SQL의 핵심(?)인 서브쿼리에 대해 공부해보자.
부모쿼리 ( 서브쿼리 ) ;{kind=link}
서브쿼리란..?
다른 SQL구문(포함구문=부모쿼리,containing statement)에 포함된 쿼리다. 항상 괄호( )로 묶여있고, 일반적으로는 포함구문보다 먼저 실행된다. 서브쿼리는 아래와 같은 결과셋을 보여줄 수 있다.
- 단일 열 / 단일 행
- 단일 열 / 다중 행
- 다중 열 / 다중 행
서브쿼리는 구문범위가 있는 임시테이블처럼 동작하므로, 포함구문 실행이 완료되면 서브쿼리가 반환한 데이터는 폐기된다. (SQL 구문 실행이 끝나면 서버가 서브쿼리 결과에 할당된 메모리를 해제한다)
여러번 쿼리문을 실행하는 것을 1번의 쿼리만으로 해결해주는 것이 서브쿼리라고 이해했다.
두 종류가 있다.
- 비상관 서브쿼리(noncorrelated subqueries) : 완전히 독립적으로 실행됨
- 상관 서브쿼리(correlated subqueries) : 포함구문의 열을 참조함
비상관 서브쿼리
단독으로 실행될 수 있으며, 포함구문에서 아무것도 참조하지 않는 유형의 서브쿼리다.
a.k.a 스칼라 서브쿼리(scalar subquery)
단일 열 / 다중 행
서브쿼리가 2개 이상의 행을 반환할 경우, 동등조건(<>, =, =!와 같이 1:1연산을 하는 것들)을 사용할 수 없다.
오류가 나는 예시를 보자.
SELECT
city_id
, city
FROM city
WHERE country_id <> (SELECT country_id
FROM country
WHERE country <> 'India');이 쿼리가 오류가 나는 이유는 당연하다. 서브쿼리에서 인도가 아닌 국가들을 찾았는데, 또 그것이 아닌 국가들을 찾으라고 WHERE절에 넣었기 때문이다. (country 테이블에서 인도가 아닌 국가들은 한두개가 아니다...)
이런 유형의 서브쿼리와 함께 조건을 작성할 수 있는 4개의 연산자를 알아보자.
in 연산자, not in 연산자
in 연산자는 집합 내에서 하나의 값을 검색할 수 있다.
in 연산자를 사용해 서브쿼리를 작성하는 예시를 살펴보자.
SELECT
city_id
, city
FROM city
WHERE country_id IN (SELECT country_id
FROM country
WHERE country IN ('Canada', 'Mexico'));→ 캐나다 또는 멕시코에 있는 37개의 도시와 도시ID를 보여준다.
not in 연산자는 집합 내에 값이 없는지를 확인할 수 있다.
위의 쿼리에서 in 대신 not in을 사용해보자.
SELECT
city_id
, city
FROM city
WHERE country_id NOT IN (SELECT country_id
FROM country
WHERE country IN ('Canada', 'Mexico'));→ 캐나다 또는 멕시코에 없는 모든 도시가 결과값에 나타난다. (563개)
all 연산자
all 연산자는 한 집합의 모든 값과 하나의 값을 비교할 수 있다. 조건을 작성하려면 all 연산자와 함께 비교연산자(=, <>, <, > 등) 중 하나를 사용해야 한다.
SELECT
first_name
, last_name
FROM customer
WHERE customer_id <> ALL (SELECT customer_id
FROM payment
WHERE amount = 0);→ 무료 영화(payment 테이블에서 지불금액이 0인)를 대여한 적이 없는 모든 고객을 찾을 수 있다.
동일한 결과값을 not in 연산자를 사용한 쿼리로 표현할 수도 있다.
SELECT
first_name
, last_name
FROM customer
WHERE customer_id NOT IN (SELECT customer_id
FROM payment
WHERE amount = 0);
not in또는all을 사용할 경우,null값을 포함하지 않도록 주의하자.
아래와 같은 경우 빈 결과값이 반환된다.SELECT first_name , last_name FROM customer WHERE customer_id NOT IN (122, 452, NULL); ------------- Empty set (0.00 sec)
any 연산자
all 연산자와 마찬가지로 한 집합의 모든 값과 하나의 값을 비교하지만, any 연산자를 사용할 경우에 여러 비교값 중 하나라도 만족하면 true로 반환된다.
예제 : 볼리비아, 파라과이, 칠레에 거주하는 고객이 지불한 총 영화 대여료를 초과하는 결제금액을 가진 모든 고객을 찾고 싶다고 하자.
그렇다면,
- 서브쿼리에서는 (볼리비아에 거주하는 고객의 총 영화 대여료, 파라과이에 거주하는 고객의 총 영화 대여료, 칠레에 거주하는 고객의 총 영화대여료)를 계산해야 하고,
- 볼리비아에 거주하는 고객의 총 영화 대여료 = 183.53
- 파라과이에 거주하는 고객의 총 영화 대여료 = 275.38
- 칠레에 거주하는 고객의 총 영화 대여료 = 328.29
- 포함구문에서는 서브쿼리의 결과 3개 중 1개보다도 많은 결제금액을 가진 고객들만 나열해야 한다. (비교연산자 사용)
any를 사용했으므로 여러 비교값 중 하나라도 만족하면 된다.- 즉, 183,53보다 많은 결제금액을 가진 고객들이 나열될 것이다.
SELECT
customer_id
, SUM(amount)
FROM payment
GROUP BY customer_id
HAVING SUM(amount) > ANY (SELECT SUM(p.amount)
FROM payment p
INNER JOIN customer c
ON p.customer_id = c.customer_id
INNER JOIN address a
ON c.address_id = a.address_id
INNER JOIN city ct
ON a.city_id = ct.city_id
INNER JOIN country co
ON ct.country_id = co.country_id
WHERE co.country IN ('Bolivia', 'Paraguay', 'Chile')
GROUP BY co.country);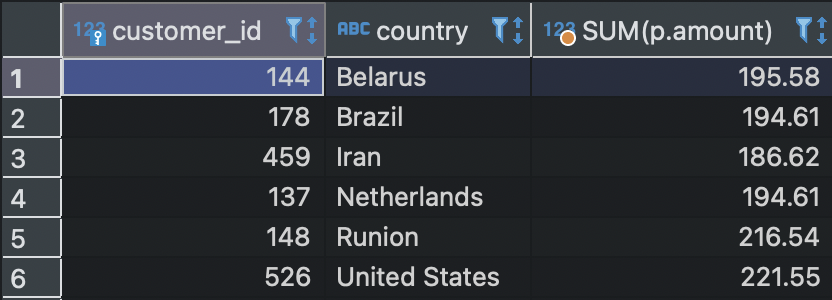
결과값에 그림처럼 country까지 포함되게 하려면, 포함구문의 SELECT절에 INNER JOIN을 통해 테이블들을 조인해줘야한다.
다중 열 / 다중 행
예제 : 성이 Monroe인 배우가 PG 등급의 영화에 출연한 모든 결과를 보고 싶다고 하자.
이를 위해서는,
- film_actor 테이블에서 성이 Monroe인 배우ID(열1)와, 그 배우가 출연한 영화ID(열2)를 알아야 하고,
- film 테이블에서 등급이 PG인 영화를 검색해야 한다.
이렇게 2개의 서브쿼리를 써야하는 것을
SELECT
fa.actor_id
, fa.film_id
FROM film_actor fa
WHERE fa.actor_id IN (SELECT actor_id
FROM actor
WHERE last_name = 'Monroe')
AND fa.film_id IN (SELECT film_id
FROM film
WHERE rating = 'PG'); CROSS JOIN을 이용해 1개의 서브쿼리로 바꿀 수 있다.
SELECT
fa.actor_id
, fa.film_id
FROM film_actor fa
WHERE (a.actor_id, f.film_id) IN (SELECT a.actor_id, f.film_id
FROM actor a
CROSS JOIN film f
WHERE a.last_name = 'Monroe'
AND f.rating = 'PG'); 상관 서브쿼리
상관 서브쿼리는 비상관 서브쿼리와 달리, 하나 이상의 열을 참조하는 포함구문에 의존적이다. 포함구문을 실행하기 전에 실행되지 않는다. (포함구문을 실행하고 나서, 그 중 어떤 값을 참조하여 서브쿼리가 돌아가는 식)
예제 : 정확히 20편의 영화를 대여한 고객을 검색한다고 해보자.
이를 위해서는,
- 각 고객의 영화 대여횟수를 계산하고,
- 그 중 대여횟수가 20회인 고객을 찾아야 한다. → 상관 서브쿼리
SELECT
c.first_name
, c.last_name
FROM customer c
WHERE 20 = (SELECT COUNT(*)
FROM rental r
WHERE r.customer_id = c.customer_id); /* 서브쿼리를 상호 연관시킴 */예제 : 영화 대여에 지불한 총 금액이 180~240달러 사이인 모든 고객을 찾아보자. 이를 위해서는,
- 각 고객의 총 지불금액을 계산하고,
- 그 중 총 지불금액이 180~240달러 사이인 고객을 찾아야 한다. → 상관 서브쿼리
SELECT
c.first_name
, c.last_name
FROM customer c
WHERE (SELECT SUM(p.amount)
FROM payment p
WHERE p.customer_id = c.customer_id)
BETWEEN 180 AND 240 ;
-------------------------
6 rows in set
first_name|last_name|
----------+---------+
RHONDA |KENNEDY |
CLARA |SHAW |
ELEANOR |HUNT |
MARION |SNYDER |
TOMMY |COLLAZO |
KARL |SEAL |삽질기록 😓 join과 상관서브쿼리를 함께 썼을 때
삽질의 발단 : 고객의 성, 이름과 함께 지불금액 총합도 보고싶었을 뿐이다...
위의 쿼리에서 포함구문의 SELECT 절에 SUM(p.amount)를 추가하고 payment 테이블과 customer 테이블을 조인했다.
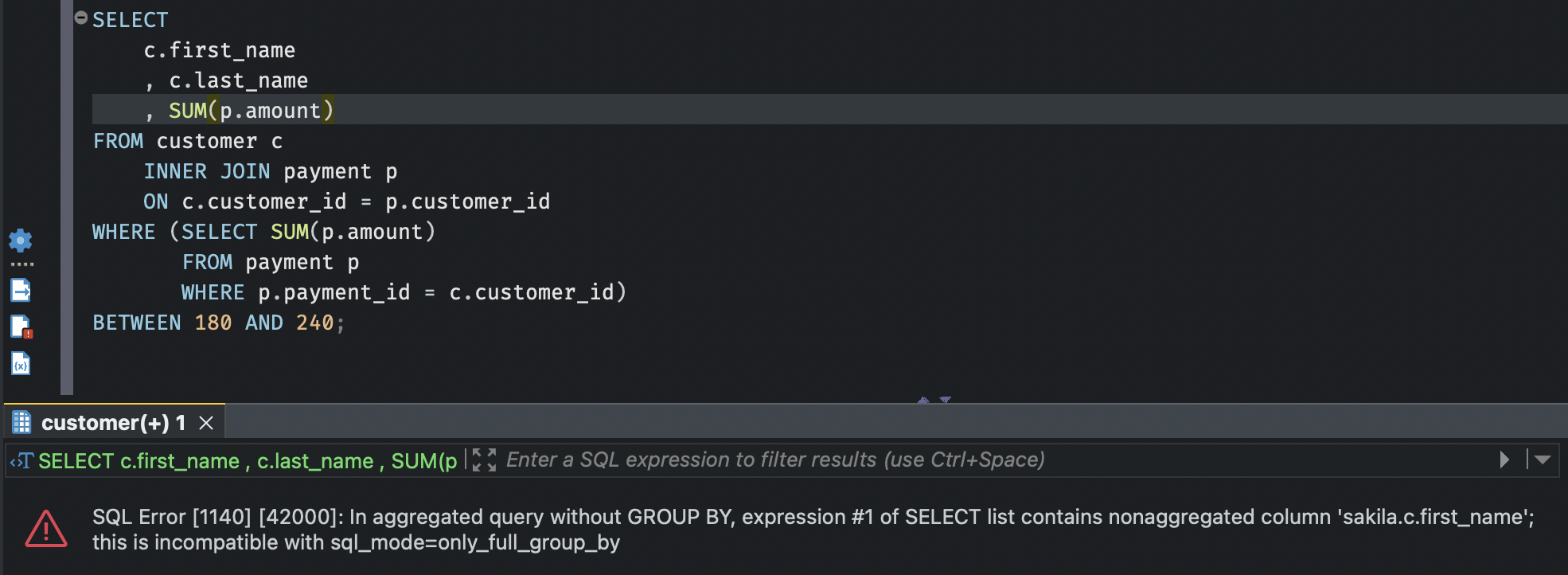
응..? GROUP BY가 없다구..?
ㅇㅋ 그럼 customer_id를 기준으로 그룹화해주지..! 하고 쿼리 추가 😓
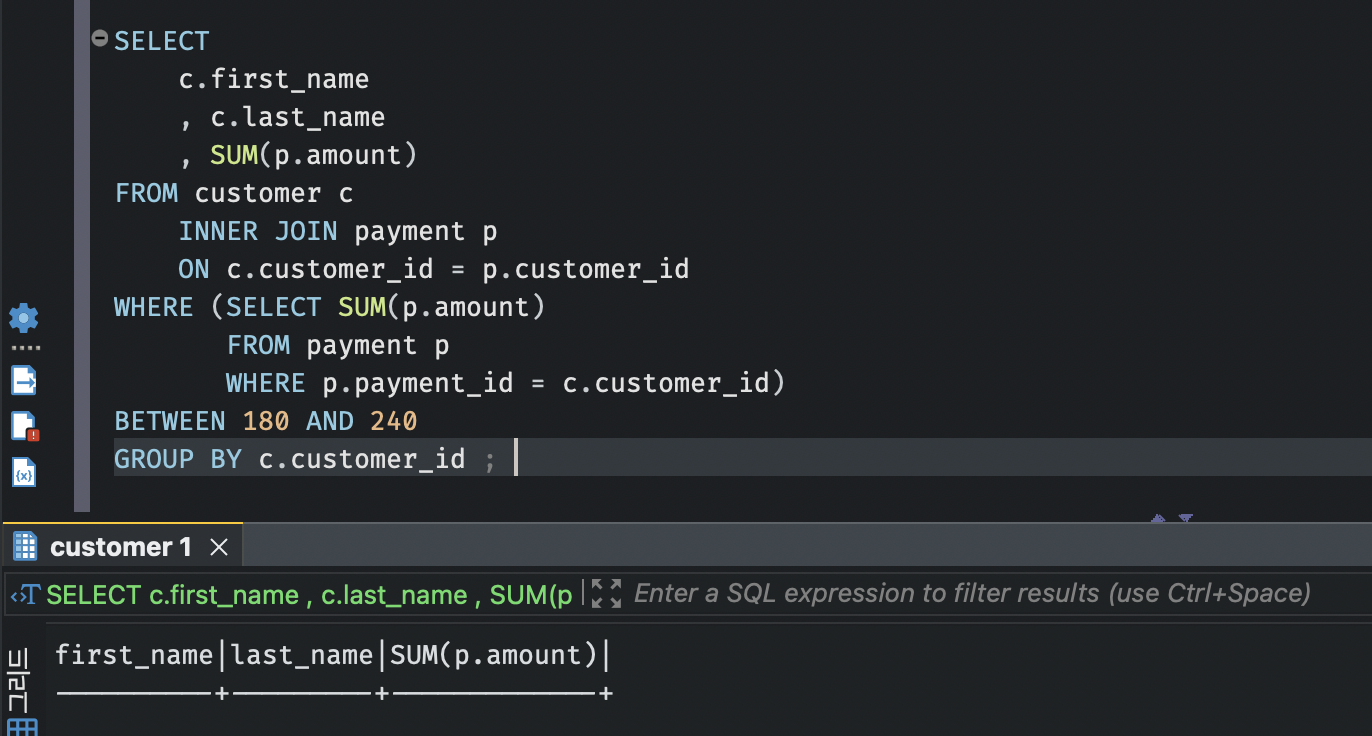
empty set 반환.
아니 뭐가 문제지....?????????????
이렇게도 써보고 저렇게도 써보고, 별의별 해괴망측한 쿼리를 다 실행시켜보다가 발견한 점..!
- 보통 내가 아는 서브쿼리는 서브쿼리만 실행했을 때도 결과가 나온다. → 비상관 서브쿼리였던 것..!
- 그런데 상관 서브쿼리 예제에서는 서브쿼리만 실행했을 때 에러가 뜬다..! (예를 들면 테이블을 참조할수 없다던가..) → 포함구문 먼저 실행하기 때문
아 그러면, 조인에 뭔가 문제가 있겠구나 싶어서 서브쿼리를 싹 배제하고 내가 아는 JOIN과 GROUP BY, HAVING 만을 이용하여 고객의 성, 이름과 함께 지불금액 총합을 불러와봤다.
SELECT
c.first_name
, c.last_name
, SUM(p.amount)
FROM customer c
INNER JOIN payment p
ON c.customer_id = p.customer_id
GROUP BY c.customer_id
HAVING SUM(p.amount) BETWEEN 180 AND 240 ;
-------------------------
6 rows in set
first_name|last_name|SUM(p.amount)|
----------+---------+-------------+
RHONDA |KENNEDY | 194.61|
CLARA |SHAW | 195.58|
ELEANOR |HUNT | 216.54|
MARION |SNYDER | 194.61|
TOMMY |COLLAZO | 186.62|
KARL |SEAL | 221.55|
잘 ㄴ ㅏ와요..
결론 : 상관 서브쿼리의 경우 JOIN 과 함께 쓸 수 없구나.
상관 서브쿼리를 쓰거나 OR JOIN을 쓰거나.
exists 연산자
exists연산자를 사용할 때는select 1또는select *로 정의하는게 규칙이다.
예제 : 영화 대여 횟수와 상관없이 2005년 5월 25일 이전에 1개 이상의 영화를 대여한 모든 고객을 찾아보자.
SELECT
c.first_name
, c.last_name
FROM customer c
WHERE EXISTS (SELECT 1
FROM rental r
WHERE r.customer_id = c.customer_id
AND date(r.rental_date) < '2005-05-25') ;
----------+-----------+
first_name|last_name |
----------+-----------+
CHARLOTTE |HUNTER |
DELORES |HANSEN |
MINNIE |ROMERO |
CASSANDRA |WALTERS |
ANDREW |PURDY |
MANUEL |MURRELL |
TOMMY |COLLAZO |
NELSON |CHRISTENSON|
----------+-----------+
8 rows in set반대로 아무 행도 반환하지 않는 서브쿼리를 확인하기 위해서는 not exists를 사용할 수 있다.
예제 : R 등급 영화에 출연한 적이 한번도 없는 모든 배우를 찾아보자.
SELECT
a.first_name
, a.last_name
FROM actor a
WHERE NOT EXISTS (SELECT 1
FROM film_actor fa
INNER JOIN film f
ON fa.film_id = f.film_id
WHERE fa.actor_id = a.actor_id
AND f.rating = 'R') ;
----------+---------+
first_name|last_name|
----------+---------+
JANE |JACKMAN |
----------+---------+상관 서브쿼리를 이용한 데이터 조작
서브쿼리는 SELECT 뿐만 아니라 UPDATE, DELETE, INSERT 문에서도 많이 사용되고, 상관 서브쿼리는 UPDATE, DELETE 문에서 자주 쓰인다.
예제 : rental 테이블에서 각 고객의 최신 대여 날짜를 찾아서 customer 테이블의 모든 last_update 행을 수정하고 싶다.
여기서 주의할 점 :
- 모든 고객이 영화를 1번 이상 대여하지 않았을 수도 있다.
- 즉
null값이 존재할 수도 있다.
- 즉
last_update열을 업데이트하기 전에null값이 존재하는지 확인해야 한다.- 만약
null값이 존재한다면 열이null로 덮어씌워질 것이다.
- 만약
- 또는
last_update열의 데이터가null로 덮어씌워지지 않도록 보호하는 쿼리를 짜야 한다.
UPDATE customer c
SET c.last_update = (SELECT MAX(r.rental_date)
FROM rental r
WHERE r.customer_id = c.customer_id)
WHERE EXISTS (SELECT 1 /* 고객의 대여기록이 1개 이상 있을 때만 */
FROM rental r
WHERE r.customer_id = c.customer_id) ;→ WHERE 조건문이 true 일 때만 SET절의 서브쿼리가 실행되므로 last_update 열의 데이터가 null로 덮어씌워지지 않도록 보호할 수 있다.
예제 : customer 테이블에서 지난 1년 동안 영화를 대여하지 않은 고객의 행을 제거하고 싶다. (휴면고객)
MySQL에서는
DELETE문을 사용할 때 테이블 별칭이 허용되지 않는다.
DELETE FROM customer
WHERE 365 < ALL (SELECT DATEDIFF(NOW(), r.rental_date) days_since_last_rental
FROM rental r
WHERE r.customer_id = customer.customer_id);서브쿼리를 사용하는 경우
서브쿼리의 3 종류를 정리해보자.
SELECT문 : 스칼라 서브쿼리WHERE문 : 중첩 서브쿼리FROM문 : 인라인 뷰
실행순서
- 서브쿼리 실행 → 부모쿼리(메인쿼리, 포함구문) 실행
데이터 소스로서의 서브쿼리 : from 문 서브쿼리(인라인 뷰)
FROM문에서 사용되는 서브쿼리는 비상관 관계여야 한다. (상관 서브쿼리 X)- 서브쿼리가 먼저 실행되고 부모쿼리가 실행 완료될 때까지 데이터는 메모리에 보관된다.
예제 : from 절에 서브쿼리를 사용하여, 고객의 이름, 성, 총 대여횟수, 총 지불금액을 요약하는 보고서를 만들어보자.
- 고객의 이름, 성 → Customer 테이블
- 총 대여횟수, 지불금액 → Rental 테이블
SELECT
c.first_name
, c.last_name
, pay.num_rental
, pay.total_payments
FROM customer c
INNER JOIN (SELECT
customer_id
, COUNT(*) AS num_rental
, SUM(amount) AS total_payments
FROM payment
GROUP BY customer_id
) AS pay
ON c.customer_id = pay.customer_id ; - 서브쿼리에는
pay라는 별칭이 지정되고,customer_id를 기준으로 customer 테이블과 조인된다. pay서브쿼리에서 가져온 열과 함께 customer 테이블에서 고객의 성, 이름을 검색한다.
❶ 데이터 구성
서브쿼리를 사용해 데이터베이스에 존재하지 않는 데이터를 생성할 수도 있다. 이렇게 만들어진 데이터는 마치 테이블처럼 보이지만 쿼리가 실행될 때만 임시적으로 생성되는 뷰view다. 어떤 보고서를 만들때 등에 유용하게 쓰인다.
예제 : 고객을 지불금액별로 그린, 실버, 골드 등급으로 구분하고 각 등급별 고객이 몇명이나 있는지 알아보자.
일단 지불금액별 등급은 아래와 같다. (단위: 달러)
| 등급(그룹명) | 하한 | 상한 |
|---|---|---|
green | 0 | 74.99 |
silver | 75 | 149.99 |
gold | 150 | 9,999,999.99 |
SELECT
pay_grp.name
, COUNT(*) number_customers
FROM (SELECT
customer_id
, COUNT(*) AS num_rentals
, SUM(amount) AS total_payments
FROM payment
GROUP BY customer_id
) AS pay
INNER JOIN (SELECT 'green' name, 0 low_limit, 74.99 high_limit
UNION ALL
SELECT 'silver' name, 75 low_limit, 149.99 high_limit
UNION ALL
SELECT 'gold' name, 150 low_limit, 9999999.99 high_limit
) AS pay_grp
ON pay.total_payments
BETWEEN pay_grp.low_limit AND pay_grp.high_limit
GROUP BY pay_grp.name ; 쿼리문을 해석해보면 아래와 같다.
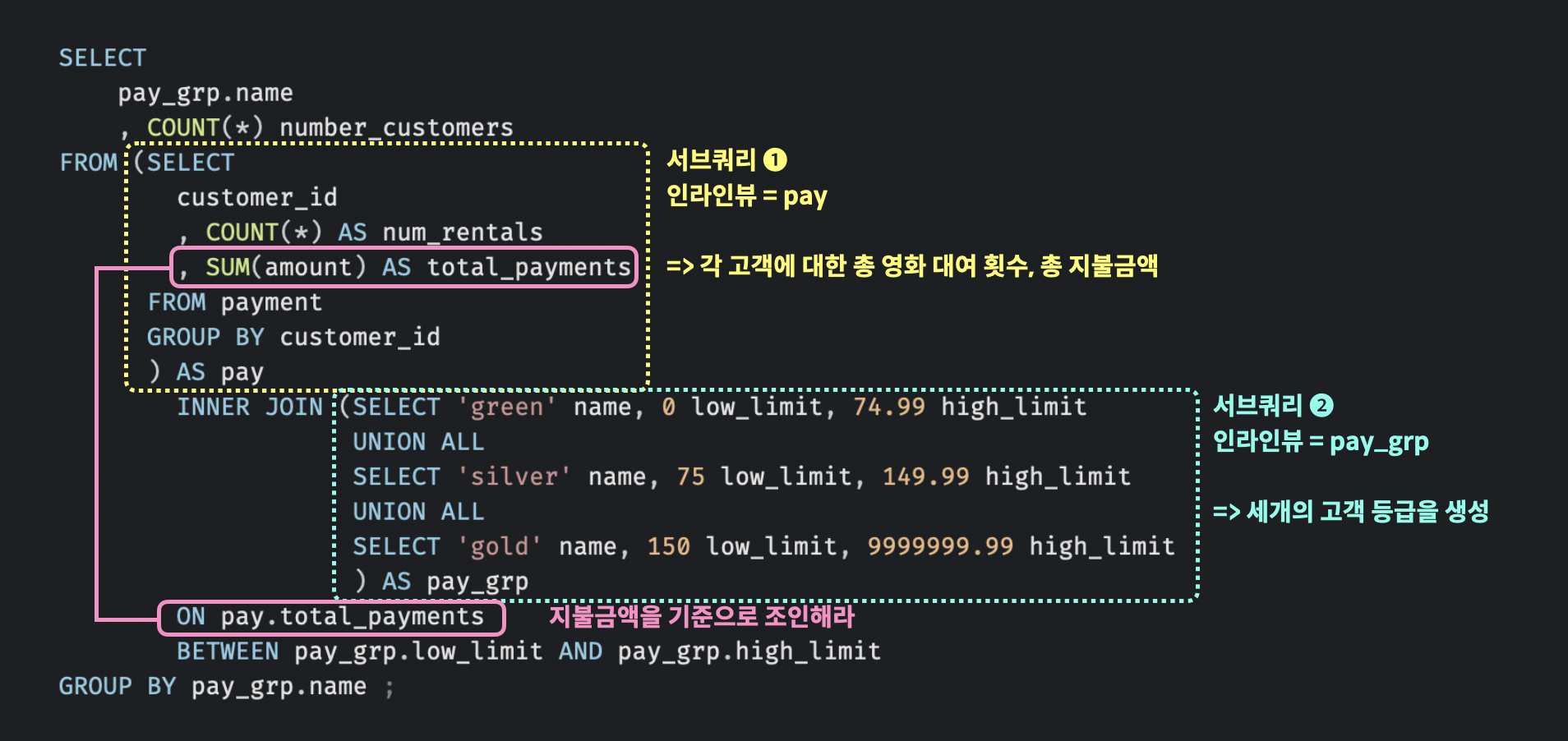
2개의 서브쿼리는 등급 이름(green, silver, gold)별로 그룹화되어 조인된다.
❷ Task-oriented 서브쿼리
예제 : 각 고객의 이름, 성, 도시, 총 대여횟수, 총 지불금액을 보여주는 보고서를 만들어보자.
생각해보면 고객의 이름, 성, 도시는 결과에서만 보여지면 되고, 그룹화에 필요한 대부분의 데이터는 payment테이블에 있음을 알 수 있다. 이런 경우에
- ( 고객ID , 총 대여횟수, 총 지불금액 ) 을 서브쿼리로 불러오고
- 나머지 고객의 이름, 성, 도시를 서브쿼리와 조인하면 좋다.
customer_id로만 그룹화가 수행되기 때문에 쿼리가 훨씬 빠르게 실행된다.
SELECT
c.first_name
, c.last_name
, ct.city
, pay.total_payments
, pay.total_rentals
FROM (SELECT
customer_id
, SUM(amount) total_payments
, COUNT(*) total_rentals
FROM payment
GROUP BY customer_id
) AS pay
INNER JOIN customer c
ON pay.customer_id = c.customer_id
INNER JOIN address a
ON c.address_id = a.address_id
INNER JOIN city ct
ON a.city_id = ct.city_id ; ❸ 공통 테이블 표현식 (CTE: Common Table Expression)
파생테이블과 마찬가지로 쿼리문이 끝날 때 까지만 지속되는 일회성 테이블이지만, 쉼표(,)를 통해 여러 CTE를 만들고 앞에 정의된 CTE를 참조할 수 있다.
사용방법 :
WITH 테이블명 AS (SELECT ...)
예제 : 성이 S로 시작하는 배우가 출연하는 PG 등급의 영화로 인해 발생한 총 수익을 계산해보자.
- (1) 성이 S로 시작하는 배우를 찾아야 하고,
- (2) PG등급의 영화를 찾고 (1)과 조인해야 한다.
- (3) payment 테이블과 조인해 영화 지불금액을 계산해야 한다.
WITH actors_s AS
(SELECT
actor_id
, first_name
, last_name
FROM actor
WHERE last_name LIKE 'S%') ,
actors_s_pg AS
(SELECT
s.actor_id
, s.first_name
, s.last_name
, f.film_id
, f.title
FROM actors_s AS s
INNER JOIN film_actor AS fa
ON s.actor_id = fa.actor_id
INNER JOIN film AS f
ON fa.film_id = f.film_id
WHERE f.rating = 'PG'),
actors_s_pg_revenue AS
(SELECT
spg.first_name
, spg.last_name
, p.amount
FROM actors_s_pg AS spg
INNER JOIN inventory AS i
ON i.film_id = spg.film_id
INNER JOIN rental AS r
ON i.inventory_id = r.inventory_id
INNER JOIN payment AS p
ON r.rental_id = p.rental_id)
SELECT
spg_rev.first_name
, spg_rev.last_name
, SUM(spg_rev.amount) total_revenue
FROM actors_s_pg_revenue AS spg_rev
GROUP BY spg_rev.first_name, spg_rev.last_name
ORDER BY 3 DESC ; 표현식 생성기로서의 서브쿼리
스칼라 서브쿼리는 필터조건 뿐 아니라 SELECT, ORDER BY, INSERT 문의 values 등 표현식이 있는 모든 곳에서 사용할 수 있다.
✏️ 서브쿼리 요약 정리
- 단일 열 / 단일 행, 다중 행이 있는 단일 열, 다중 열 / 다중 행을 반환할 수 있다.
- 비상관 서브쿼리일 경우, 부모 쿼리(포함구문)와 독립적이다.
- 따라서 서브쿼리만 실행시켜도 동작한다.
- 상관 서브쿼리일 경우, 부모쿼리에서 하나 이상의 열을 참조한다.
- 따라서 서브쿼리만 실행할 수 없다.
JOIN과 사용하지 말자.
- 단일 열 / 다중 행을 반환할 경우,
IN,NOT IN,EXISTS,NOT EXISTS와 같은 비교 연산자를 조건에서 사용할 수 있다.IN은INNER JOIN혹은EXISTS로 사용해도 같은 결과다.
NOT IN은LEFT JOIN혹은NOT EXISTS로 사용해도 같은 결과다. - 서브쿼리는
SELECT,UPDATE,DELETE,INSERT문에서 쓸 수 있다.INSERT문의valuesUPDATE문의set
SELECT,FROM,WHERE,HAVING,ORDER BY절에서 사용할 수 있다.- 임시테이블처럼 사용할 수 있다.
