
읽는 데에 드는 시간 : 4분
TL; DR
이 글은 AI에서 모델 서빙 속도를 개선하는 NVIDIA Triton Inference Server에 대해 설명합니다. AI 모델 배포의 도전과제, Triton의 다양한 기능, 성능 평가, 장단점을 다룹니다.
서론
제가 재직하고 있는 디플리에서는 소리 인공지능 기술을 개발하고 이를 활용한 실시간 위험 탐지 솔루션을 제공하고 있습니다. 실시간에 가까운 낮은 지연시간으로 AI 서비스를 제공하는 것은 더 나은 사용자 경험을 넘어 높은 치안 수준과 안전한 사회로 나아가기 위한 필수적인 도전 과제입니다.
이 글은 AI 모델 추론에 대한 어려움을 먼저 소개하고, NVIDIA가 개발한 Triton Inference Server를 솔루션으로 제안합니다.
추론 서버 구성의 어려움
AI는 크게 학습(Training)과 추론(Inference)의 두 부분으로 구성됩니다. 추론은 프로덕션 단계에 해당하며 모델과 pre-processing & post-processing 코드와 함께 데이터 센터나 클라우드 혹은 엣지에 배포됩니다.
AI는 추천, 예측, 품질검사, 분류 등 다양한 산업에서 빠르게 발전하고 있습니다. 기업들은 각 모델과 프레임워크, 애플리케이션별 추론을 위한 솔루션을 고민합니다. AI 모델 배포를 위해 추론 서버를 구성할 때 다양한 문제가 발생할 수 있습니다.
- 모델 호환성 및 통합 : Tensorflow, PyTorch, ONNX 등.
- 하드웨어 리소스 관리 : CPU 및 GPU 리소스 최적화.
- 확장성 및 로드 밸런싱 : 요구사항에 맞게 서버를 확장하고 효율적인 로드 분산.
- 전처리 및 후처리 로직 : 입력 데이터 및 추론 결과에 대한 전처리 및 후처리 단계를 각각 구현하고 최적화.
- 모니터링 및 유지 관리 : 로깅 구성, 성능 지표 추적, 모델 업데이트, 보안 조치 등.
NVIDIA Triton Inference Server
NVIDIA Triton Inference Server는 프로덕션 환경에서 AI 모델 간소화하고 최적화하도록 설계된 소프트웨어 도구입니다. 주요 기능은 다음과 같습니다.
- 다중 프레임워크 호환성: TensorFlow, PyTorch, ONNX 등과 같은 다양한 AI 프레임워크를 지원하므로 상당한 수정 없이 다양한 환경에서 개발된 모델을 배포.
- 최적화된 리소스 활용: Triton은 GPU 및 CPU 리소스를 효율적으로 사용하여 높은 처리량과 낮은 지연 시간의 추론을 제공하므로 성능이 중요한 애플리케이션에 적합.
- 확장성 및 유연성: 다수의 추론 요청을 동시에 처리하고 수요에 따라 확장할 수 있으며 클라우드, 데이터 센터, 엣지 장치를 포함한 다양한 환경에 배포할 수 있을 만큼 유연.
- 동적 일괄 처리: 서버는 들어오는 요청을 자동으로 일괄 처리하여 처리량을 향상. 특히 일괄 처리 성능이 좋은 모델에 유용.
- 모델 버전 제어 및 손쉬운 업데이트: Triton을 사용하면 다양한 모델 버전을 쉽게 업데이트하고 관리할 수 있어 원활한 전환과 지속적인 개선 통합이 가능.
Triton이 모델 추론 성능을 향상시키는 전략들
- 동적 일괄 처리(Dynamic Batching) : 여러 요청을 단일 배치로 결합하여 효율적으로 처리. 일괄 처리에 최적화된 모델의 경우 처리량을 크게 향상시킴.
- 모델 파이프라이닝 : 모델 추론 프로세스의 여러 단계가 서로 다른 GPU 또는 기타 하드웨어에서 병렬로 실행.
- 다중 모델 실행 : 여러 모델을 동시에 제공. 다양한 모델에 걸쳐 GPU 및 CPU 리소스를 효율적으로 할당하여 유휴시간(idle time) 감소.
- GPU 메모리 관리 : 필요할 때만 모델을 메모리에 로드하고 각 메모리 공간을 효율적으로 관리.
성능 평가
실제로 얼마나 성능이 개선 되었는지 측정하기 위해 같은 조건에서 부하를 걸어보았습니다. GPU를 사용할 수 있는 환경이 없어서 오직 CPU만 사용해서 진행했습니다.
측정 결과를 모두 글에 담지는 못했지만, 다양한 컴퓨터에서도 실행해보았습니다.
- AWS EC2 p3.2xlarge
- AWS EC2 t2.micro (실행 불가)
- AWS EC2 t2.medium
- AWS EC2 t2.large
- Jetson Orin Modules and Developer Kits
- NVIDIA Jetson Nano
- Orange Pi 5
- Raspberry Pi 4
- Apple MacBook Pro (M1, 2020)
실험 조건
- Concurrency: 10
- CPU : Apple M1
- RAM : 16GB RAM
- OS : macOS 14.0
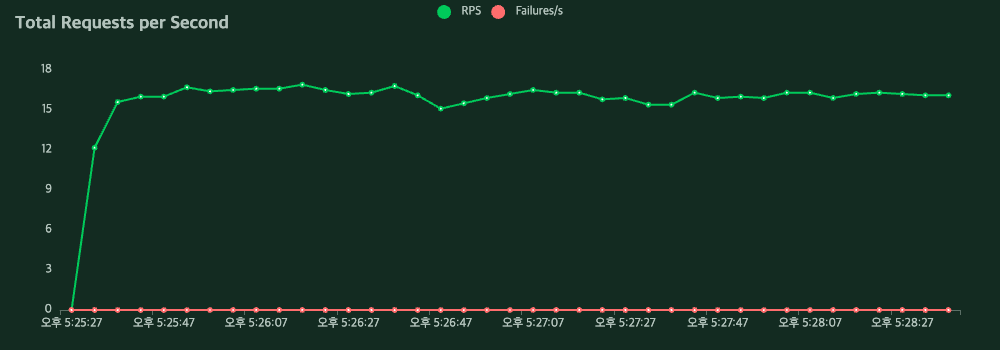
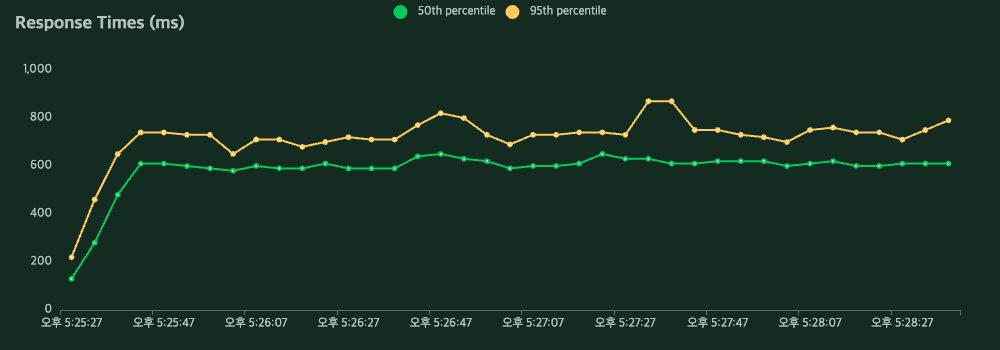
PyTorch
| Method | Name | # Requests | # Fails | Average (ms) | Min (ms) | Max (ms) | Average size (bytes) | RPS | Failures/s |
|---|---|---|---|---|---|---|---|---|---|
| POST | /torch | 3154 | 0 | 766 | 141 | 2906 | 310 | 12.8 | 0.0 |
| Aggregated | 3154 | 0 | 766 | 141 | 2906 | 310 | 12.8 | 0.0 |
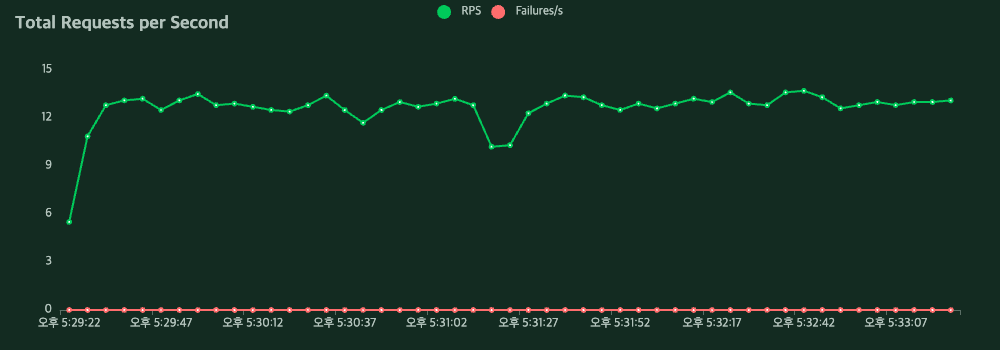
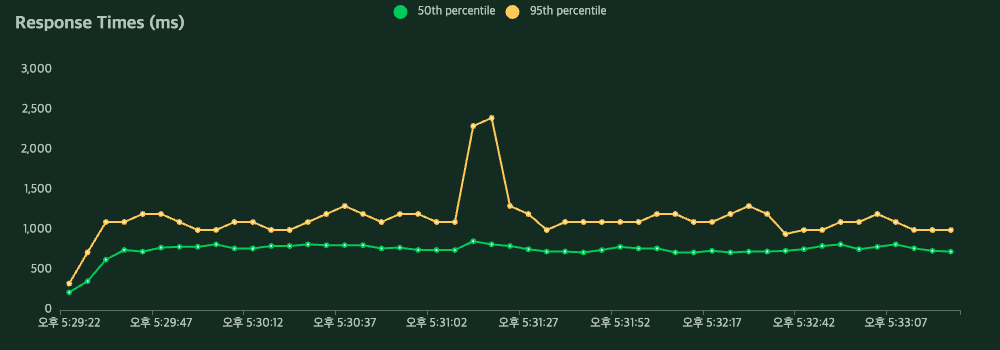
Triton Inference Server
| Method | Name | # Requests | # Fails | Average (ms) | Min (ms) | Max (ms) | Average size (bytes) | RPS | Failures/s |
|---|---|---|---|---|---|---|---|---|---|
| POST | /triton | 3144 | 0 | 607 | 55 | 1009 | 308 | 16.0 | 0.0 |
| Aggregated | 3144 | 0 | 607 | 55 | 1009 | 308 | 16.0 | 0.0 |
결과
RPS가 12.8 → 16.0 으로 25% 향상.
마치며
장점
- 빠르게 AI 모델 추론 서버를 구성할 수 있다.
- 인터페이스로 HTTP, gRPC를 제공한다.
- gRPC를 통해 효율적인 스트림 데이터를 처리할 수 있다.
- 각 모델의 성능 측정하고 최적의 설정값을 찾는 툴을 함께 제공한다.
- Performance Analyzer, Model Analyzer
단점
- GPU에 모델을 로드하는 경우, 서버 실행 초기에 최적화 시간이 필요한 것 같다.
- 엣지 디바이스 같은 너무 낮은 사양의 컴퓨터에서의 운영은 부담스럽다.
- 직관적인 모델 리포지토리를 제공하지만, 커스텀하여 운영할 수 없다. 예를 들면 레이블을 정의한 텍스트 파일의 내용조차 API를 통해 조회할 수 없다.
