Coursera Deep Learning Specializtion 과 Basic Machine/Deep Learning with Tensorflow(python)-모두를 위한 딥러닝 및 세종대학교 최유경교수님의 인공지능 강의를 바탕으로 학습을 해보았습니다.
Machin Learning vs Deep Learning Artificail Itenlligence
" Artificail Intelligence (A.I)란? "
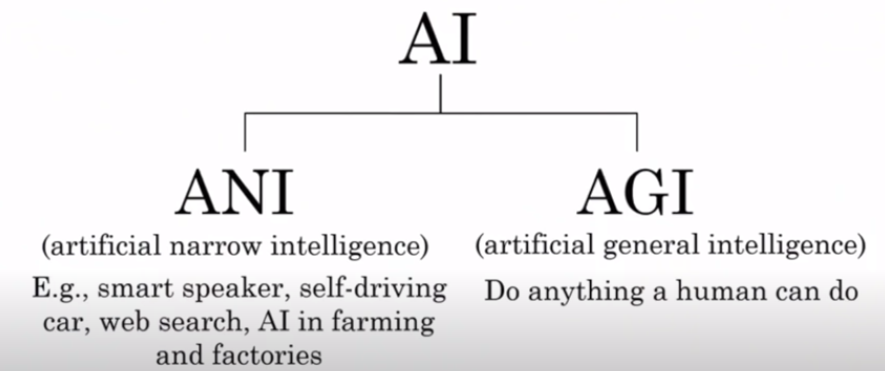
AI는 Narrow A.I와 General A.I로 나눌 수 있습니다.
SF영화에나 나올법한 A.I는 General A.I를 뜻합니다. General A.I는 인간이 하는 행동을 할 수 이쏙, 혹은 인간보다 더 뛰어난 능력을 가질 수 있습니다. 즉, General A.I는 대화도,게임도,판단도 General하게 인간이 할 수 있는 것을 모두 할 수 있습니다.
하지만 현재 산업은 Narrow A.I를 다루고있습니다 .Narrow A.I는 한 가지의 기능만 할 수 있는 A.I 입니다. 말 그대로 집중하는 범위가 좁은 것(narrow)입니다. (ex. FaceBook얼굴 인신 기능-오직 이 기능에만 특화된 A.I)
이 narrow A.I는 학습을 통해 어떤 물체가 사람의 얼굴인지 식별할 수 있습니다. 그렇다면 어떻게 A.I를 학습시킬까요?
이 때 머신 러닝이 등장합니다.
" Machine Learning 이란? "
머신 러닝은 A.I를 달성하기 위한 수단 입니다. 그렇다면 기계들은 어떻게 학습을 할까요?
여러가지 방법이 있지만 대표적으로 2가지가 있습니다.

1. Supervised Learning
'지도 학습' 이라는 말 처럼 Input Data와 그에 대한 정답에 해당하는 Label(또는 Class)정보를 사람이 직접 입력해주어야 합니다.
즉 집값 예측, 성별 예측, 기온 예측 등 정확한 값을 예측하는 것 까지 모두 Supervised Learning의 범주에 속합니다. 이를 맞춰야 하는 'target value(label)'가 있는 것이라고 말할 수 있습니다. Supervised Learning은 하위 범주에 3가지가 있습니다.
Regression - continuous :
집값 예측, 기온 예측과 같이 예측값이 Continuous한 것을 말합니다. Binaray Cloassification : 인물 사진으로 성별 예측, 합격여부 예측과 같이 예측값이 두 개인 경우를 말합니다. Multi-Class classification - discrete : 로또 번호 예측, 출신 지역 예측과 같이 예측값이 세 개 이상인 경우를 말합니다.
2. Unsupervised Learning
supervised Learning과 반대되는 개념으로, 맞춰야 하는 'targer value(label)'가 없는 것을 말합니다.
처음 들으면 맞추는 것이 없는데 뭘 학습을 하려나...라고 생각을 할 수 있겠지만, 만약 100명의 사람들을 비슷한 사람들끼리 3개의 묶음으로 묶어야 한다고 해보면 우리는 각자 1~3으로 Labeling된 사람들을 기준으로 Labeling되지 않은 사람들을 묶는 것이 아니라, 아무런 Label없이 이들의 특성을 종합적으로 파악해서 묶어야 할 것입니다.
이런 경우와 같이 Label이 없는 것에 대한 문제를 해결하는 것을 Unsupervised Learning이라고 합니다.
하지만 이것을 조금 더 고도화된 알고리즘으로 성능을 개선시키기 위한 것중에 하나가 요즘 각광을 받고있는 '딥러닝'입니다.
" Deep Learning 이란? "
딥러닝은 머신러닝을 달성하기 위한 하나의 기법입니다.
딥러닝 또는 심층 신경망 기법이라고 하는 이유는 이것이 'neural network'를 이용하기 때문인데요. 즉, 우리의 '뇌'처럼 작동하는 알고리즘입니다. 누가 맛있는 것을 먹고 있다면 그것을 우리 대뇌피질에서 자극 신호를 받아 화학적인 작용을 해 머릿속에 있는 깊은 곳까지 전달하는 과정들을 물리적으로 시물레이션 한 기법이라고 할 수 잇습니다.
아주 많은 데이터가 필요하고, Intensive 한 Process라 많은 processing Power가 필요합니다. 그래서 구글, 테슬라와 같은 거대 기업들의 주력이기도 합니다. 기술이 발전할수록 data가 점차 많아지고 있으며 CPU, GPU 등 Computation 능력이 기하급수적으로 발전하고 있고, 더욱 고도화된 Algorithm 이 많이 생겨 나옴으로써 딥러닝이 각광을 받고 이유이기도 합니다.
Regression (회귀) 학습
x (공부 시간) y (시험 점수)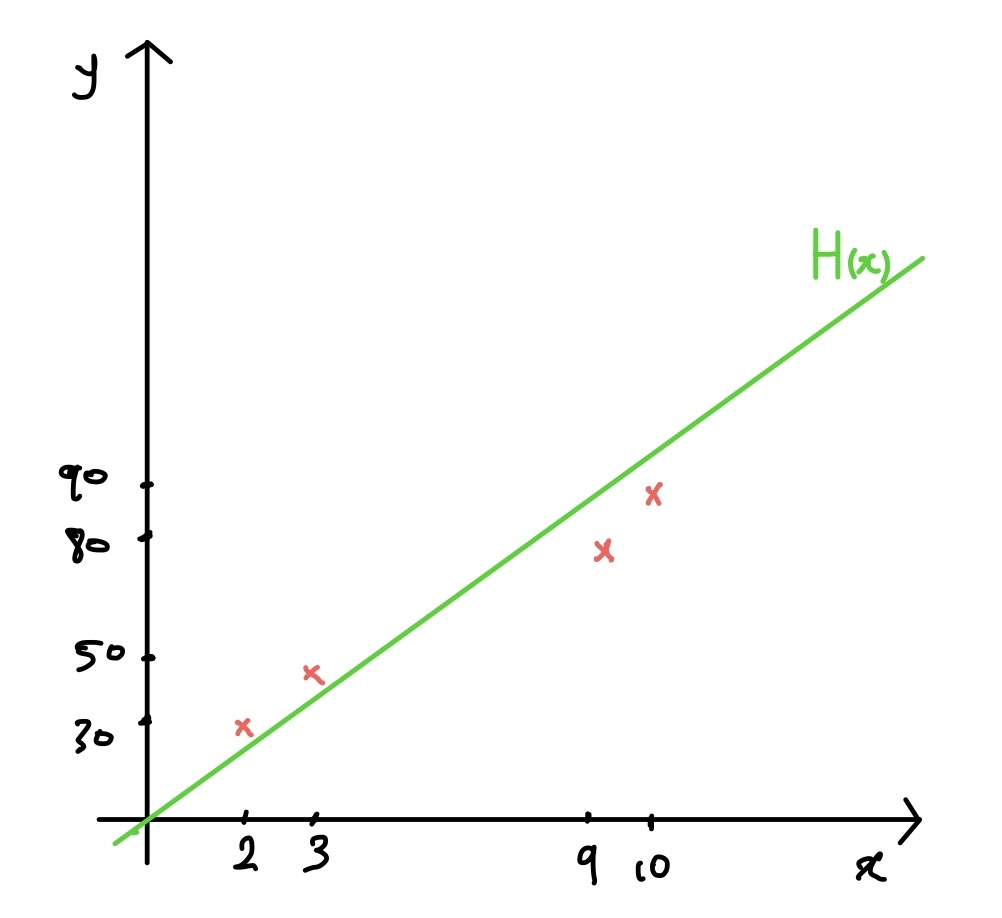
데이터 -> 함수 가정 -> 모델
이 과정을 통해 공부 시간에 대한 시험 성정 예측 선형 회귀 모델을 간단하게 구했습니다.
이 과정을 통해서 공부시간이 5시간일 때의 시험성적을 대충이나마 예측을 할 수 있는 예측 모델을 만든 것입니다. 조금 더 정확한 예측을 위해서라면 더 많은 양의 데이터가 필요하는 것을 알 수 있습니다.
Deep Learning Model의 평가

저의 예측 모델에서 측정된 값과 실제 값과의 차이를 Loss혹은 Cost라고 합니다. 그래서 모든 loss값들의 합을 데이터의 수 즉, m으로 나눈 값이 작을 수록 측정한 예측 모델과 같을 확률이 높아집니다. 더 정확도가 높은, 다시말해서 좋은 모델이란 Training Data와의 Distance의 합이 Cost Function이며 이 수치가 작은 모델이라고 할 수 있습니다.
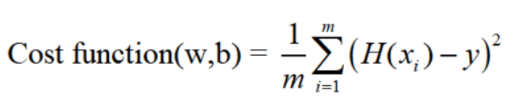
Cost Function은 위와 같이 나타낼 수 있는데요. 이때 H(x)는 Regression model을 의미하며 w, b는 직선과 y절편입니다.
Gradient Descent Algorithm
이것은 Cost Function의 최솟값을 찾는 기법입니다.
Gradient(경사), Descent(하강) 정도의 의미 입니다.
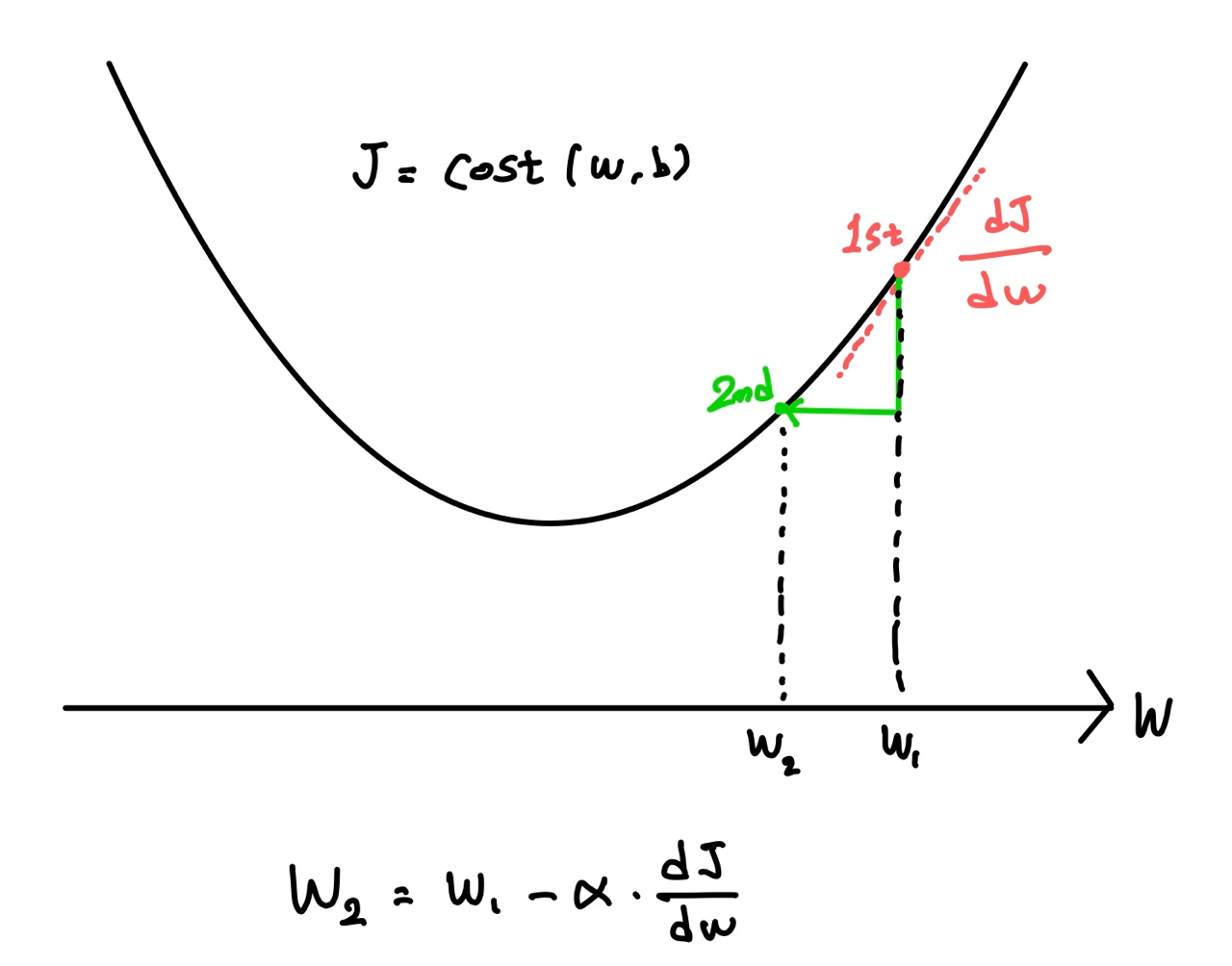
Cost Function이 위와 같이 w에 의존하는 2차 함수의 꼴이라고 가정하면, (실제로 w, b뿐만 아니라 다변수에 의존하는 n차원 공간상의 곡면이라고 이해) Gradient descent algorithm은 최솟값을 찾아가는 알고리즘입니다.
현재의 점의 접선의 기울기에 비례하게 다음 step의 다른 점을 찾고, 알파 값에 따라 계산 시간이나 오차값이 달라질 수 있습니다.
이것을 통해서 AI와 머신러닝,딥러닝의 차이점에 대하여 알아보았고, 학습에 기본 개념인 최소제곱해를 사용한 선형 회귀 방식을 배워봤습니다.
