Learning rate란?
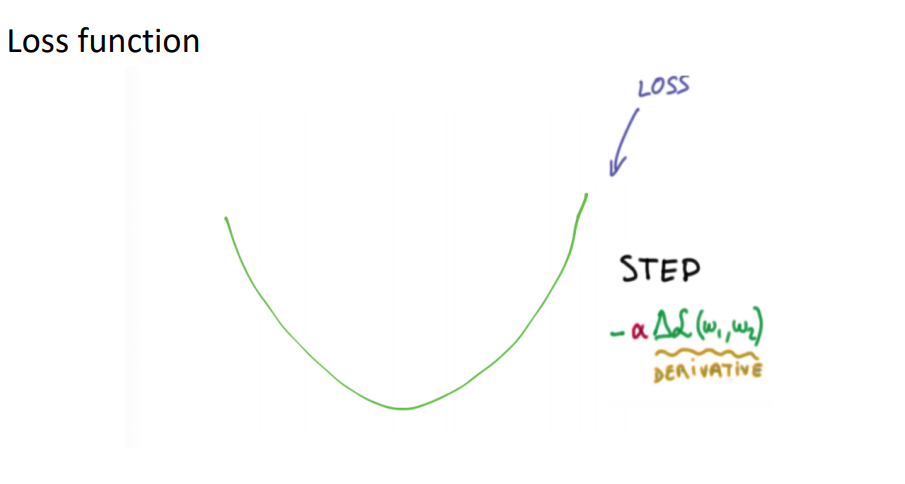
2차 곡선으로 표현돼있는 Loss function이 있었습니다. 이 때 주변 탐색을 위해 보폭을 결정을 해야하는데요. 이 때 보폭에 해당하는 것이 learning rate입니다.
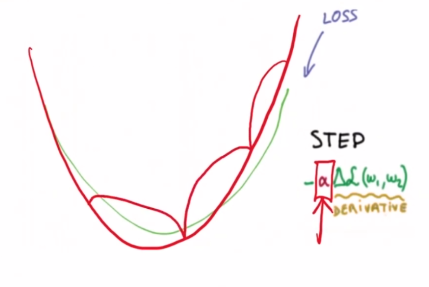
learning rate가 크다면 이렇게 W와 b의 최적값을 찾아 나가는데에 빠른 시간이 걸리지만 learning rate가 작다면,
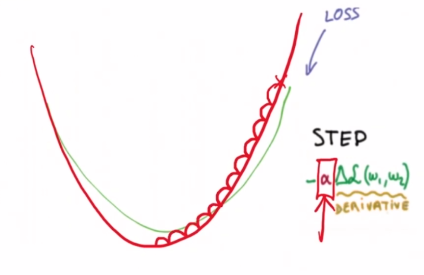
위와 같이 조금 씩 내려가면서 정밀하게 최적값을 찾아 내려갈 수 있습니다.
하지만 learning rate가 너무 크다면 어떻게 될까요?
> learning rate가 너무 클 때
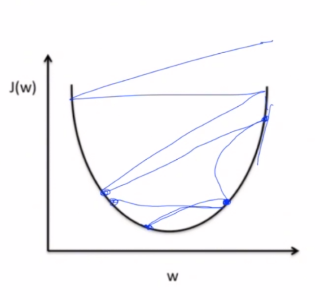
이와 같이 너무 보폭이 크기 때문에 발산하는 경우가 생길 수 있습니다.그래서 Cost 값이 Nan값이나 Inf라는 오류가 뜨는 경우가 있습니다. 이 현상을 Overshooting 이라고 합니다.
> learning rate가 너무 작을 때
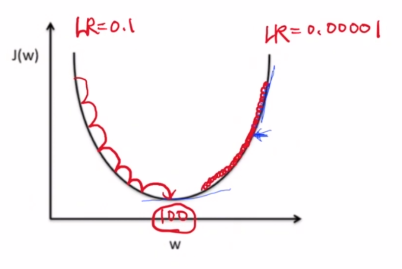
반대로 Learning rate가 너무 작다면 그만큼 정교한 과정을 거치는 것이며 시간이 오래 걸립니다.
이러한 이유 때문에 적절한 learning rate를 실험적으로 찾아나가야 합니다.
Data Preprocessing
Data Preprocessing이 왜 필요한지에 대해서 알아보도록 하겠습니다.
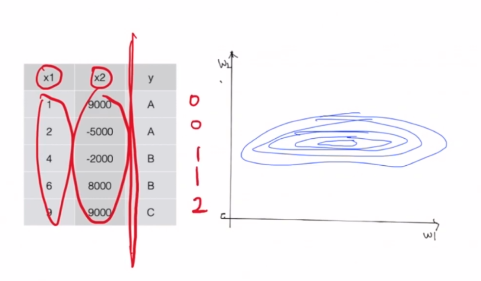
이 때 x1과 x2의 데이터가 스케일차이가 심하게 나는 경우가 있습니다.
그래서 상대적으로 w1은 움직이는 범위가 매우 크기때문에 찌그러진 비정방원으로 탐색영역이 만들어지게 됩니다.
이렇게 되면 단점이 존재합니다. 최적화문제를 풀기위한 경사하강법을 적용했을 때 아래와 같은 사진 처럼 한 쪽 방향으로 많이 점프를하며 진동하게 되어 좀 더 정밀하게 탐색을 할 수 없게 됩니다.
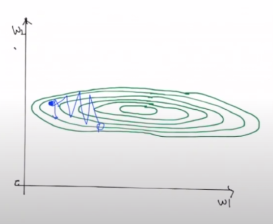
그래서 타원과 같은 탐색 영역들을 좀 더 정방원에 가깝도록 스케일 조정이 필요한 것입니다.
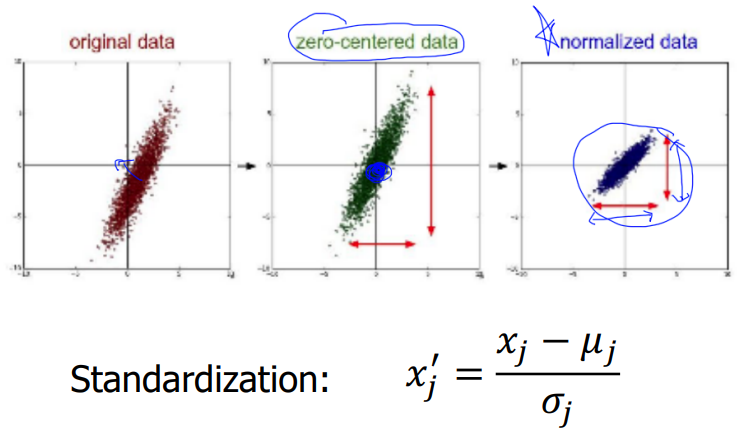
original data가 정 중간에 모여있지 않아서 zero-centered 과정을 거쳐 중간으로 고정을 시킨 후 normalized data과정을 거쳐서 최종적으로 평균값이 원점에 있고, 각 좌표계의 스케일이 동일한 데이터가 만들어지게 됩니다.
이렇듯 실제로 우리에게 주어지는 데이터들은 대부분 정규화가 안되어있는 데이터들이기 때문에 정규화 과정을 거쳐주어야만 학습이 효과적으로 진행 되는 것을 알 수 있습니다.
여기까지 데이터의 정규화 과정이 왜 필요한지 알아보았습니다.
Overfitting
모델 학습을 할 때 train데이터로 학습을 진행시켜주었고 정답을 알 수 없는 test데이터를 가지고서 얼마나 이 모델이 예측을 잘 하는지, 성능을 좋은지를 검사할 수 있었습니다.
Overfitting 이란 주어진 데이터, 즉 학습에 사용된 알고있는 데이터들에 한정해서만 예측을 잘 한다는 것입니다. 이말은 아예 처음 보던 데이터들은 예측률이 현저히 떨어지는 것을 의미 합니다.
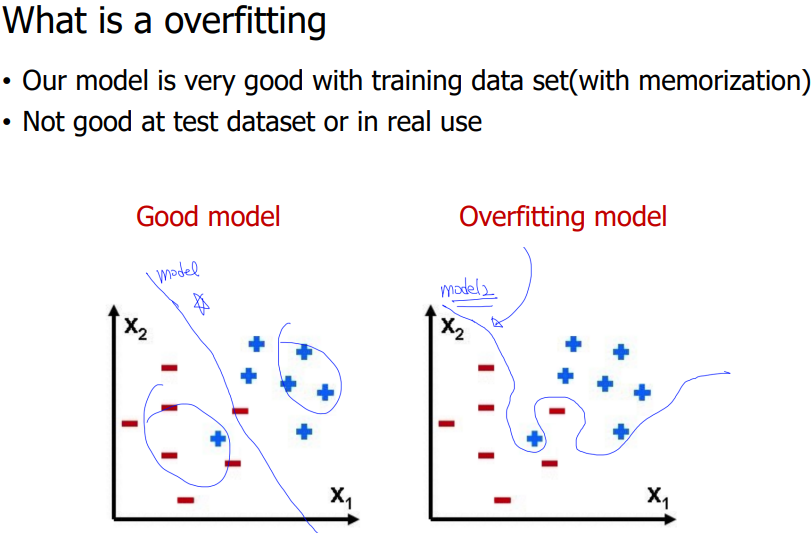
위 그림만 보면 왜 왼쪽 모델이 더 좋은 모델인지 이해하기 어렵습니다.
오른쪽의 모델은 이미 학습된 데이터로 예측을 하면 성능이 100%인데 왜 더 안 좋은 모델일까요?
그 이유는 왼쪽 모델은 이미 알고있는 데이터에 한정해서 80%의 정확도를 보이지만 처음 보는 데이터들의 예측을 좀 더 정확하게 할 수 있습니다.
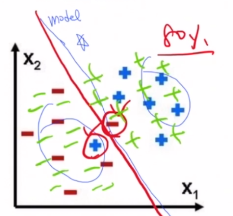
이 분포에서는 확률적으로 -는 왼쪽 +는 오른쪽에 올 확률이 많습니다. 그렇기 때문에 왼쪽이 처음 보는 데이터에 강하다는 것을 알 수 있고,
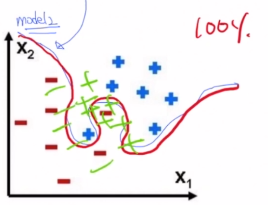
Overfittin 모델의 경우 정밀하고 과도하게 학습데이터를 학습하려했다보니 전체적인 경향성을 잃어버리고 처음 보는 데이터에 대해서는 오분류를 더 많이 보이게 됩니다.
이렇듯 학습데이터에만 성능이 좋고 테스트데이터에선 성능이 매우 좋지 않은 경우가 Overfittin이 되었다라는 것을 알 수 있습니다.
어떻게 Overfitting이 된건지 알 수 있을까요?
- More training data
- Reduce the number of features
- Regularization
첫 번째로 학습데이터가 많으면 많을 수록 성능이 좋습니다. 두 번째로 학습에 사용될 feature들중에 의미없고, 불 필요한 feature들을 제거하여 줄이는 방법이 있습니다.
세 번째로 중요한 것은 정규화 작업입니다.
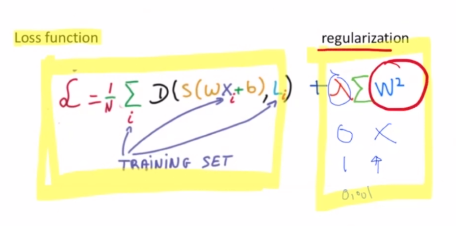
일반적으로 알고있는 Loss function에 뒤에 텀을 붙여 Regularization을 시켰다라고 할 수 있는데요.
방향성은 우리가 학습할 때 W가 너무 커지지 않게끔 하는 것이 목표입니다. W가 너무 크게 설계가 되면 Overfitting이 될 가능성이 높은데요. 그 이유는 실제로 W를 미세조정하여 Loss의 값을 낮추는데 의미가 있는 것이 아니라 애초에 W 자체가 값이 크다보니 우리가 학습시키는 방향이 W값을 줄이는 방향으로만 학습이 이루어지게 되는 것입니다. 이러한 단점을 보완하기 위해 W가 애초에 커지지 않도록 제어해주기 위한 식을 뒤에 붙이는 것입니다.
중요한 것은 W 자체가 커지지 않도록하는 정규화 텀을 넣음으로써 우리는 Overfitting을 피할 수 있다는 것입니다.
뒤의 람다는 어느정도의 정규화를 허용할 건지에 대한 파라미터입니다. 작게 반영하고 싶다면 0.001로, 크게 반영하고 싶다면 0.1로 이와같이 선택적으로 사용할 수 있습니다.
여기까지 과적합(Overfitting)을 막는 방법 세가지를 공부해봤습니다.
Performance evaluation
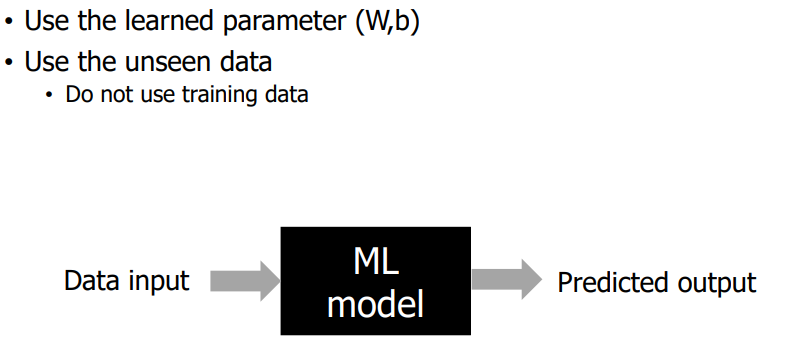
학습 데이터를 Input 하여 모델을 학습하게되고, 마지막에 결과값을 도출해냅니다.
평가의 핵심은 학습된 파라미터인 W와 b를 사용해야합니다. 모델은 학습과정에서 W,b를 구하는 과정을 말하며 평가하는 과정에서는 반드시 본적이 없는 데이터가 사용되어야 합니다. 그래야만 올바르게 테스트할 수 있게 됩니다.
중간중간 모델을 평가하기 위하여 training set을 만들 수 있습니다.
아래의 사진처럼 모든 데이터를 한번에 학습해서 똑같은 학습 데이터를 주었을 때 100% 정확도를 보여주는 똑똑한 모델이 만들어집니다. 하지만 이 모델은 이해하는 것이 아닌 학습데이터를 모두 외워버리는 것과 같습니다. 새로운 데이터에 대해선 취약합니다.

그렇기 때문에 학습하는 과정에서 아래사진 처럼 분류하여 잘 학습되는지 모델을 평가할 수 있습니다.
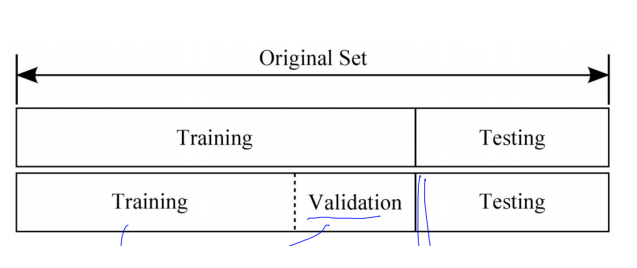
train data도 training data와 validation data로 재 분류하여 training data로 학습을 한 뒤
Validation data로 검증을 해보는 것입니다.
이처럼 validation set은 학습과정에서 잘 학습이 되는지 알아보기 위해서 쓰이는 것을 알 수 있었습니다.
