1. 딥러닝 개념
1) 챗봇 종류
| 종류 | 비용 | 전문성 | 시간 | 설명 |
|---|---|---|---|---|
| 대화형 | 매우 높음 | 매우 높음 | 매우 높음 | 자연어 처리를 기반으로 해 자연스러운 대화 가능 |
| 트리형 | 매우 낮음 | 낮음 | 보통 | 정해진 트리구조를 따라 답변을 얻을 수 있는 형태. 인공지능 아님. |
| 추천형 | 보통 | 보통 | 많음 | 표면상 대화 형태이지만, 인공지능을 기반으로 하거나 하지 않는다. 대화형으로 가기 위한 중간 과정으로 사용하기도 함 |
| 시나리오형 | 보통 | 보통 | 보통 | 제공해야할 서비스, 결과물이 결정되어 있을 때 자주 사용. 유형 중 투자 대비 효과가 가장 좋다고 알려짐, 단계별로 고객 이탈율 분석이 용이 |
| 결합형 | 위의 유형을 조합해서 설계한 챗봇 |
2) 트랜스포머
(1) 인코더와 디코더 구조
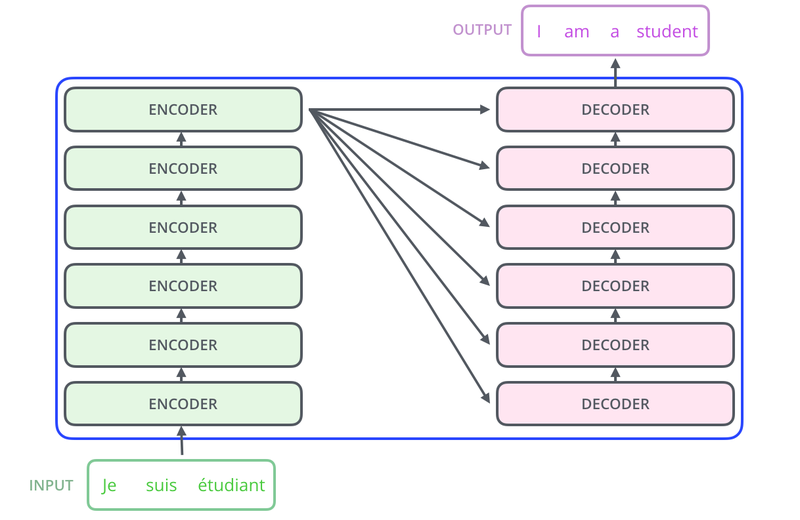
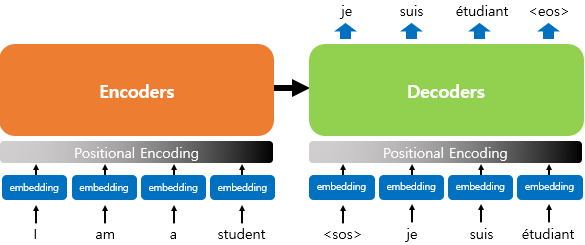
- RNN 계열 타 모델과의 차이: 임베딩 벡터에서 positional encoding 과정을 거친 후 입력값으로 사용함.
- 순차적으로 입력받지 않고 한 번에 입력을 받기 때문
- RNN에서는 문장을 구성하는 단어가 어순대로 입력되기 때문에, 모델에게 어순 정보를 별도로 알려줄 필요 없음
- 하지만 트랜스포머는 문장의 모든 단어를 한 번에 입력받기 때문에 어순 정보를 알려줘야함. 이때 위치 정보를 가진 벡터(positional encoding)를 이용해서 더해줌.
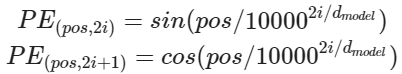
- positional encoding에 이용될 벡터 값은 sin 함수와 cos 함수를 이용해 구함
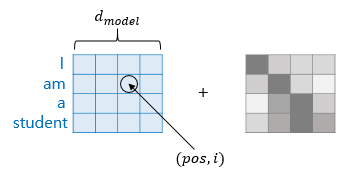
- pos: 입력 문장에서의 임베딩 벡터의 위치
- dmodel: 임베딩 벡터의 차원
- i: 임베딩 벡터 내의 차원의 인덱스
- 순차적으로 입력받지 않고 한 번에 입력을 받기 때문
(2) 어텐션
- query, key, value: 단어 벡터(트랜스포머의 여러 연산을 거친 후임. 임베딩 벡터 아님)
| 종류 | 위치 | 역할 |
|---|---|---|
| 인코더 셀프 어텐션 | 인코더 | 인코더의 입력된 문장 내의 단어 간 유사도 판별 |
| 디코더 셀프 어텐션 | 디코더 | 단어를 하나씩 생성하며 이미 생성된 앞의 단어와의 유사도를 구함 |
| 인코더-디코더 어텐션 | 디코더 | 디코더의 예측 성능을 높이기 위해 인코더에 입력된 단어들과의 유사도를 구함 |
-
셀프 어텐션: 현재 문장 내에서 유사도를 구하는 것. 다른 문장의 단어 아님
- ex) 대명사 it이 지칭하는 것이 무엇인지 유사도를 측정하는 것.
-
Scaled Dot Product Attention: 어텐션 값 구하는 방식
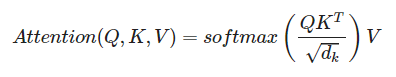
- 쿼리에 대해서 모든 키와의 유사도를 구함
- 유사도를 키와 매핑된 값에 반영
- 값을 모두 더함 = Attention Value
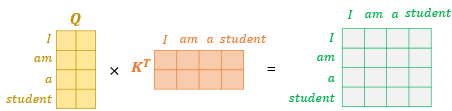
- Q와 K를 곱해서 벡터 생성해 단어 벡터의 유사도 기록된 유사도 행렬 생성
-
ex) 새로운 벡터에서 am행과 student의 열 값은 Q 행렬에 있던 'am' 벡터와 K행렬에 있던 'student' 벡터의 내적 값(=유사도)을 의미함.
참고
벡터의 내적과 유사도
- 스케일링을 위해 행렬 전체를 특정 값으로 나눔
- 유사도를 0~1 사이로 normalization 하기 위해 소프트맥스 함수 사용
- 문장행렬 V를 곱하면 Attention Value 생성
-
Multi Head Attention
- 어텐션을 병렬로 수행하는 방식
- 한 번만 셀프 어텐션을 수행할 경우 놓칠 수 있는 정보를 num_heads를 설정해 여러 번의 셀프 어텐션을 거침으로써 다양한 관점에서 어텐션을 가능하게 함
(3) 마스킹
- 패딩 마스킹: 패딩 토큰 사용
- 패딩: 문장의 길이가 다를 때 모든 문장의 길이를 동일하게 맞추는 과정에서, 기준이 되는 길이보다 짧은 문장에 숫자 0을 추가해 문장의 길이를 맞추는 자연어 처리의 전처리 방식
- 패딩 과정에서 생기는 0은 실제 의미가 없기 때문에 어텐션 등의 연산에서 제외시켜야 함. 이러한 과정을 위해 패딩 마스킹은 0의 위치를 체크함.
- Look-ahead masking
- 디코더로 사용되는 경우
- RNN은 문장의 단어가 차례로 들어가기 때문에 다음 단어를 예측할 때 앞서 나온 단어만을 기반으로 예측함
- 반면 트랜스포머는 단어가 한 번에 입력되기 때문에 모든 단어를 참고해 다음 단어를 예측할 수 있음. 하지만 이전 단어를 기반으로 다음 단어를 예측하는 훈련을 시키는 것이 목적이기 때문에, 이러한 면에 있어서 제한 사항이 필요함.
- 방법 중 하나가 뒤에 나올 단어를 가리는 마스킹 기법
2. 회고
챗봇을 만들어 봤는데 생각보다 재밌었다. 두 가지 중 선택할 수 있는 질문을 건냈을 때 엉뚱한 답을 내놔서 좀 무서워지는 것도 있었는데 어떤 식으로 개선하면 좋을지 궁금하다. 그리고 주관식 질문에 상황에 따라 답이 다르겠다는 식으로 답을 하는 걸 보고 좀 놀랐다. 물론 답을 명확히 주는게 좋겠지만 어쨌든 자연스럽게 진짜 대화하듯이 답을 한 점이 신기했다. 그리고 단순한 감상을 입력했을 때도 항상 그런 건 아니지만 몇몇의 경우 맥락에 맞는 답을 했던 점도 인상깊었다. 역시 이미지보단 텍스트를 다루는 게 더 재밌는 거 같다.

🐬 파이썬 / 인공지능 / 머신러닝