ImageNet Classification Challenge 2015년애 우승을했으며, 현재까지 다양하게 사용되는 ResNet에 대하여 알아봅시다.
ResNet의 등장
2015년에 Batch Normalization과 함께 혁신적인 아이디로 나타난 ResNeT은 기존의 10~20 정도에 머물던 layer의 수를 152개로 증가시켰던 모델입니다.
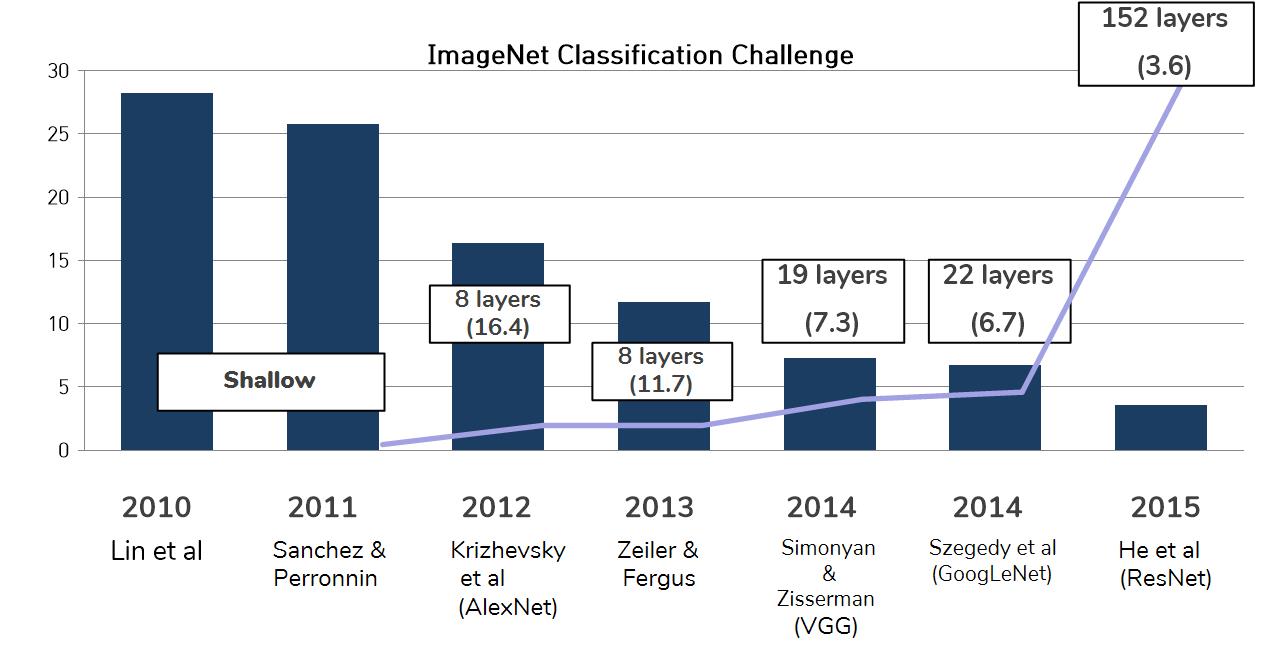
위의 그림과 같이 ResNe이 등장하면서 layer의 깊이도 크게 깊어졋는데요.
그렇다면, 지금까지 ResNet이 등장하기 전에는 왜 ResNet 만큼 깊게 쌓지 못했는지 알아 봅시다.
ResNet 이전 깊은 모델의 인식
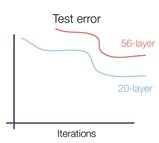
ResNet이 나오기 이전에는 Batch Normalization을 했음에도 깊은 모델이 얕은 모델보다 성능이 더 안좋았다고 합니다.
- 이 이유로는 당시 사람들이
train set을 너무 많이 배웠으니까 test set에 맞지 않는것 아닐까?하는 overfitting 문제로 생각했습니다.
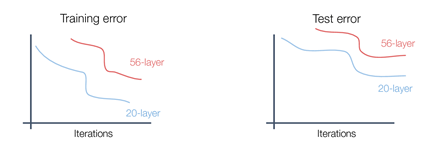
그렇지만 Training error에서도 깊은 모델의 성능이 더 안좋아서 overfitting 문제가 아닌 모델의 training 자체가 잘 안된 underfitting 문제가 발생한 것을 알게 되었습니다.
- 깊은 모델이 얕은 모델을 재현(모방)한다고 생각했지만, 실제로는 Optimization 문제였습니다.
기존의 네트워크 구조에서는 깊은 모델이 학습이 잘안되니 기존의 구조를 바꿔서 학습을 진행한 것이 바로 Residual Network입니다.
그럼 Residual Network에서의 가장 큰 혁신 2가지를 소개하겠습니다.
shortcut connection
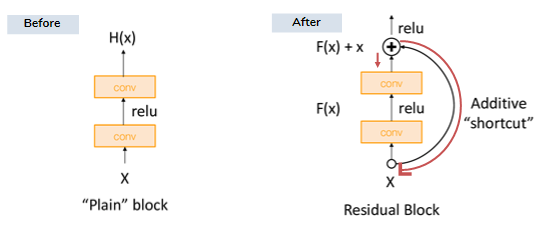
기존의 방식은 layer의 깊이가 깊어질 수록 Gradient가 사라지는 문제인 (Vanishing gradient)를 가지고 있지만 ResNet에서 기존의 input x에 대한 결과 H(x)에 x를 더한 형태로 구성이 됩니다.
여기서 진행할 block을 학습하지 않고 다음 block으로 보내는 방법을 shortcut라고 합니다.
- 이런 shortcut방식을 통해 해당 block의 학습 과정 중에서 gradient가 사라져도 block를 학습 하기 전 x를 추가로 더하기에 (Vanishing gradient) 문제를 경감 시킬 수 있게 되었습니다.
blcok 구조를 H(x), 새로운 구조를 F(x) + x라 할 때, shortcut해서 나온 구조를 수식으로 보면 H(x) = F(x) + x가 되고 이는 곧 H(x) - x = F(x)가 되게 됩니다.
저 H(x) - x = F(x) 부분이 ResNet에서 가장 핵심인데, H(x)는 현재 block까지의 과정을 거친 값이고 x는 그 전 과정의 block 값이니 결국 잔차(Residiual)를 가지고 학습을 했다는 것입니다.
이 부분을 생각해보면 왜 Residual Networks라는 이름이 붙었는지 알 수 있겠죠.
computational graph 관점
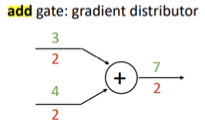
그리고 이것을 computational graph 관점에서 얘기를 하면,
더하기 노드 같은 경우 업 스트림 Gradient를 카피한 후 동일한 다운스트림 Gradient를 보내기 때문에, gradient가 중간에 사라지는 문제인 (Vanishing gradient)를 경감시킬 수 있게 됩니다.
Bottleneck Block
shortcut과 더불어서 ResNet에서 나온 또다른 혁신 방법인 Bottleneck Block입니다.
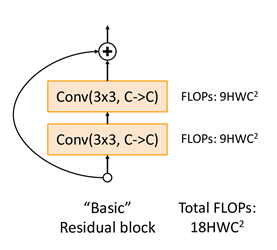
위의 그림과 같이 기존의 Residual block은 한 block에 Convolution layer(3x3)을 2개 가진 구조였습니다.
이 구조를 다음 그림과 같이 바꾸었습니다.
.PNG)
위의 conv(3x3) 2개를 가진 basic block을 Bottleneck이라 불리는 다음 구조로 바꾸었습니다.
layer의 수는 더 많아졌지만, computational cost가 줄어들게 되었습니다.
그리고 layer가 많아짐은 곧 활성화 함수가 기존보다 더 들어간다는 의미이고 이는 더 많은 non-linearity가 들어가게 되면서 Input을 다양하게 가공할 수 있음을 나타냅니다.
이러한 shortcut connection과 Bottleneck block으로 Residual Networks는 보다 깊게 layer를 쌓을 수 있게 되었죠.
ResNet ImageNet top-5 error rate
- ResNet의 Stage와 ImageNet top-5 error rate는 다음 표와 같습니다.
.PNG)
위의 표를 보시면 ResNet-50부터 Bottleneck Block이 들어간 후 Block Typ은 Bottleneck 구조를 사용합니다.
그리고 ImageNet top-5 error가 layer를 쌓을수록 감소하는 것을 알 수 있네요.
ResNet에 관한 내용을 마치며,
ResNet의 구조는 현재까지도 많이 쓰이고 ResNet 네트워크의 원리를 이용한 네트워크들도 있으니 ResNet가 무엇인지 아는것도 나중에 도움이 될것 같습니다.
