서론
사실 할 얘기 별로 없습니다. 이래서 제떄 제때 써야합니다. 죄송합니다. 여러모로 일이 많아서...
시작
Chapter 5. 시각화 라이브러리
데이터를 한 눈으로 보기 위해 시각화 라이브러리를 쓰자 matplotlib, seaborn 맞습니다
데이터 시각화의 목적은 통계적인 해석을 넘어 비즈니스의 인사이트를 파악하기 위해 합니다.
하지만 그래프와 통계량은 요약된 정보가 표현되고, 요약하는 관점에 따라 해석의 결과가 달라지므로 요약하면 정보 손실되는 것도 고려해야합니다.
-
라이브러리 import하기
import matplotlib.pyplot as plt import seaborn as sns
-
그래프 그리기
plt.plot()기본 라인 그래프
x와 y값을 지정해줘야 그래프 의미가 있겠죠?plt.show(): 그래프 출력
plt.plot('x', 'y', data=)
x, y에 각각 열 이름을 문자열을 넣어서 쓰면 된다.
list, numpy array, series 등 1차원도 가능하며, 2차원으로 dictonary, dataframe의 열을 지정하여 사용할 수있다.
plt.xticks(rotation = 각도)각도값을 부여해 x축 값 기울기를 조정 할 수 있다.plt.xlabel('title')x축에 라벨을 붙인다plt.ylabel()도 가능하다.plt.title("제목")그래프 타이틀을 붙일 수 있다.plt.plot()에 여러가지 매개변수를 추가할 수 있다.color라인에 색을 부여한다. ‘r’, ‘g’, ‘b’ 혹은 ‘red’, ‘blue’ 등등… 여기서 부턴 파라미터로 지정해줘야한다.linestyle라인을 변경한다. solid, dashed, dashdot, dotted등marker포인트 마다 마커 변경한다.
여러 그래프를 한 이미지에 나타낼 수 있다.plt.plot(df['Date'], df['Ozone'], marker = 'o') plt.plot(df['Date'], df['Temp'], marker = 's') plt.show()
plt.legend()그래프가 무엇을 의미하는지 표시하기
위치 조절 가능plt.legend(loc=): best, upper right, lower left...plt.plot(label ='Price') # 라벨 지정 plt.legend() plt.show()
plt.grid()그래프에 격자 추가pd.DataFrame.plot(x=, y=, title=): 데이터 프레임에서 바로 그래프를 그려볼 수 있다. 시리즈가 아닌 여러 데이터를 list로 한번에 넘겨줄 수 있다.
plt.xlim(시작, 끝): x 축의 범위를 조정한다 마찬가지로plt.ylim()도 사용 가능하다.
plt.figure(figsize = (’tuple’)): 그래프 사이즈를 조정한다. (Default = 6.4 : 4.4)
plt.axhiline(위치, color=, linestyle=): 수직선을 추가한다.plt.axvline(위치, color=, linestyle=): 수평선을 추가한다.plt.text(x좌표, y좌표, ‘텍스트 값’): 그래프에 텍스트를 추가한다.
Chapter 6. 단변량 분석 - 연속형
데이터가 분포하는 건 다 그러한 이유가 있답니다.
숫자형 변수가 주어졌을 때, 어떻게 분석하셔서 인사이트 도출하실래요?
첫번째로 통계량이 있겠고, 두번째론 시각화가 있습니다.
통계량은 그 집단의 평균, 중위값같이 그 집단을 대표하는 값을 말합니다.
-
숫자로 요약하기 : 정보의 대표값
평균 : 산술평균, 기하평균, 조화평균
np.mean()df['열'].mean()- 산술평균 : 모든 값을 더해서 갯수로 나눈 값. (우리가 아는 그 평균)
- 기하평균 : n개의 양수 값을 모두 곱한 뒤 n제곱근 한 값
- 조화평균 : 산술평균의 역수 (다른 차원에서 값을 구하고 기존 차원으로 돌릴 때 많이 사용함)
중위수 : 자료 순서상 가운데 위치한 값
np.median()df['열'].median()최빈값 : 자료중 가장 많은(빈번한) 값
df['열'].mode()사분위수 : 데이터를 오름차순으로 정렬 후, 전체를 4등분 후, 각 경계에 해당되는 값
(25%, 50%, 75%) {Q1, Q2, Q3}
→ 구간을 나누고 빈도수 계산 = 도수분포표 (Histogram, DensityPlot(KDE))위 정보를
df.describe()로 한번에 볼 수 있다.
-
연속형 변수 시각화하기
히스토그램 : 표로 되어있는 도수 분포를 정보 그림으로 나타냄
plt.hist(df.열이름, bins=구간 수)
확률밀도함수 : 구간의 너비에 따라 히스토그램 모양이 달라지지만 이를 보안하는 밀도함수 그래프가 있다.
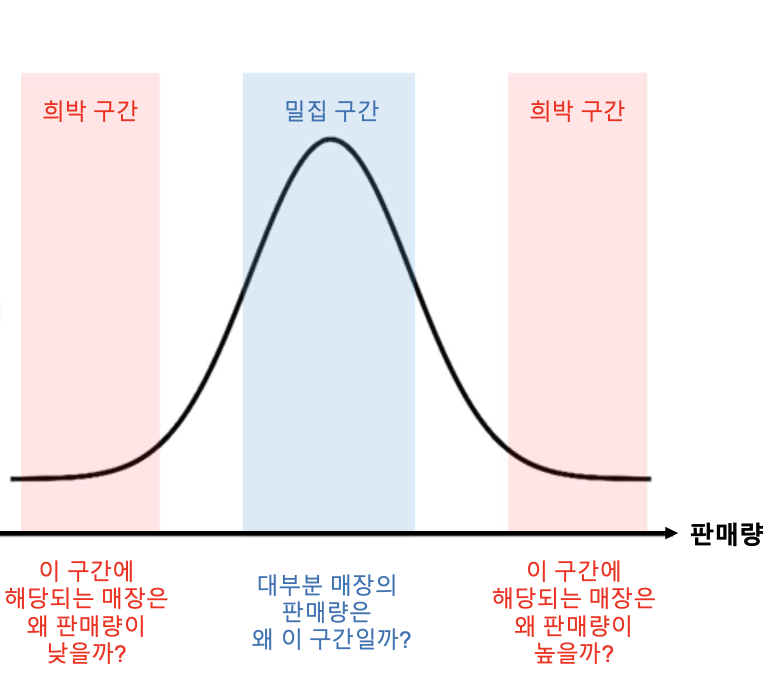
sns.kdeplot(df)
값의 분포를 보고 희박한 구간, 밀집된 구간에서 이유를 찾아 비즈니스의 의미 파악에 초점을 두자- 구간의 너비를 정하지 않아도 됨
- 데이터의 밀도 추정
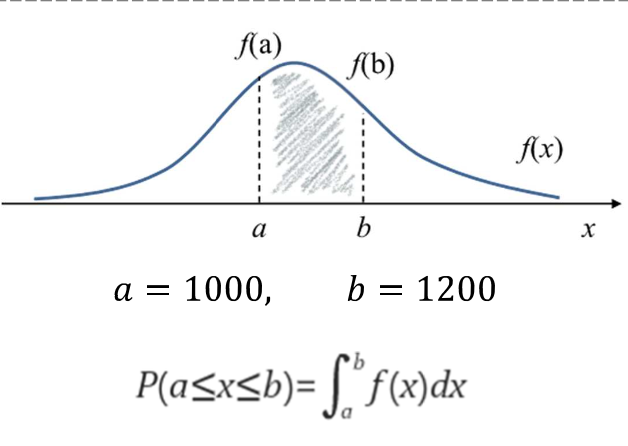
- 이 그래프의 본 목적은 확률 추정이다. 면적으로 구간에 대한 확률을 추정하지만, 우리는 분포를 보기 위해 사용
- 밀도 추정 : 측정된 데이터로부터 전체 데이터 분포의 특성을 추정한다.
ex) 어느 사거리의 3개월 일일 교통량 → 1000~ 1200대일 확률은 적분하면 확률이 나온다. 확률로 보면 됨
box plot : 사분위값을 이용하여 데이터의 분포 모양, 대칭성, 극단 값을 쉽게 파악할 수 있는 그래프
plt.boxplot(df['열'], vert=False)
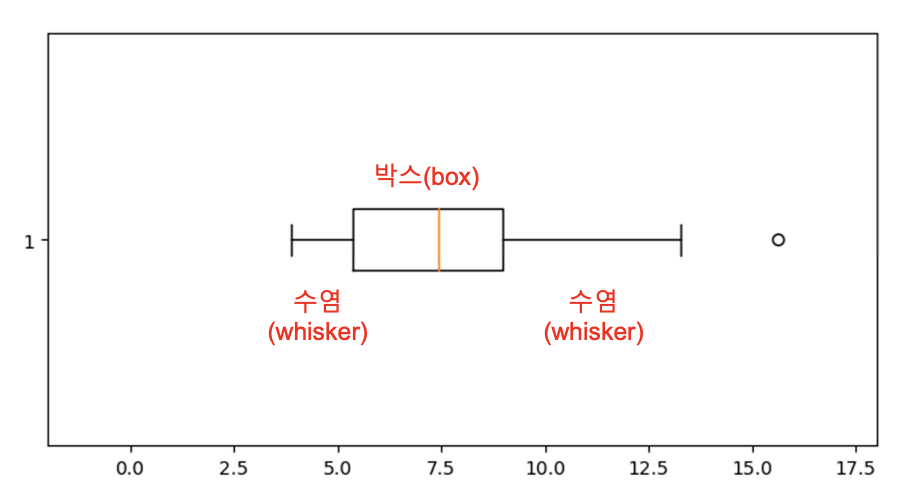
vert는 bool 값 횡(False), 종(True) 종이 디폴트값이다.
박스의 가장 왼쪽 선이 Q1(25%), 박스 내 선이 Q2(50%), 박스의 가장 오른쪽 선이 Q3(75%)이다.
Chapter 7. 단변량 분석 - 범주형
범주형은 남자/여자, 선호/잘모름/비선호 처럼 나뉘는 값을 말한다.
범주형은 어떻게 분석할까?
범주별 갯수를 센다. (범주별 빈도수, 범주별 비율)
Series.values_count(): 범주의 갯수를 센다Series.values_count(nomalize=True): 정규화하여 비율을 나타낸다.
범주형 시각화
Barplot이 보기 좋다. 히스토그램과 유사하지만 히스토그램은 x축이 데이터 갯수이므로 bar과는 다르다
sns.countplot(data) : 범주별 빈도수를 계산하여 barPlot으로 그린다.
plt.bar()와 비슷하지만, 직접 빈도수를 계산해야되서 sns 라이브러리가 더 편하다.
마무리
학부때 다 먹던 맛들... 현업에서도 비슷하게 쓰는구나 싶다.
