📌 시퀀스-투-시퀀스(Sequence-to-Sequence, seq2seq)
- 시퀀스 투 시퀀스 : 이력된 시퀀스로부터 다른 도메인의 시퀀스를 출력하는 모델
- ex. 챗봇(질문-대답), 번역기(입력-번역결과), 요약, STT(Speach to Text)
1. 시퀀스-투-시퀀스(Sequence-to-Sequence)

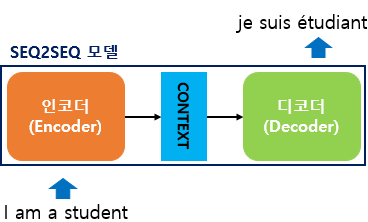
- 내부 : 인코더 + 디코더
- 인코더 : 입력 문장의 모든 단어들을 순차적으로 입력 받은 뒤에 마지막에 이 모든 단어 정보들을 압축해서 하나의 벡터(컨텍스트 벡터, context vector)로 만든다
- 디코더 : 컨텍스트 벡터를 받아서 번역된 단어를 한 개씩 순차적으로 출력
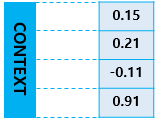
(위의 사이즈는 4지만 실제 현업에 사용되는 것은 수백 이상의 차원)
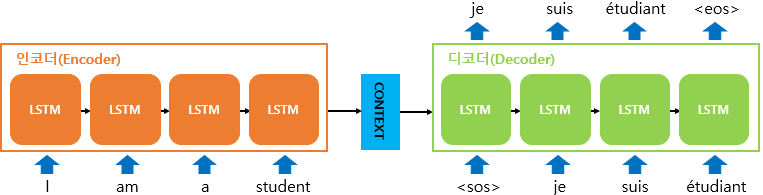
-
두 개의 RNN 아키텍쳐 (입력 RNN 셀 : 인코더, 출력 RNN 셀 : 디코더)
-
인코더
- 입력 : 문장을 단어 단위로 토큰화하여 쪼갬, 토큰들은 각 시점의 입력이 됨
- 인코더가 입력을 받은 뒤 마지막 시점의 은닉 상태(컨텍스트 벡터)를 디코더로 넘겨줌
- 컨텍스트 벡터는 디코더 셀의 첫번째 은닉 상태가 된다
<테스트 과정>
- 디코더
- 초기 입력 : 문장을 시작을 의미하는 심볼 <sos>
- 첫번째 시점 : <sos> 입력 시 다음에 등장할 확률이 높은 단어 예측 (je)
- 두번째 시점 : 입력된 단어 je 로부터 다음 올 단어 suis 예측. suis는 다음 시점의 입력
- 세번째 시점 : 입력된 단어 suis 로부터 다음 올 단어 etudiant 예측. etudiant는 다음 시점의 입력
- 마지막 시점 : 문장의 끝을 의미하는 <eos>를 다음 단어로 예측한다
<훈련 과정>
- 디코더
- 입력 : 컨텍스트 벡터, 실제 정답인 <sos> je suis etudiant 이 들어갔을 때 출력 : je suis etudiant <eos> 가 나와야 한다고 정답을 알려주면서 훈련

- 입력 단어들은 워드 임베딩을 통해 텍스트를 벡터로 바꾼 임베딩 벡터
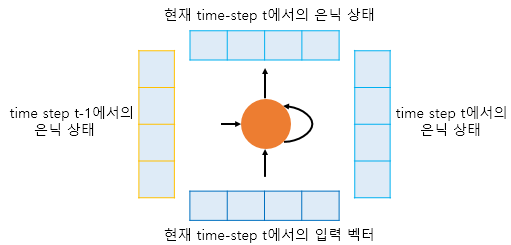
- 인코더
- 이런 구조로 과거부터 모든 은닉 상태의 영향을 누적
- (t-1)시점의 은닉상태와 t 시점의 입력 벡터를 입력으로 받아서
- t 시점의 은닉상태를 만듬
- t 시점의 은닉상태를 또 다른 은닉층이나 출력층 존재할 경우 보내준다.
- 컨텍스트 벡터 : 인코더의 마지막 셀의 은닉 상태. 모든 단어 토큰 정보 요약하고 있음
.png)
-
디코더
- 첫번째 RNN 셀 : 현재의 입력 값인 <sos> + 컨텍스트 벡터 -> 다음 단어 예측
- 두번째 RNN 셀 : 첫번째 시점에서 예측한 값 + 첫번째 시점의 은닉상태 -> 두번째 시점의 출력(예측값)
-
각 층에서 출력으로 나올 수 있는 여러 값들 중 하나 예측하여 출력하기 위해
-
각 시점에서 소프트맥스함수를 통해 확률값 계산하여 출력 단어 결정
📌 BLEU Score(Bilingual Evaluation Understudy Score)
BLEU(Bilingual Evaluation Understudy) : 자연어 처리의 성능 측정을 위한 평가 방법
1. BLEU(Bilingual Evaluation Understudy)
- BLEU : 기계 번역 결과와 사람이 직접 번역한 결과가 얼마나 유사한지 비교하여 번역의 성능을 측정 (n-gram 기반)
- 언어에 구애 X, 계산 속도 빠름, 높을수록 성능이 더 좋음을 의미
1) 단어 개수 카운트로 측정하기(Unigram Precision)
- 한국어 문장 입력, 영어로 번역된 문장 Candidate1, 2

- ca 1, 2 을 ref 1,2,3 와 비교하여 성능 측정
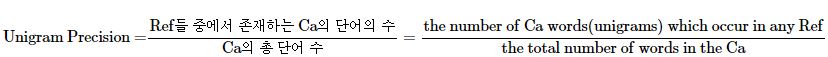
- 유니그램 정밀도(Unigram Precision)
- 가장 직관 : ref 중 어느 하나에라도 등장한 단어 카운트해서 ca의 모든 단어 카운트의 합으로 나눠줌

2) 중복을 제거하여 보정하기(Modified Unigram Precision)

- 유니그램에 의하면 7/7=1 이라는 높은 값을 가짐-> 보정 필요
- 이미 한번 매칭된 적이 있었는지 고려해야함(중복)
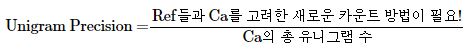
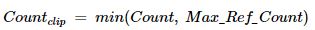
- Max_Ref_Count : 유니그램이 하나의 ref에서 최대 몇번 등장했는지 카운트
- Max_Ref_Count 가 기존의 단순 카운트 값보다 작은 경우 최종 카운트 값을 Max_Ref_Count로 대체

- 보정된 유니그램 정밀도(Modified Unigram Precision)
- 위의 7/7=1 의 값이 2/7로 변경된다
3) 보정된 유니그램 정밀도 (Modified Unigram Precision) 구현하기
- 분모 : count 함수 (유니그램을 카운트)
- 분자 : countclip 함수 (보정된 유니그램 카운트)
4) 순서를 고려하기 위해서 n-gram으로 확장하기
- 빈도수 접근 = 순서를 고려하지 않는다

-
ca3 : ca1의 모든 유니그램을 순서를 섞어 임의의 문장만듬 (유니그램 정밀도는 같다)
-> n-gram 단위로 계산하는 정밀도 도입 -
바이그램 정밀도 계산

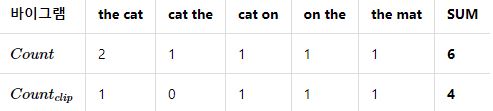
- ca2 바이그램의 count와 countclip (정밀도 - ca1 : 0 ca2 : 4/6)


- 유니그램의 정밀도 식을 n-gram으로 일반화

- BLEU는 p1~pn을 모두 조합하여 사용
5) 짧은 문장 길이에 대한 패널티(Brevity Penalty)
-
Ca의 길이에 BLEU의 점수가 과한 영향을 받을 수 있다는 문제점
-
Example 1에서 Candidate4 : it is 라는 짧은 문장을 추가하면 제대로 번역된 문장이 아님에도 유니그램/바이그램 정밀도가 모두 1이라는 결과가 나온다.(문장이 짧아서)
-> 점수에 패널티 줘야됨 : 브레버티 패널티(Brevity Penalty) -
Ca의 길이가 Ref보다 긴 경우에도 같은 문제가 생길 수 있는지

- Ca1은 가장 많은 단어를 사용하고도 Ca2보다 좋은 번역은 아니다
- Ref의 단어를 가장 많이 사용했다 != 좋은 번역
-> 이런 경우 이미 n-gram 을 통해 패널티
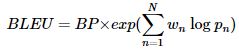
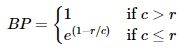
- 브레버티 패널티를 곱해줌 (줄 필요 없는 경우 BP=1)

^^~