
Callback이란?
구현해 볼 callback 함수
- ModelCheckpoint - 모델 학습 시 세이브 포인트 생성
- ReduceLROnPlateau - 학습이 더디면 Learning Rate를 조정함
- EarlyStopping - 학습이 더디면 학습을 종료해버림
1. ModelCheckpoint
ModelCheckpoint(filepath, monitor='val_loss', verbose=0, save_best_only=False, save_weights_only=False, mode='auto', period=1)
- 특정 조건에 맞춰서 모델을 파일로 저장
- filepath: filepath는 (on_epoch_end에서 전달되는) epoch의 값과 logs의 키로 채워진 이름 형식 옵션을 가질 수 있음.
예를 들어 filepath가 weights.{epoch:02d}-{val_loss:.2f}.hdf5라면, 파일 이름에 세대 번호와 검증 손실을 넣어 모델의 체크포인트가 저장 - monitor: 모니터할 지표(loss 또는 평가 지표)
- save_best_only: 가장 좋은 성능을 나타내는 모델만 저장할 여부
- save_weights_only: Weights만 저장할 지 여부
- mode: {auto, min, max} 중 하나. monitor 지표가 감소해야 좋을 경우 min, 증가해야 좋을 경우 max, auto는 monitor 이름에서 자동으로 유추.
- 체크 포인트 저장할 위치 확인 -
!pwd
>> /kaggle/working- CallBack함수 적용 -
from tensorflow.keras.callbacks import ModelCheckpoint
model = create_model()
model.compile(optimizer=Adam(0.001), loss='categorical_crossentropy', metrics=['accuracy'])
mcp_cb = ModelCheckpoint(filepath='/kaggle/working/weights.{epoch:02d}-{val_loss:.2f}.hdf5', monitor='val_loss',
save_best_only=True, save_weights_only=True, mode='min', period=3, verbose=1)
history = model.fit(x=tr_images, y=tr_oh_labels, batch_size=128, epochs=10, validation_data=(val_images, val_oh_labels), callbacks=[mcp_cb])optimizer는 Adam을 사용하고, LearningRate는 0.001 로 초기화했다.
monitor='val_loss : 검증데이터의 loss를 모니터링 할 것이다. 이것을 기준으로 체크포인트를 잡는다.
mode='min' : 이건 모니터링 할 값이 떨어지면 좋은 것으로 보고 그 기준으로 체크 한다. 이것이 max면 높아지는 것으로 본다. 이건 loss가 아니라 accuracy를 모니터링 할 때 쓰인다.
period=3 : epoch가 3이 지날때마다 체크포인트를 저장한다.
verbose=1 : 학습할 떄 밑에 진행상황이 보이도록 한다.
0 = silent,
1 = progress bar,
2 = one line per epoch.
- epoch 10번을 진행할 동안 3번의 간격마다 그때의 loss와 accuracy를 저장할 것이다.
- 체크 포인트 결과물 확인 -
!ls -lia
total 1024
131075 drwxr-xr-x 3 root root 4096 Oct 9 12:20 .
141082764 drwxr-xr-x 5 root root 4096 Oct 9 11:49 ..
131080 drwxr-xr-x 2 root root 4096 Oct 9 11:49 .virtual_documents
131077 ---------- 1 root root 263 Oct 9 11:49 __notebook_source__.ipynb
131081 -rw-r--r-- 1 root root 343272 Oct 9 12:19 weights.03-0.40.hdf5
131082 -rw-r--r-- 1 root root 343272 Oct 9 12:20 weights.06-0.37.hdf5
131083 -rw-r--r-- 1 root root 343272 Oct 9 12:20 weights.09-0.32.hdf52. ReduceLROnPlateau
ReduceLROnPlateau(monitor='val_loss', factor=0.1, patience=10, verbose=0, mode='auto', min_delta=0.0001, cooldown=0, min_lr=0)
- 특정 epochs 횟수동안 성능이 개선 되지 않을 시 Learning rate를 동적으로 감소 시킴
- monitor: 모니터할 지표(loss 또는 평가 지표)
- factor: 학습 속도를 줄일 인수. new_lr = lr * factor
- patience: Learing Rate를 줄이기 전에 monitor할 epochs 횟수.
- mode: {auto, min, max} 중 하나. monitor 지표가 감소해야 좋을 경우 min, 증가해야 좋을 경우 max, auto는 monitor 이름에서 유추.
- CallBack함수 적용 -
from tensorflow.keras.callbacks import ReduceLROnPlateau
model = create_model()
model.compile(optimizer=Adam(0.001), loss='categorical_crossentropy', metrics=['accuracy'])
rlr_cb = ReduceLROnPlateau(monitor='val_loss', factor=0.3, patience=3, mode='min', verbose=1)
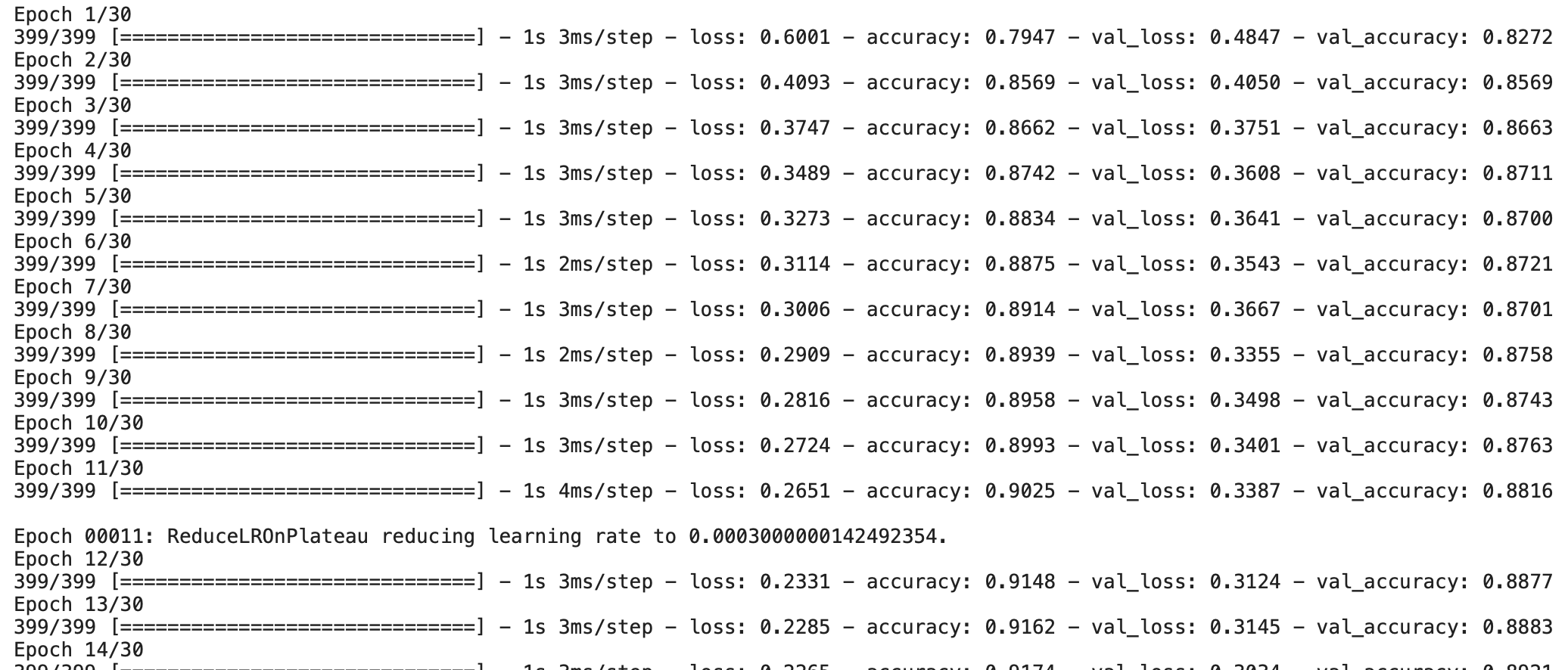
history = model.fit(x=tr_images, y=tr_oh_labels, batch_size=128, epochs=30, validation_data=(val_images, val_oh_labels),callbacks=[rlr_cb])mode='min' : 모니터링 하고있는 것은 val_loss데이터다. 이 값이 낮아질수록 더 좋은것으로 간주하고, 떨어지는 속도가 더디면 LearningRate를 조정할 것이다.
patience=3 : epoch가 3개 이전의 epoch와 비교했을 때 val_loss가 더 안좋다면 러닝레이트를 조정할 것이다. SlidingWindow를 다는 것.
factor=0.3 : 모니터링하는 값이 떨어지는 속도가 더딜 때, 즉 patience에서 정한 값만큼의 이전 학습률보다 안좋았을 때 초기에 세팅 돼있던 learningRate에 곱할 값이다. (ex : lr = 0.001 * 0.3로 업데이트)
3. EarlyStopping
EarlyStopping(monitor='val_loss', min_delta=0, patience=0, verbose=0, mode='auto', baseline=None, restore_best_weights=False)
- 특정 epochs 동안 성능이 개선되지 않을 시 학습을 조기에 중단
- monitor: 모니터할 지표(loss 또는 평가 지표)
- patience: Early Stopping 적용 전에 monitor할 epochs 횟수.
- mode: {auto, min, max} 중 하나. monitor 지표가 감소해야 좋을 경우 min, 증가해야 좋을 경우 max, auto는 monitor 이름에서 유추.
- CallBack함수 적용 -
from tensorflow.keras.callbacks import EarlyStopping
model = create_model()
model.compile(optimizer=Adam(0.001), loss='categorical_crossentropy', metrics=['accuracy'])
ely_cb = EarlyStopping(monitor='val_loss', patience=3, mode='min', verbose=1)
history = model.fit(x=tr_images, y=tr_oh_labels, batch_size=128, epochs=30, validation_data=(val_images, val_oh_labels), callbacks=[ely_cb])
patience=3 : 위에서와 같이 이전 세단계 epoch만 보고 스탑할지 말지 정하는 것이다. 즉 3번은 참다가 그때도 진전이 없으면 스탑하게 된다.
모든 Callback함수 적용
from tensorflow.keras.callbacks import ModelCheckpoint, ReduceLROnPlateau, EarlyStopping
model = create_model()
model.compile(optimizer=Adam(0.001), loss='categorical_crossentropy', metrics=['accuracy'])
mcp_cb = ModelCheckpoint(filepath='/kaggle/working/weights.{epoch:02d}-{val_loss:.2f}.hdf5', monitor='val_loss',
save_best_only=True, save_weights_only=True, mode='min', period=1, verbose=0)
rlr_cb = ReduceLROnPlateau(monitor='val_loss', factor=0.3, patience=5, mode='min', verbose=1)
ely_cb = EarlyStopping(monitor='val_loss', patience=7, mode='min', verbose=1)
history = model.fit(x=tr_images, y=tr_oh_labels, batch_size=128, epochs=40, validation_data=(val_images, val_oh_labels), callbacks=[mcp_cb, rlr_cb, ely_cb])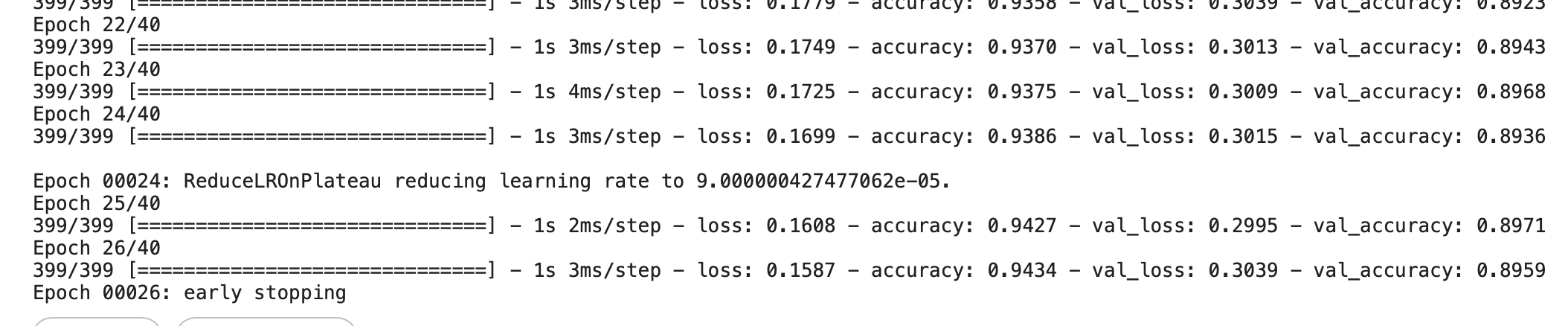 체크포인트는 매 epoch마다 저장을 하지만 진행화면에는 표시하지 않는다.
체크포인트는 매 epoch마다 저장을 하지만 진행화면에는 표시하지 않는다. verbose=0
learningRate는 5개 이전의 학습률을 기준으로 조정이 들어가고, EarlyStopping은 7개 이전의 학습률을 기준으로 학습을 조기종료 시킨다.
이렇게 여러가지 CallBack함수를 사용하여 모델을 최적화하는데 도움줄 수 있다.
- 체크 포인트 결과물 확인 -
$ !ls -lia
total 3376
1048578 drwxr-xr-x 3 root root 4096 Oct 9 16:41 .
141082764 drwxr-xr-x 5 root root 4096 Oct 9 15:20 ..
1048584 drwxr-xr-x 2 root root 4096 Oct 9 15:20 .virtual_documents
1048581 ---------- 1 root root 263 Oct 9 15:20 __notebook_source__.ipynb
1048585 -rw-r--r-- 1 root root 343096 Oct 9 16:41 weights.01-0.48.hdf5
1048586 -rw-r--r-- 1 root root 343096 Oct 9 16:41 weights.02-0.39.hdf5
1048587 -rw-r--r-- 1 root root 343096 Oct 9 16:41 weights.04-0.35.hdf5
1048588 -rw-r--r-- 1 root root 343096 Oct 9 16:41 weights.06-0.34.hdf5
1048589 -rw-r--r-- 1 root root 343096 Oct 9 16:41 weights.07-0.34.hdf5
1048590 -rw-r--r-- 1 root root 343096 Oct 9 16:41 weights.08-0.33.hdf5
1048591 -rw-r--r-- 1 root root 343096 Oct 9 16:41 weights.09-0.32.hdf5
1048592 -rw-r--r-- 1 root root 343096 Oct 9 16:41 weights.10-0.32.hdf5
1048593 -rw-r--r-- 1 root root 343096 Oct 9 16:41 weights.14-0.31.hdf5
1048594 -rw-r--r-- 1 root root 343096 Oct 9 16:41 weights.16-0.30.hdf5매 epoch마다 체크포인트가 저장되는 것을 볼 수 있다.
