivity와 비슷한 개념이다.
6. Precision과 Recall
1) Precision
Precision(정밀도)은 Positive로 예측한 샘플 중 실제 Positive인 샘플의 비율을 나타낸다. 이를 공식으로 나타내면, Precision = TP / (TP + FP)이다. 여기서 TP는 True Positive(예측과 실제 모두 양성), FP는 False Positive(예측은 양성, 실제는 음성)를 의미한다. 즉, 양성이라고 예측한 모델이 얼마나 정확한지를 알려주는 척도이다.
2) Recall
Recall(재현율)은 실제 Positive인 샘플 중에서 모델이 정확히 Positive로 예측한 샘플의 비율을 나타낸다. 이를 공식으로 나타내면, Recall = TP / (TP + FN)이다. 여기서 FN은 False Negative(예측은 음성, 실제는 양성)를 의미한다. 즉, 모델이 얼마나 많은 실제 양성 샘플을 찾아냈는지 알려주는 척도이다.
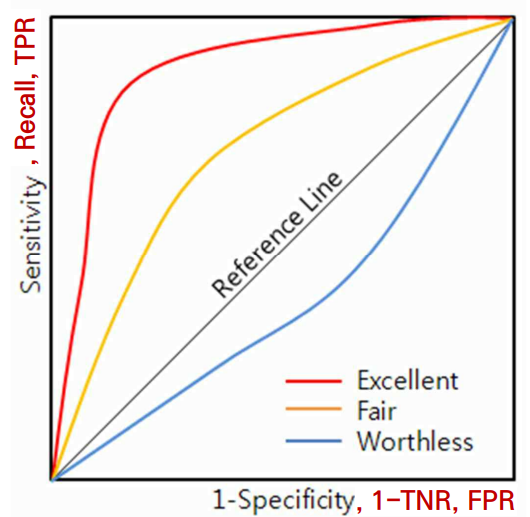
3) ROC Curve
ROC Curve란, Receiver Operating Characteristic Curve의 약어로, 분류 모델의 성능을 시각적으로 평가하기 위해 사용하는 그래프이다. ROC Curve는 Specificity(x축)와 Sensitivity(y축) 간의 관계를 나타낸다.
Specificity는 FPR(False Positve Rate) = 1-TNR(True Posivie Rate)이고, Sensitivity는 TPR(True Positve Rate) = Recall이다. 즉, (0, 0)에서 (1, 1)로 향하는 곡선을 그릴 때, x 값이 느리게 증가할수록, y 값이 빠르게 증가할수록 모델의 성능이 우수하다.

모델의 성능을 평가하는 지표로 AUC를 사용한다. AUC는 Area Under Curve로, ROC 곡선 아래의 면적이다. AUC의 값이 1에 가까울 수록 성능이 좋은 것으로 평가된다.