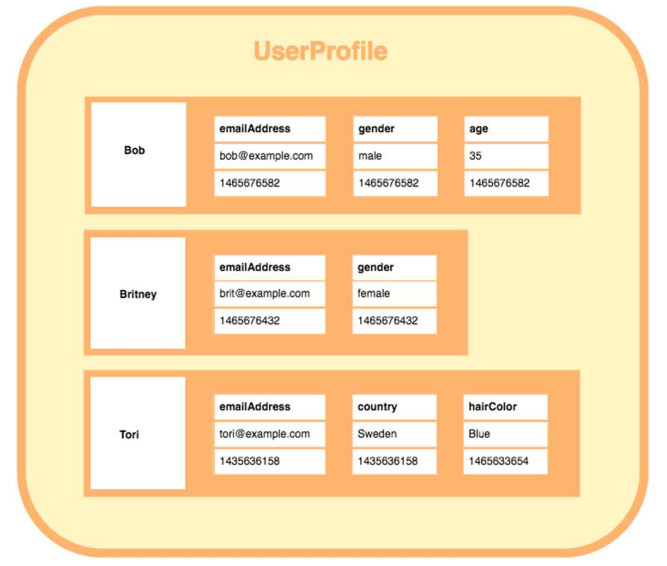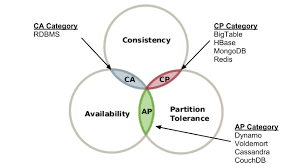
1. 개념
1) 정의
NoSQL의 해석을 둘러싸고 아래와 같은 견해가 존재한다.
- No SQL : 말그대로 No SQL로 SQL이 아니다.
- None-Relational Database: 관계형 DB 모델이 아니다.
- Not Only SQL: SQL 뿐만이 아니다.
이 중 가장 일반적인 해석은 Not Only SQL인데, 이는 NoSQL이 단순히 기존 RDBMS가 가지고 있는 특성뿐만 아니라 다른 부가적인 특성을 지원한다는 의미이다.
2) RDBMS와의 차이점
NoSQL은 ACID를 제공하지 않는(완화하는) 대신 확장성과 성능이 매우 뛰어난 Distributed Database(분산형 데이터베이스)이다. 즉, NoSQL은 수천 ~ 수만 대의 서버를 연결해 데이터를 저장 및 처리하는 구조인 것이다.
반면 RDBMS는 하나(많아도 수십 개 수준)의 고성능 머신에 데이터를 저장하는 구조를 갖는다. RDBMS가 이러한 구조를 가질 수 밖에 없는 이유는 Relational Data Model, ERD, Schema, Transaction, ACID, Concurrency Control, Log 등이 필수적으로 요구되기 때문이다. 이와 같은 RDBMS의 구조는 아래와 같은 문제를 발생시킬 수 있다.
- Scalability: 수만 개의 분산 서버에 설치하고 관리하는 일이 어렵다.
- Performance: 초당 수만 개의 갱신 연산을 처리하기 어렵다.
- Static Schema: (스키마가 없더라도) 정형화된 스키마가 반드시 필요하다.
- Reliability: 서비스에 따라 Reliability보다 Speed가 더 중요할 수 있음에도, Reliability를 우선시 한다.
- Persistency: 마찬가지로 Persistency보다 Speed가 더 중요할 수 있음에도, Persistency를 우선시 한다.
- Complexity: RDBMS는 단순한 모델을 사용하는 경우에는 부적합할 수 있다.
NoSQL은 전통적인 RDBMS의 특성을 대부분 사용하지 않음으로써, 대량의 데이터를 빠르게 처리한다. 즉, Consistency보다 Performance를 우선시하는 방식의 Database인 것이다.
3) 장단점
① 장점
- 스키마가 유연하다. (완성된 테이블에 column을 추가하는 일이 어렵지 않으며, A와 B가 갖는 attribute가 얼마든지 다를 수 있다.)
- 설치 및 관리가 매우 쉽고 빠르기 때문에 replication(복제)이 용이하다.
- Massive Scaling(대규모 확장)에 용이하다.
- Eventual Consistency(완화된 일관성)를 사용하는 대신, Performance와 Availability가 크게 향상된다.
② 단점
- (SQL과 같은) 표준 Query Language가 부족하다.
- Eventual Consistency로 인해 ACID가 보장되지 않는다.
※ ACID와 BASE
RDBMS의 ACID와 비견되어, NoSQL은 BASE 속성을 가진다. BASE는 Bascially Availability(가용성 중시), Soft state(일시적으로 일관성이 없는 상태를 허용), Eventual consistency(언젠가 일관성을 되찾음)의 약어이다. '산'을 의미하는 ACID에 반대되는 개념으로, '염기'를 의미하는 BASE를 사용한 것이다.
2. 분류
1) 대표적인 NoSQL 시스템
① Big Table
- Google의 독점 NoSQL 시스템
- Column-Based 또는 Wide Column Store 방식을 사용
② Dynamo DB
- AWS에서 제공하는 NoSQL 시스템
- Key-Value 데이터베이스
③ Cassandra
- Facebook에서 제공하는 NoSQL 시스템
- Key-Value와 Column-Based 방식을 모두 사용
④ Mongo DB 및 Couch DB
- Document Stores(JSON이나 BSON과 같은 문서 형식으로 데이터를 저장하는 방식) 방식을 사용
⑤ Neo4J 및 GraphBase
- Graph based(복잡한 관계를 Graph 구조를 사용하여 저장하는 방식) NoSQL 시스템
2) 카테고리에 따른 분류
① Documnet Based NoSQL
- Mongo DB
- Couch DB
② Key Value Store
- Redis
- Dynamo DB
- Cassandra
- Oracle NoSQL Database
③ Column Based 및 Wide Column Store
- HBase
- Cassandra
- Big Table
④ Graph Based NoSQL
- Neo4J
3. CAP 이론
CAP 이론은 분산 데이터 스토리지 시스템에서 아래의 세 가지 주요 속성을 모두 만족하는 시스템이 존재하지 않음을 증명한 정리이다.
- Consistency(일관성): 모든 노드가 같은 순간에 같은 데이터를 볼 수 있다.
- Availability(가용성): 모든 요청에 대해 항상 성공 또는 실패의 응답을 반환해야 한다. 즉, 모든 요청에 대해 적어도 하나의 노드가 응답해야 한다.
- Partition Tolerance(분할 내성): 메시지가 손실되거나 시스템 일부가 망가지더라도 시스템은 계속 동작해야 한다.
이를 그림으로 나타내면 아래와 같다.
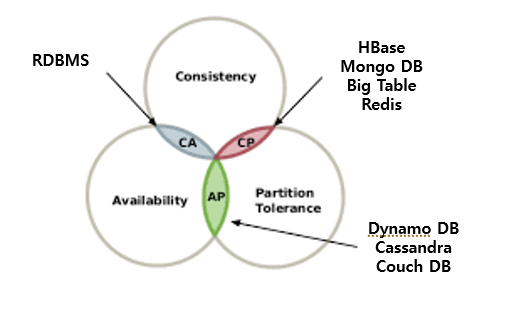
놀랍게도 CAP 벤다이어그램에서 공통 교집합은 존재하지 않는다. RDBMS는 언제나 Partiton Tolerance를 만족하지 않고, NoSQL은 Consistency를 포기하는 대신 Availability를 향상시키는 방식이기 때문에 이러한 결과가 나타난다.
4. 기법
1) Sharding
Sharding은 대량의 데이터를 처리하기 위해 데이터를 여러 서버 또는 노드로 분산하는 기술로, 데이터베이스의 성능 및 확장성 향상에 도움을 준다. Sharding의 주요 아이디어는 데이터를 여러 파티션으로 나누고, 각 파티션을 서로 다른 노드에 저장하여 데이터베이스 부하를 분산하는 것이다. 이로써 Query를 처리할 때, 각 노드가 데이터베이스의 일부분만 처리하면 되기 때문에 응답 시간은 줄어들고 처리량은 늘어나게 된다. Sharding은 크게 두가지 방식으로 구분된다.
① Range Sharding
- 데이터의 특정 범위에 기반하여 데이터를 분할한다.
- 연속된 값의 일정 구간에 속하는 데이터를 특정 파티션에 할당한다.
- range query가 자주 사용되고, 데이터 분포가 균일한 경우에 유리하다.
② Hash Sharding
- 해시 함수 값을 기반으로 데이터를 분할한다.
- 반환된 해시 값에 따라 데이터가 특정 파티션에 할당된다.
- exact query 또는 random access가 자주 발생하고, 데이터 분포가 불균일한 경우에 유리하다.
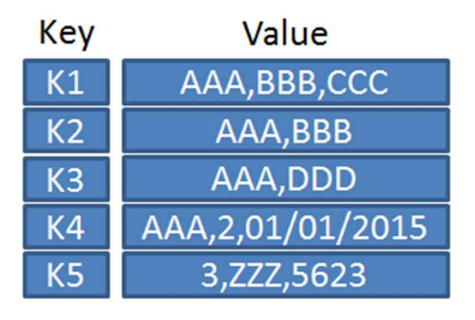
2) Key-Value
말그대로 {key : value} 쌍으로 데이터를 저장하는 방식이다. 단순한 구조이기 때문에 속도가 빠르며, 분산 저장에 용이하다. Redis, Dynamo DB, Oracle NoSQL Database, Cassandra 등이 여기에 해당한다.
3) Column-Based 및 Wide Column
① Column-Based(Oriented) Database
- 데이터를 행이 아닌 열 단위로 저장하는 방식을 사용한다.
- 컬럼 단위 분석에 용이하다. (사람들의 평균 나이를 구하는 등)
- 압축 및 병렬처리에 유리하다.
② Wide Column Database
- Row마다 다른 attribute, 다른 수의 스키마를 가질 수 있다.
- 대량의 데이터에 대한 압축, 분산처리, 집계처리, 확장성, Query 성능이 매우 뛰어나다.
- Cassandra, HBase, Big Table 등이 여기에 해당한다.