{kind=link}
특정 기준에 맞게 데이터를 그룹화하고, max, min, avg, sum, count와 같은 집계함수를 통해 데이터를 분석할 수 있다.
그룹화의 개념
나는 DVD 대여점의 사장이다. 예를 들어 우수 고객에게 무료 대여 쿠폰을 주는 이벤트를 진행하고 싶다고 가정해보자. 그럼 다음과 같이 생각할 것이다.
- 우수 고객의 기준은 뭐지? → 대여를 많이 한 사람을 우수고객으로 해야겠다.
- 그럼 '많이'의 기준은 뭐지? → 대여횟수가 40회 이상인 사람으로 정하자.
이 데이터를 구하기 위해서는 다음 작업이 필요할꺼다.
- 고객ID 당 대여횟수 구하기 → 집계함수
count()사용 - 대여횟수가 높은 순서로 정렬하기 →
ORDER BY - 대여횟수가 40 이상인 고객ID만 추리기 → 필터조건을 어디에 넣어야 하는가?
먼저 대여 테이블에서 고객ID를 불러와보자.
SELECT customer_id
FROM rental ;
----------
16,044 rows in set16,000개가 넘는 데이터가 나왔다. 1명의 고객이 1번 이상 대여했기 때문이다.
단일 그룹화
group by 절을 사용하여 고객ID 별로 그룹화하고, 집계함수 count(*)를 사용해 그룹화한 고객ID 별 대여횟수를 알아보자.
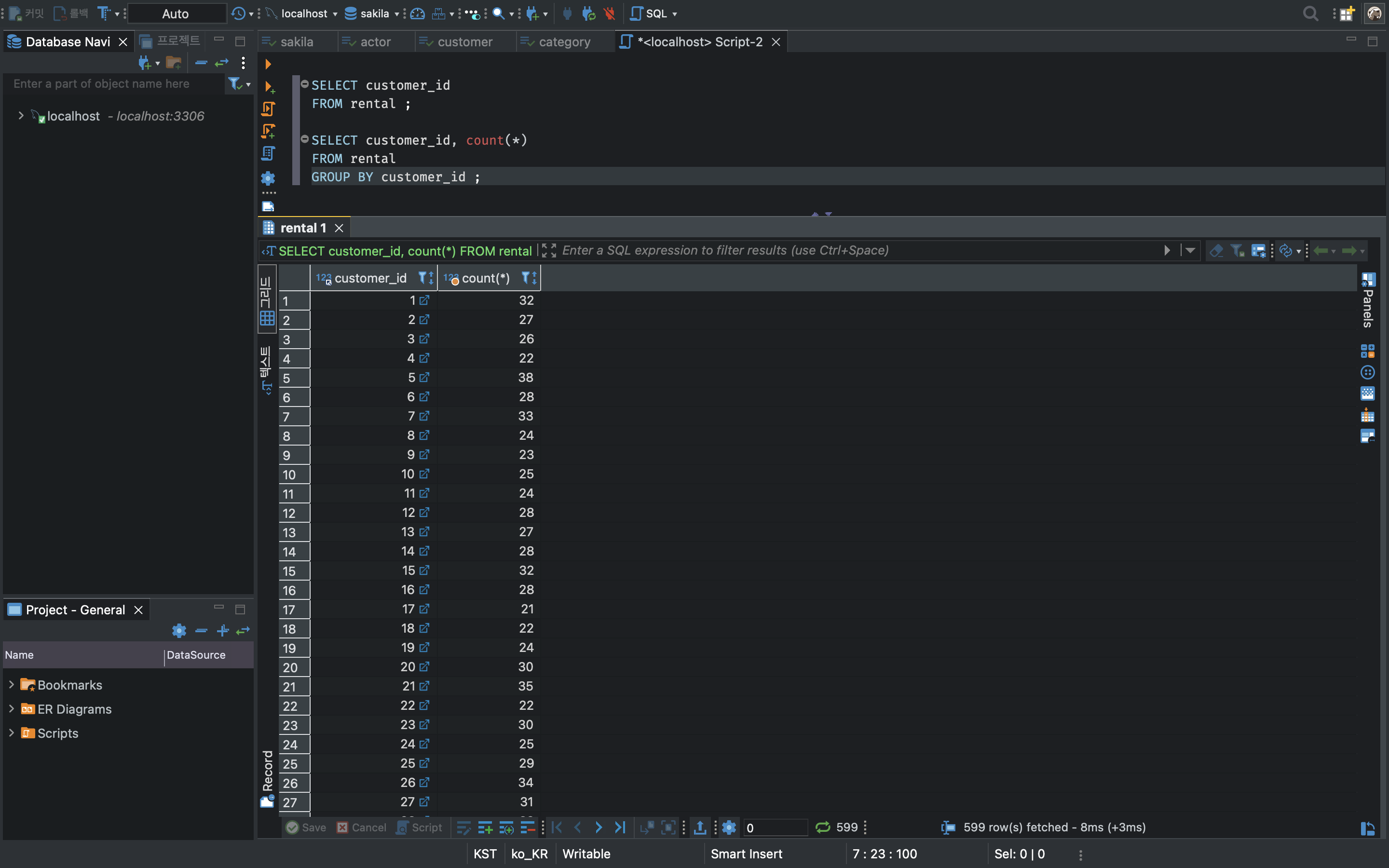
결과를 보면 고객ID가 1인 사람은 32번 DVD를 대여했고, 고객ID가 2인 사람은 27번 대여한걸 알 수 있다. 그럼 대여횟수가 높은 순서로 정렬해보자. 2번째 컬럼인 count(*)를 내림차순 정렬을 사용해야 하므로 ORDER BY 2 DESC를 붙인다. 그리고 대여횟수가 40회 이상인 고객들만 나타나게 하기 위해서 HAVING 절을 사용해 필터조건을 추가한다.
SELECT customer_id, count(*)
FROM rental
GROUP BY customer_id
HAVING count(*) >= 40
ORDER BY 2 DESC ;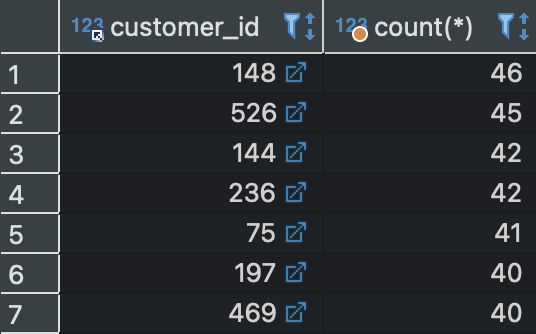
그룹화 전 where에 필터조건을 쓸 수 없는 이유
WHERE 절을 사용하여 필터조건을 추가하면 아래와 같은 쿼리를 쓸 것이다.
SELECT customer_id, count(*)
FROM rental
WHERE count(*) >= 40
GROUP BY customer_id;WHERE 절이 적용될 때는 고객ID 별로 그룹화가 되기 전이므로 count(*) 집계함수를 참조할 수가 없다.
집계 함수
max(): 집합 내의 최대값을 반환min(): 집합 내의 최소값을 반환avg(): 집합의 평균값을 반환sum(): 집합의 총합을 반환count(): 집합의 전체 레코드(행=row) 수를 반환
위와 같은 내장 집계함수를 사용하여 데이터의 기술통계량을 쉽게 볼 수 있다. 영화 대여료의 데이터를 요약해보자.
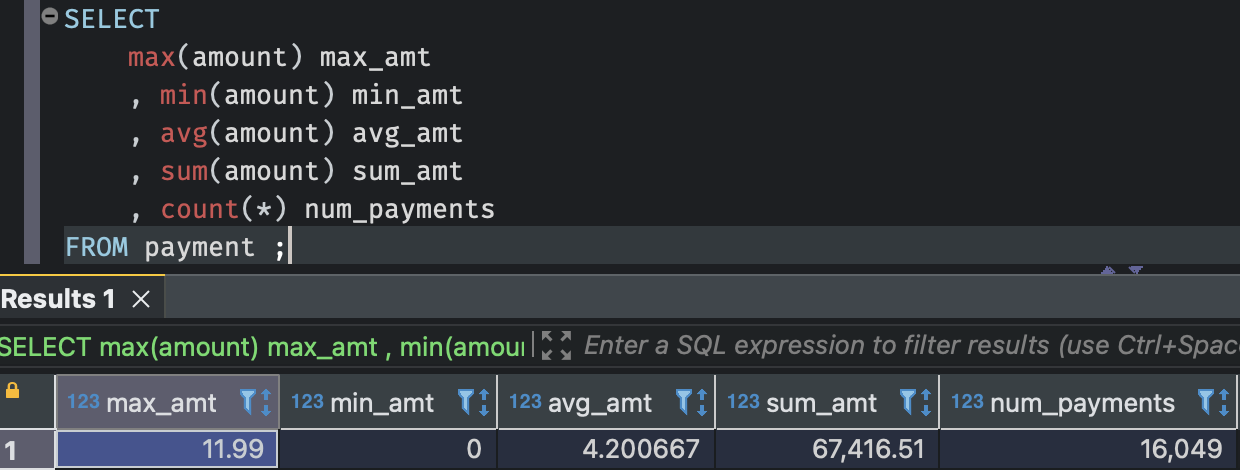
집계함수를 통해서 이번달 매출액, 이번주의 매출액, 이번주 최대 대여료를 가진 영화 리스트 등 다양한 데이터를 뽑아낼 수 있을 것이다.
데이터가 그룹화되는 방법을 명시적으로 지정하자.
위에서 모든 고객에 대해 최대 대여료, 최소 대여료, 평균 대여료, 대여료 총합, 지불횟수를 봤다. 이번에는 각 고객들에 대한 기술통계량을 보고싶다.
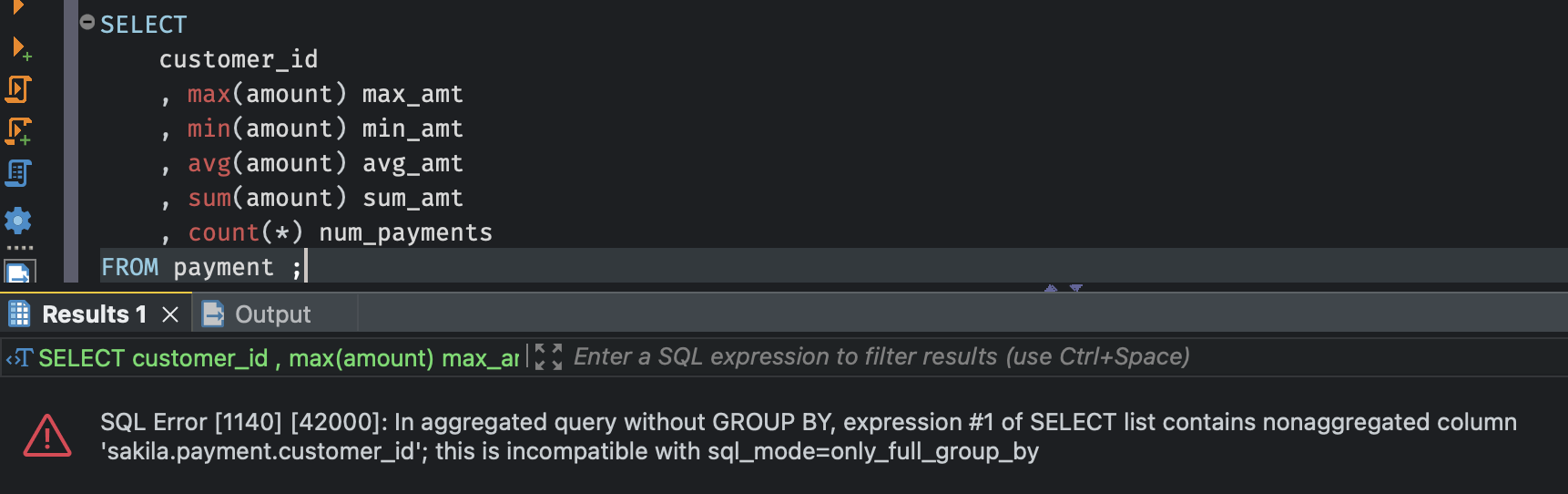
GROUP BY를 통해 데이터가 그룹화되는 방법을 지정하지 않았다는 에러가 발생한다.
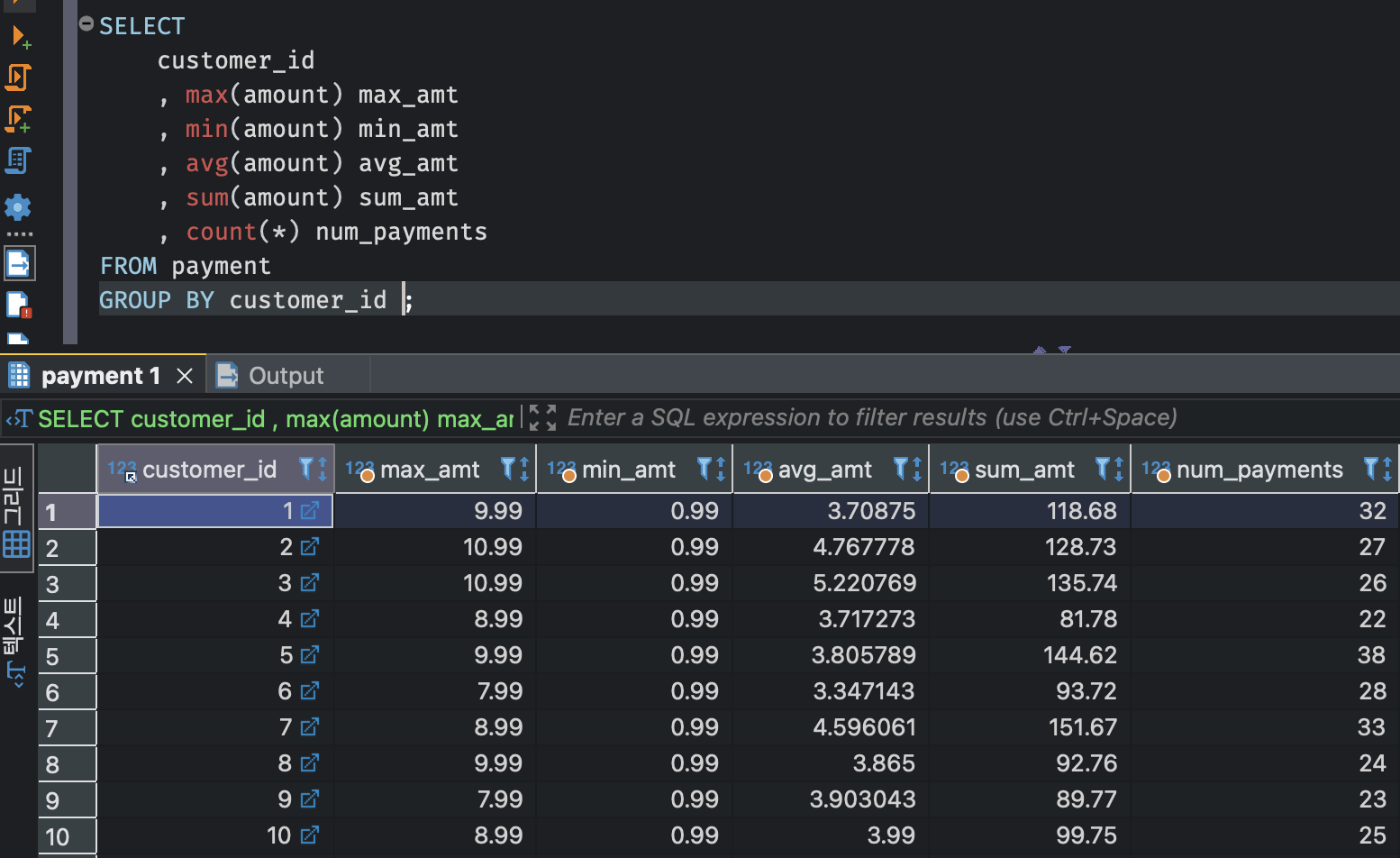
이제 각 고객들에 대한 데이터 요약을 볼 수 있다. GROUP BY 절을 포함시키면, 서버는 먼저 customer_id 값이 동일한 행들을 그룹화한 다음 → 5개의 집계함수를 599개의 각 그룹(고객 ID별 그룹 1개)에 적용한다.
고유한 값 계산
데이터 수를 가져오는 count() 함수를 사용할 때, 중복이 포함된 모든 행의 개수를 가져올지 고유한 값(distinct value)에 대해서만 가져올지 선택할 수 있다.
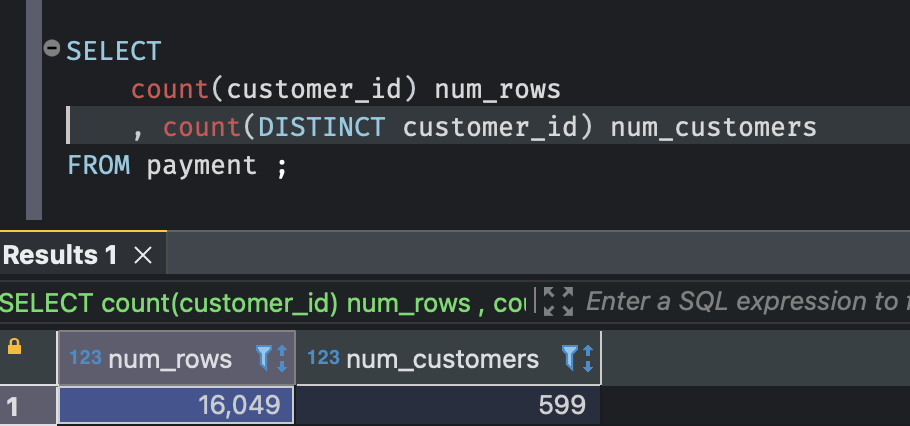
count(DISTINCT 값) 으로 계산된 num_customers는 지불횟수가 여러번이더라도 고객ID라는 고유값을 기준으로 중복을 제거한 599개의 결과만 보여진다.
표현식 사용
함수를 사용할 때 ( ) 안에 어떤 column 외에 표현식도 사용할 수 있다.
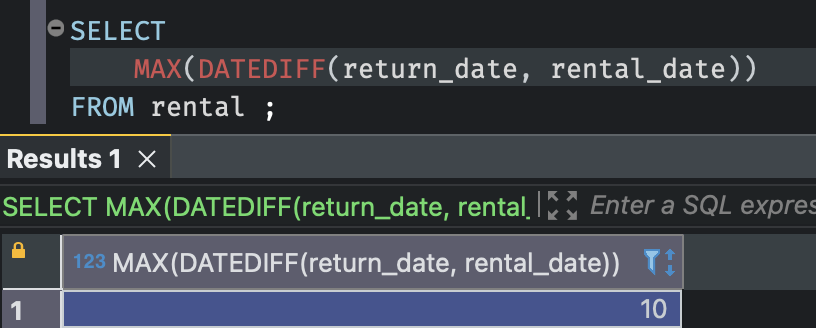
예를 들어, 영화를 대여한 후 반납하기까지 걸린 최대 일수를 구하고 싶다고 해보자.
시간 데이터를 다루는 이 포스팅에서 배운 datediff() 를 집계함수 안에 사용할 수 있다.
Null은 어떻게 처리될까?
집계를 하거나 모든 유형의 숫자를 계산할 때는 항상 null 값이 계산 결과에 어떤 영향을 미칠지 고려해야 한다.
numbers 라는 이름의 테이블을 하나 만들고, 숫자 자료형의 {1, 3, 5} 데이터셋을 채워넣어보자.
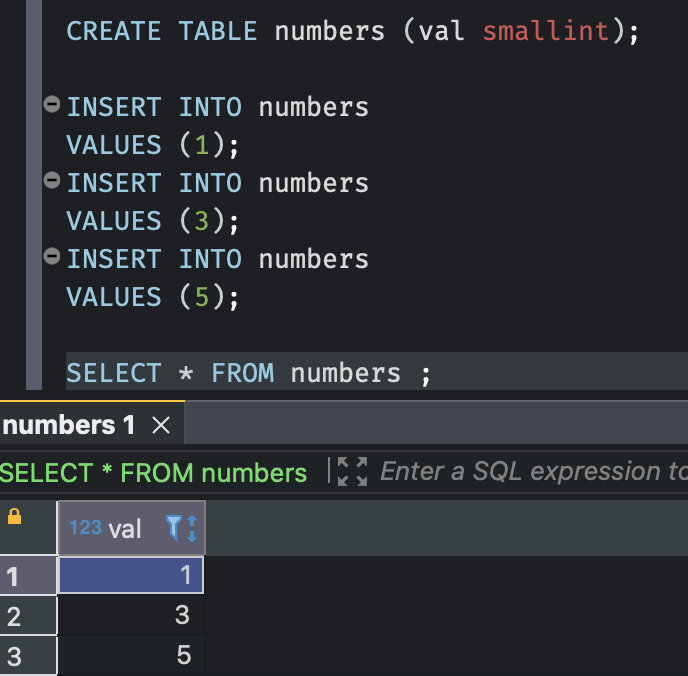
val 이름의 열에 1, 3, 5의 숫자자료형의 데이터가 채워넣어진걸 알 수 있다.
이 테이블에 null이 있을 때와 없을 때 집계함수의 결과가 어떻게 달라지는지 확인해보자.
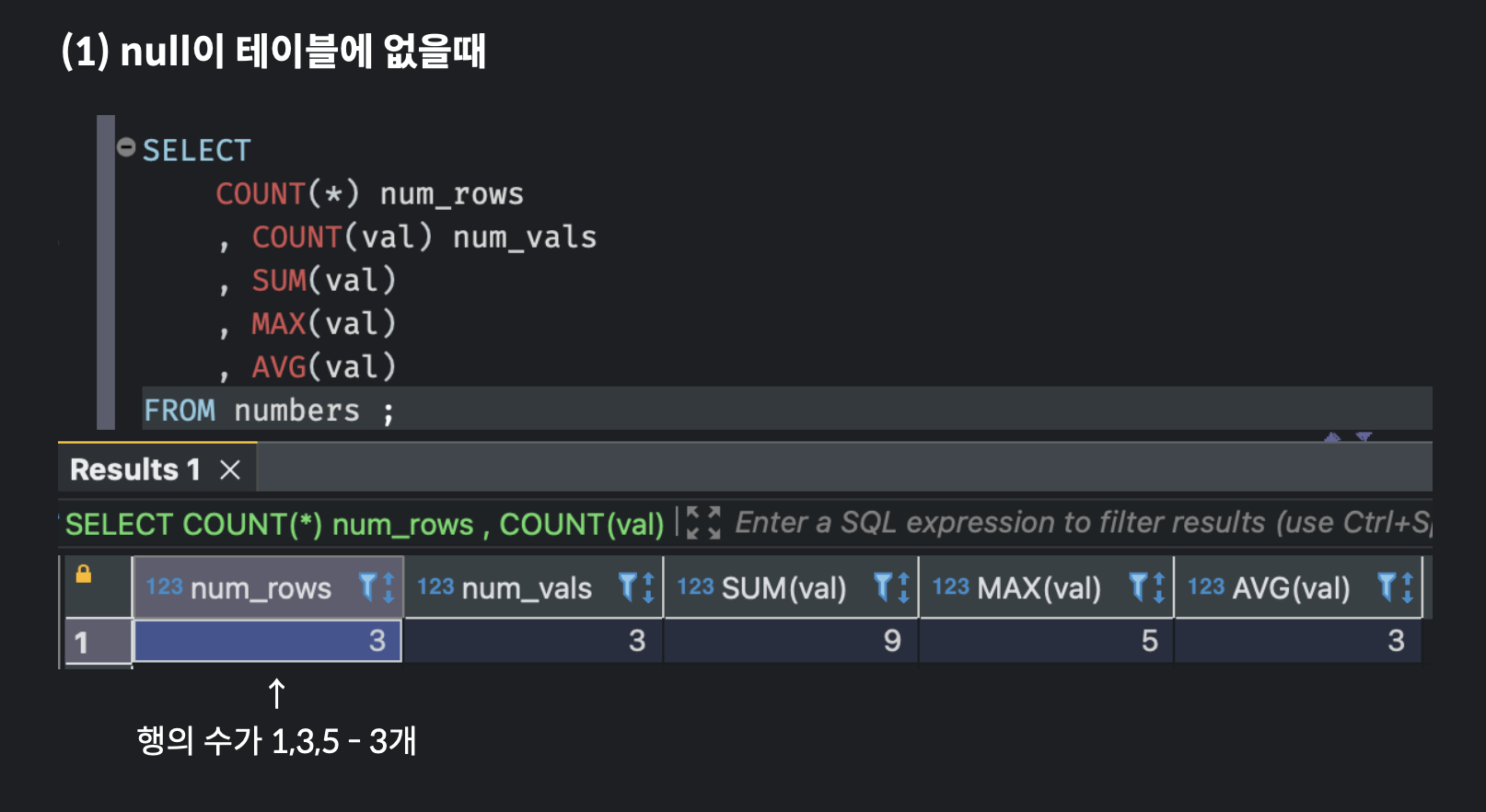
그럼 INSERT INTO 함수를 통해 null값을 테이블에 삽입한 뒤, 동일하게 count(*), count, sum, max, avg 함수를 실행해보면 어떨까?
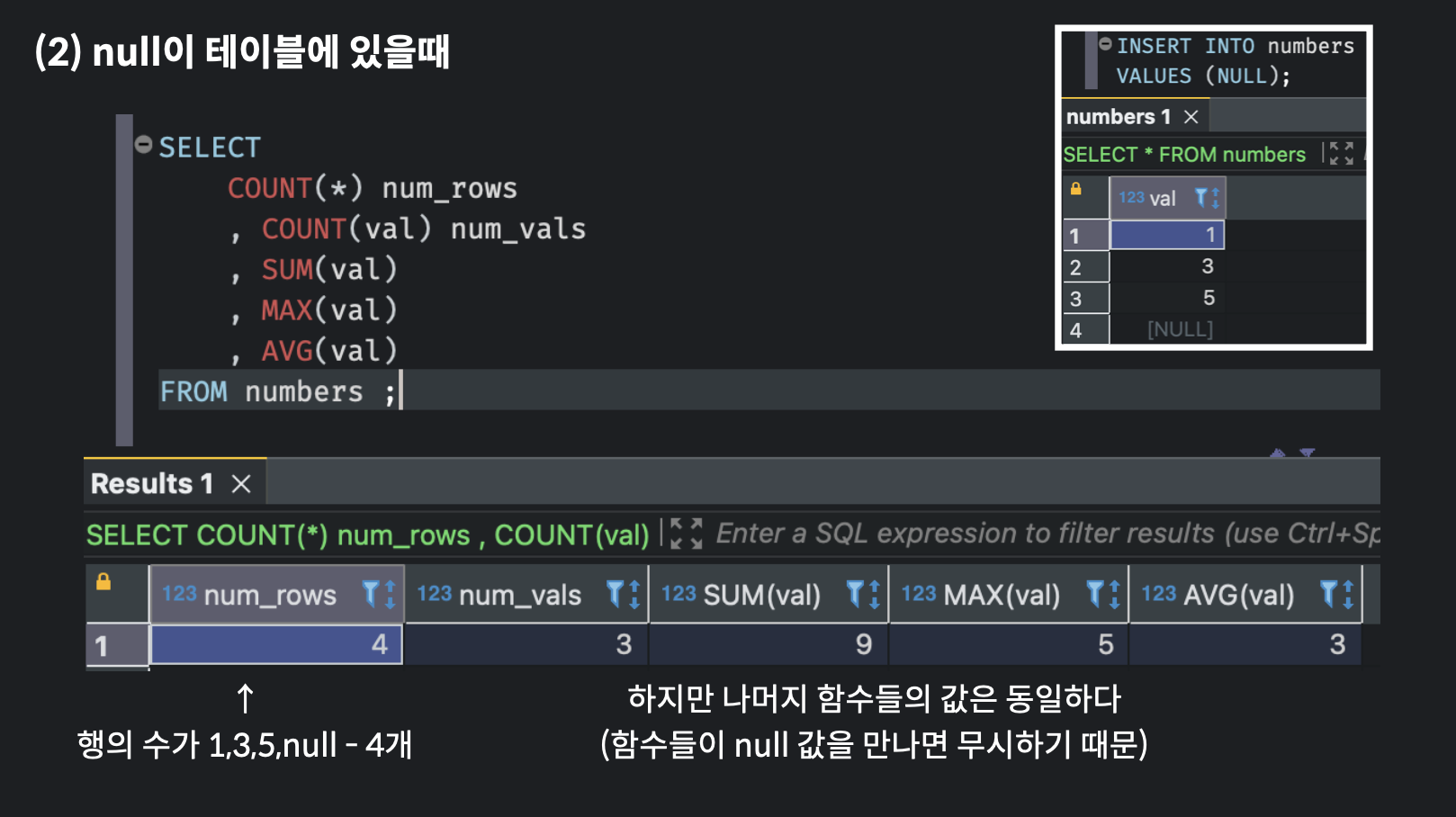
count(*)은 행의 갯수를 세므로 1개가 늘어난 4가 되었다.- 나머지 함수들은
null값을 만나면 무시하기 때문에 변화가 없다. count(*)는 전체 행 수를 세는 반면,count(val)은 val열에 저장된 값 수를 계산하기 때문에null값을 무시하고 센다.
그룹 생성
우리는 주로 특정 조건에 부합하는 데이터를 찾고 싶어한다. 예를 들면,
- 전체 판매량 중 특정 지역의 판매량 총계
- 2021년 최고 영업사원
- 매월 대여한 영화 수의 빈도
이를 위해서는 데이터를 그룹화(GROUP BY)할 수 있어야 한다.
단일 열 그룹화
앞에서 살펴봤던 가장 단순한 그룹화 유형이다.
그룹화의 개념
다중 열 그룹화
하나 이상의 열을 이용해 그룹을 생성하는 것을 말한다. 2개 이상의 테이블을 조인할 수도 있다.
예를 들어, 각 배우가 출연한 영화의 등급별 영화 개수를 알고 싶다면?
- 각 배우가 출연한 영화에 대한 정보는 film_actor 테이블에 있다.
- 영화의 등급에 대한 정보는 film 테이블에 있다.
- 개수는
count()함수로 구할 수 있다.
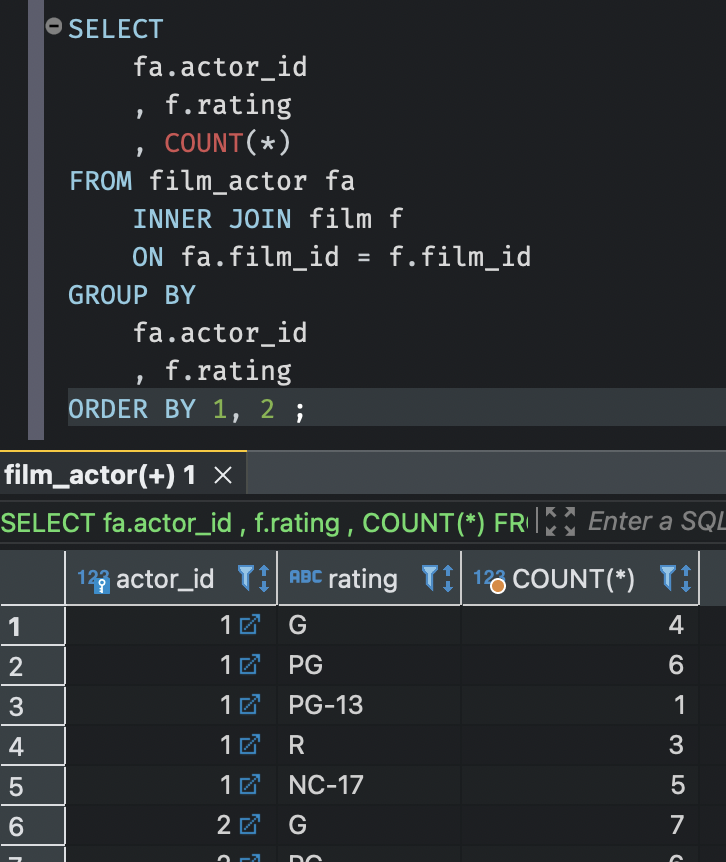
- 먼저
film_id를 기준으로 film_actor테이블과 film테이블을 조인하고, - 배우ID 와 등급을 기준으로 그룹화한뒤 각 행의 갯수를 세는
count(*)함수를 사용했다.
결과를 보면 1번 ID의 배우는 G등급의 영화에 4번, PG등급의 영화에 6번, PG-13등급 영화에 1번, R등급 영화에 3번, NC-17등급 영화에 5번 출연한 걸 알 수 있다.
with rollup
그룹별로 합계를 구하고 싶을 때 with rollup 을 사용한다.
예를 들어, 위의 예시에서 각 배우가 출연한 영화의 등급별 영화 개수를 구하되, 배우별로 출연한 영화의 총 갯수를 별도로 표시하고 싶다고 하자.
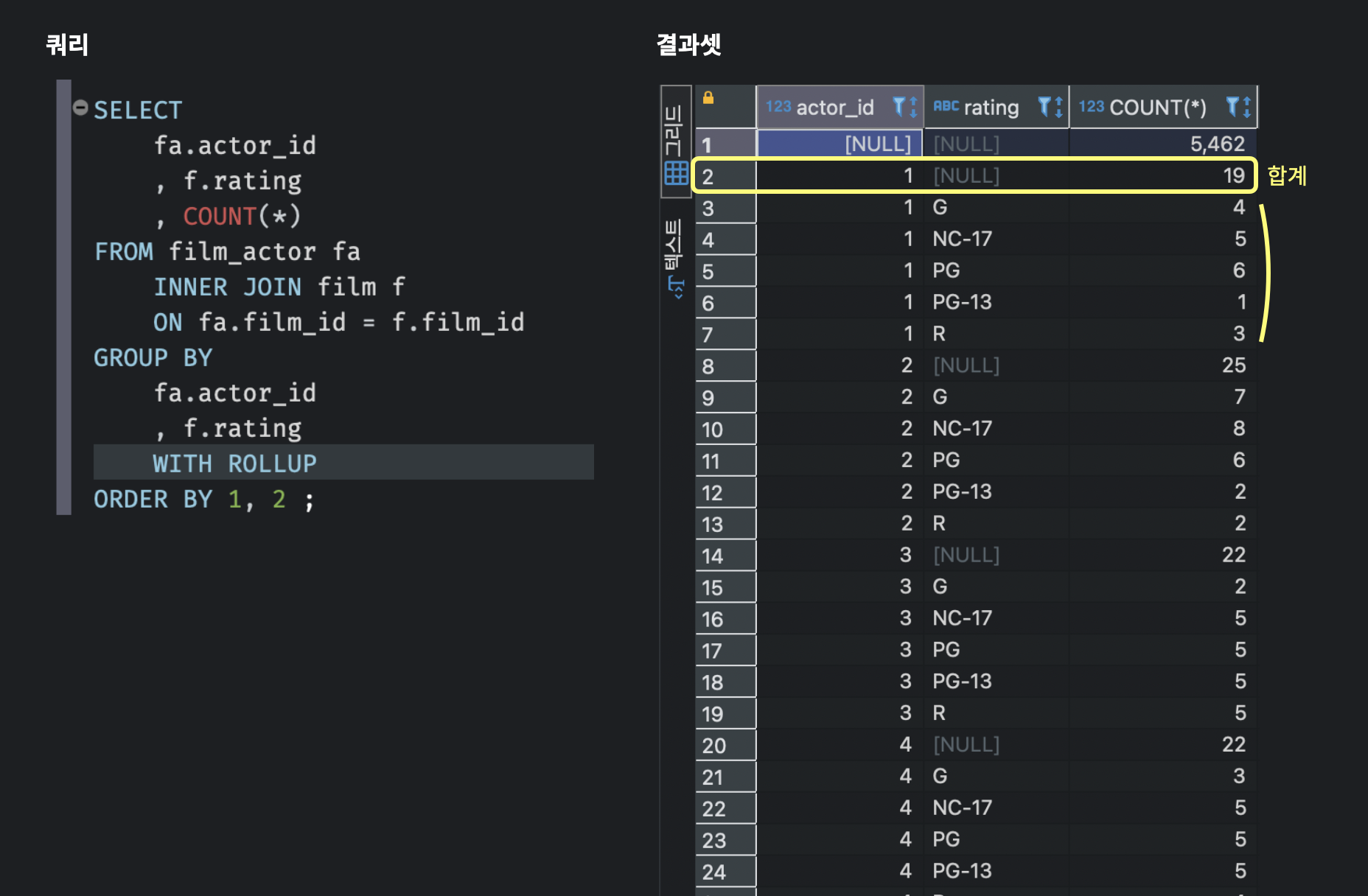
GROUP BY 절 마지막에 WITH ROLLUP옵션을 사용하면 맨 위 행에 [NULL] 이라고 표시된 부분에 배우ID별 출연 영화 개수의 합이 나타난다.
그룹화와 표현식
표현식으로 생성한 값을 기반으로도 그룹화가 가능하다.
예를 들어, 2005년과 2006년에 각각 DVD 대여횟수가 어떤지 총합을 계산해보자.
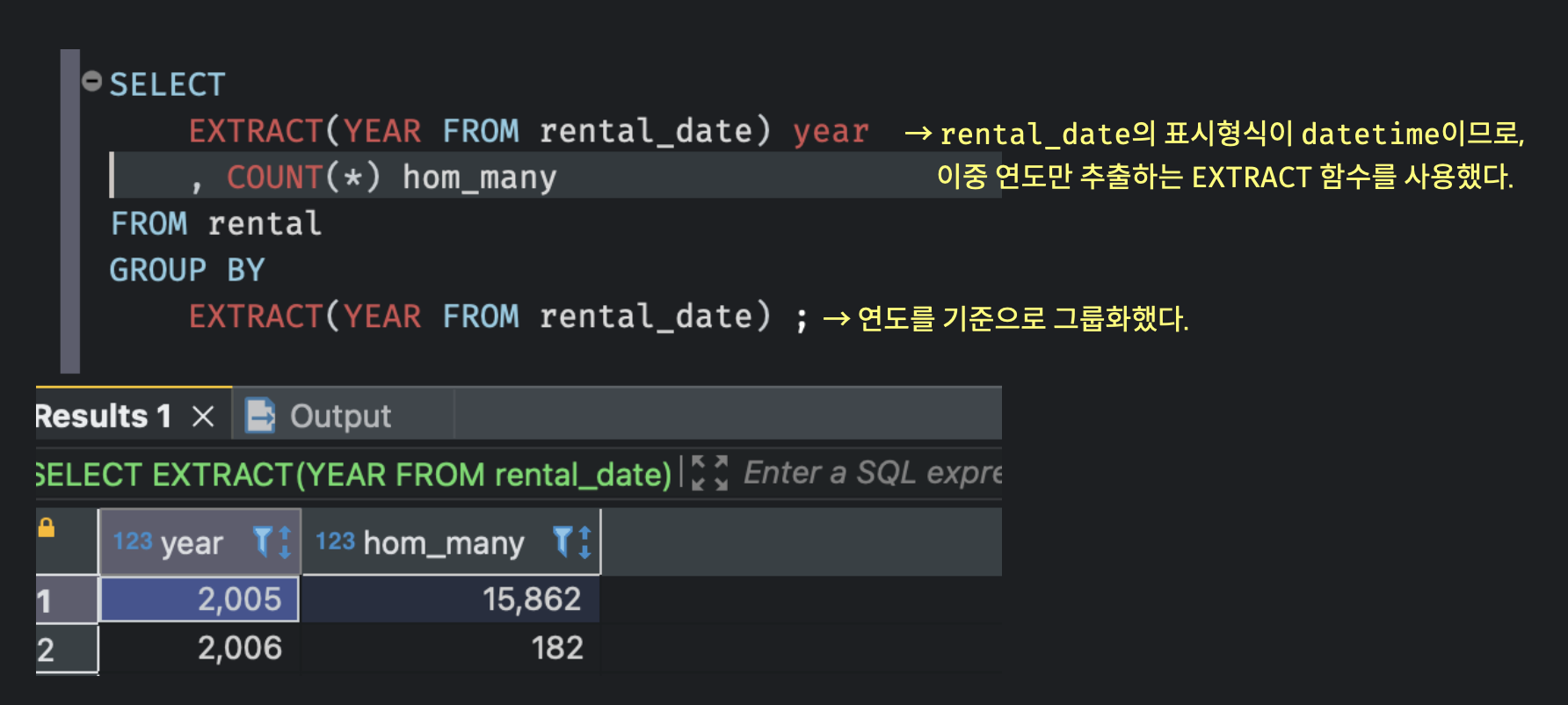
- 문자열을 반환하는 시간함수 포스팅 바로가기 (
dayname,extract)
그룹 필터조건
앞에서 그룹화 전 WHERE 절에 필터조건을 추가하였을 때 에러가 발생하는 예제를 살펴봤다.
그룹화 전 where에 필터조건을 쓸 수 없는 이유
데이터를 그룹화할 때는 그룹이 생성된 후에 HAVING 절에 데이터에 대한 필터조건을 줄 수 있다. 물론, 그룹화 전에도 필터조건이 동작하는 경우라면 WHERE절에 넣어도 된다. 이 경우에 쿼리에는 WHERE절과 HAVING절, 2개의 필터조건이 존재한다.
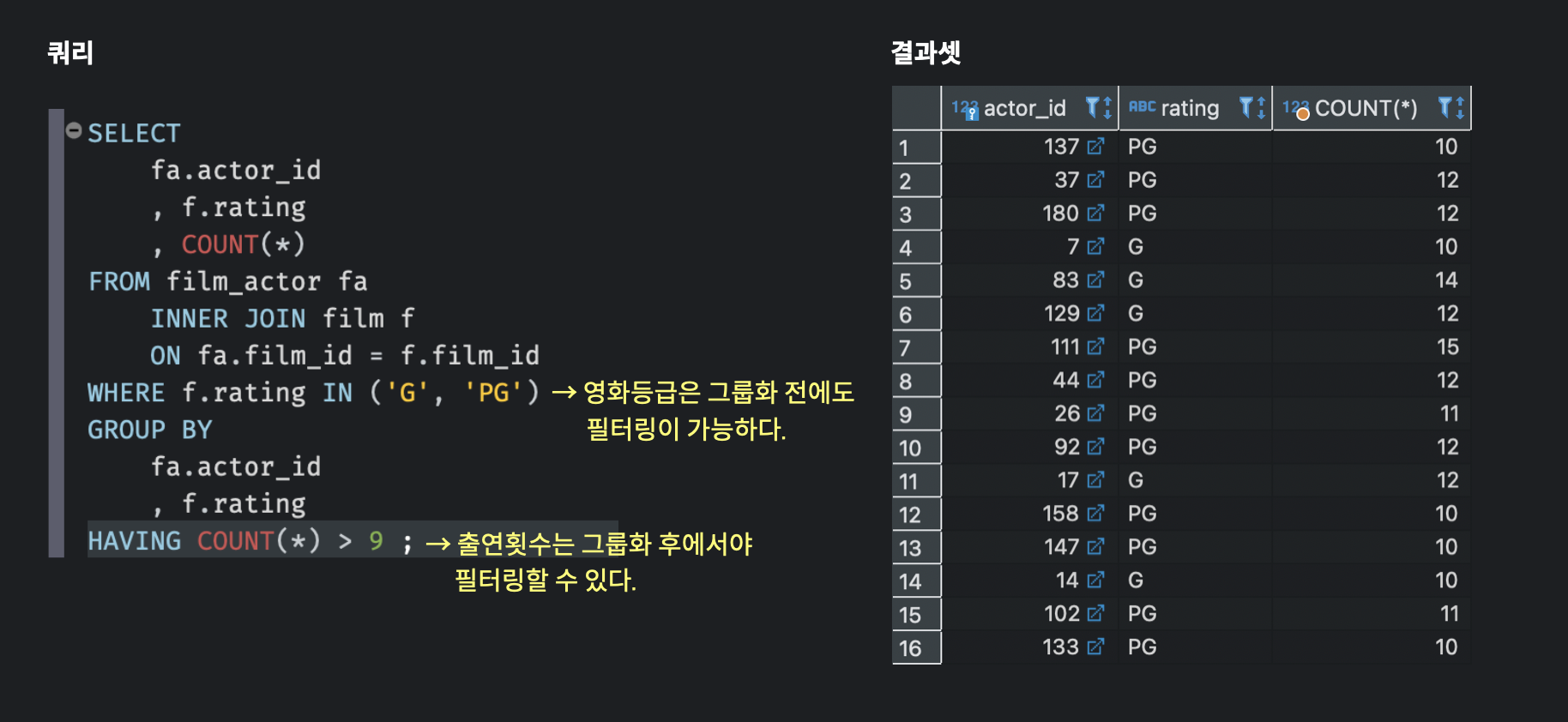
예를 들어, G 또는 PG 등급의 영화에, 10번 이상 출연한 배우들만 골라보고 싶다고 하자.
- 조건1 : G 또는 PG 등급 외의 영화에 출연한 배우ID는 제거한다.
- 조건2 : 10번 미만 출연한 배우ID는 제거한다.