1. 퀴즈 푸는 인공지능 만들기
1) 단어 사전 구축
- subword segmentation - 단어를 형태소 단위로 나누는 방식과 비슷함.
- 예) 읽었다 ⇒ 읽+었다 (중심부를 중점으로 분리)
- SentencePiece 모델
- koNLPy를 통해 형태소 분석기를 사용할 수 있는데, 이를 이용해 subword를 중심으로 단어 사전을 구축할 수 있음.
- SentencePiece 같은 경우 한 언어의 문법 규칙에 국한되지 않은 통계적인 방법을 사용해 어떤 언어에든 보편적으로 적용 가능하다.
2) BERT의 모델 구조
- 기본구조
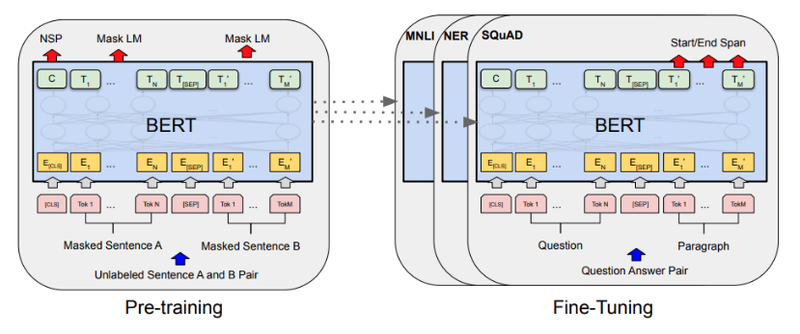
- Transformer: self-attention으로 이뤄진 encoder-decoder 구조를 가지고 있음
- BERT: Transformer의 encoder 구조를 사용. 몇 가지 변화를 주지만 기본적인 구조는 동일함.
- layer는 12개 이상으로 늘림
- 전체적인 파라미터의 크기가 커짐
- Mask LM
- 문장의 빈칸에 올 수 있는 알맞은 단어를 찾을 수 있게 하는 언어 모델
ex) '나는 <mask> 먹었다 '에서 <mask>에 들어갈 단어 찾기
- Next Sentence Prediction
- 두 가지 문장이 주어졌을 때 두 문장이 순서대로 이어지는 문장이 맞는지 판단하는 문제
ex) '나는 밥을 먹었다. <SEP> 그래서 지금 배가 부르다.'에서 <SEP>을 경계로 문장의 순서가 맞는지 판별
- Token Embedding
- text의 tokenizer로 Word Piece model이라는 subword tokenizer을 사용함.
- Segment Embedding
- transformer엔 없음.
- 각 단어가 어느 문장에 포함되는지 그 역할을 규정함
ex) 단어가 Question 문장에 속하는지, Context 문장에 속하는지 구분이 필요한 경우 사용
- Position Embedding
- Transformer의 position embedding과 동일
2. 회고
학습시간이 엄청 오래 걸렸다. 어떤 식으로 진행하는지 알려주는데 잘 이해가 안갔다. 내용을 다시 살펴봐야할 것 같다.

🐬 파이썬 / 인공지능 / 머신러닝