
회귀분석 (Regression)
회귀분석(Regression Analysis)이란 통계학에서 전통적으로 많이 사용되던 분석 방법으로, 관찰된 여러 데이터를 기반으로 각 연속형 변수간의 관계를 모델링하고 이에 대한 적합도를 측정하는 분석 방법입니다.
1. 선형 회귀 분석(Linear Regression)
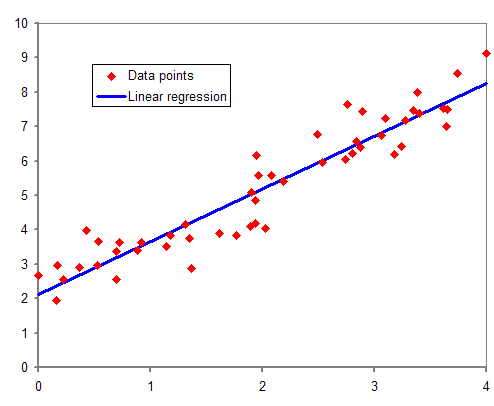
출처 :선형 회귀 위키
선형 회귀 분석은 회귀 분석의 대표적인 방법이며,
선형 회귀(linear regression)라는 이름에서 알 수 있듯이, 종속변수 Y와 한 개 이상의 독립변수 X와의 선형 상관관계를 모델링하는 회귀분석 기법입니다.
여기서 독립변수의 개수에 따라 한 개의 독립변수를 가지고 있는 방식은 단순 선형회귀, 둘 이상의 독립변수를 가지고 있는 경우에는 다중 선형회귀라고 불립니다.
- 독립(설명)변수 : 입력값이나 원인
- 종속(반응)변수 : 결과물이나 효과
1.1 선형 회귀 모델링
선형회귀식은 다음과 같이 나타낼 수 있습니다.
여기서 는 회귀계수라고 불리고 는 종속 변수와 독립 변수 사이에 오차를 의미합니다. 이 두개의 값은 우리가 데이터로부터 추정해야 하는 파라미터가 됩니다.
결국 와 에 해당하는 데이터가 있을 때, 이러한 데이터로부터 와 를 추측한 후 추측한 값들을 바탕으로 모델링을 수행합니다. 그 다음 해당 모델을 기반으로 새로운 데이터의 값들을 입력으로 넣어주었을 때, 그에 해당하는 값을 예측하게 되는 것이죠.
- 선형회귀 모델을 구하는 것은 주어진 데이터에 우리의 선형 식이 잘 맞도록 회귀계수 및 오차를 구하는 것 을 의미합니다.
1.2 머신러닝에서의 선형회귀모델 표기법
위에서 표현했던 선형회귀모델을 머신러닝 기반의 방법에서는 다음과 같이 다른 변수명을 써서 표현합니다.
위의 식에서는 를 가정(Hypothesis), 를 가중치(Weight), 를 편향(bias)로 부릅니다.
머신러닝 혹은 딥러닝 기법을 이용해서 회귀 모델을 구한다는 얘기는 바로 주어진 데이터를 이용하여 (가중치) 와 (편향)를 구한다는 얘기 입니다.
선형 회귀모델에서의 회귀계수 값이 , 오차 값이 에 해당합니다. 결국, 머신러닝에서의 선형회귀모델도 H를 예측하기 위해 적절한 W(가중치)와 b(편향)을 찾아내는것 이라 생각할 수 있습니다.
1.3 용어 설명
회귀분석에서 사용되는 용어중에 잔차와 최소제곱법의 의미는 다음과 같습니다.
-
잔차(Residuals)
우리가 회귀모델을 이용해 추정한 값과 실제 데이터의 차이를 의미합니다. 만일 우리가(3,15)이라는 데이터를 가지고 있고, 선형 회귀모델의 식이 이라고 가정한다면, 해당 데이터에 대한 잔차 값은 [15(실제 데이터 y값) - 13(실제 데이터의 x값을 모델에 대입했을 때의 추론된 y값) = 2]가 됩니다. -
최소제곱법(method of least squares)
잔차를 이용하여 주어진 점 데이터들을 가장 잘 설명하는 회귀모델을 찾는 가장 대표적인 방법 중 하나이며,
근사적으로 구하려는 해와 실제 해의 오차의 제곱의 합이 최소가 되는 해를 구하는 방법입니다.- 이를 간단히 설명하면 잔차가 가장 적은 파라미터를 찾는것을 말합니다.
n 개의 점 데이터에 대하여 잔차의 제곱의 합을 최소로 하는 W, b를 구하는 방법입니다.
참고로 머신러닝에서는 최소제곱법과 같은 회귀계수를 구하는 과정에 쓰는 함수를 손실함수(Loss function)이라고 합니다.
그리고 회귀모델이 잘 구해졌는지 확인할 때 참고하는 지표로 결정계수(R-squared, 또는 R2 score , )라는 것이 있습니다. 이는 회귀모형의 설명력을 표현하는것으로 0에서 1 사이의 값으로 나타납니다.
그리고 0에 가까울수록 설명력이 낮고, 1에 가까울수록 회귀모델의 설명력이 높은다고 볼 수 있습니다.
- 결정계수(설명력)이 1에 가까울 수록 회귀모델이 데이터를 잘 표현한다고 생각하시면 됩니다.
2. 로지스틱 회귀분석(Logistic Regression)
로지스틱 회귀분석(Logistic Regression)은 데이터가 어떤 범주에 속할 확률을 0에서 1 사이의 값으로 예측하고 그 확률에 따라 가능성이 더 높은 범주에 속하는 것으로 분류해주는 지도 학습 알고리즘입니다.
이 과정을 간단히 나타내면 다음과 같습니다.
- 어떤 범주에 속하는지 확률로 예측
- 더 높은 확률을 가진 범주로 분류
즉 1개 이상의 독립변수가 있을 때 이를 이용하여 데이터가 2개의 범주 중 하나에 속하도록 결정하는 이진 분류(binary classification) 문제를 풀 때 로지스틱 회귀분석을 많이 사용합니다.
2.1 정의 및 용어 설명
로지스틱 회귀식은 다음과 같이 나타낼 수 있어요. 만일 종속변수가 0일 확률을
라고 한다면, 이를 구하는 식은 다음과 같습니다.
Odds라는 개념은 사건이 발생할 확률을 발생하지 않을 확률로 나눈 값입니다.
유방암 데이터셋에 맞추어 설명한다면, 만일 악성 종양일 확률이 0.2라면 양성 종양일 확률은 자동적으로 0.8이 되니까 다음과 같이 Odds를 계산할 수 있어요.
- 여기서 사건이 발생할 확률은 0.2이고 사건이 발생하지 않을 확률은 1 - 0.2 = 0.8입니다.
위 값에 log를 취한 값을 Log-odds라고 부릅니다. 그런데 이 Log-odds의 형식이 익숙하시지 않나요? 위에서 나온 수식과 같은 형식이 나옵니다. 결국 이 Log-odds라는 값을 선형회귀분석의 종속변수처럼 구하면 됩니다.
위와 같은 식에 주어진 데이터를 이용하면, 주어진 데이터를 잘 설명하는 회귀계수 값을 구할 수 있습니다.
그렇지만 실제로 우리가 원하는 값은 Log-odds 값이 아닌 종속변수가 어떤 확률 값을 갖는지 입니다. 따라서 Log-odds로부터 특정 범주에 속할 확률을 얻기 위해 Log-odds의 식을 에 대해서 다시 정리하게 되면,
와 같은 식을 얻게 됩니다. 해당 수식에서
와 같이 공통 부분을 같은 이름의 변수로 나타내면, 아래와 같이 보다 간결하게 표현할 수 있습니다.
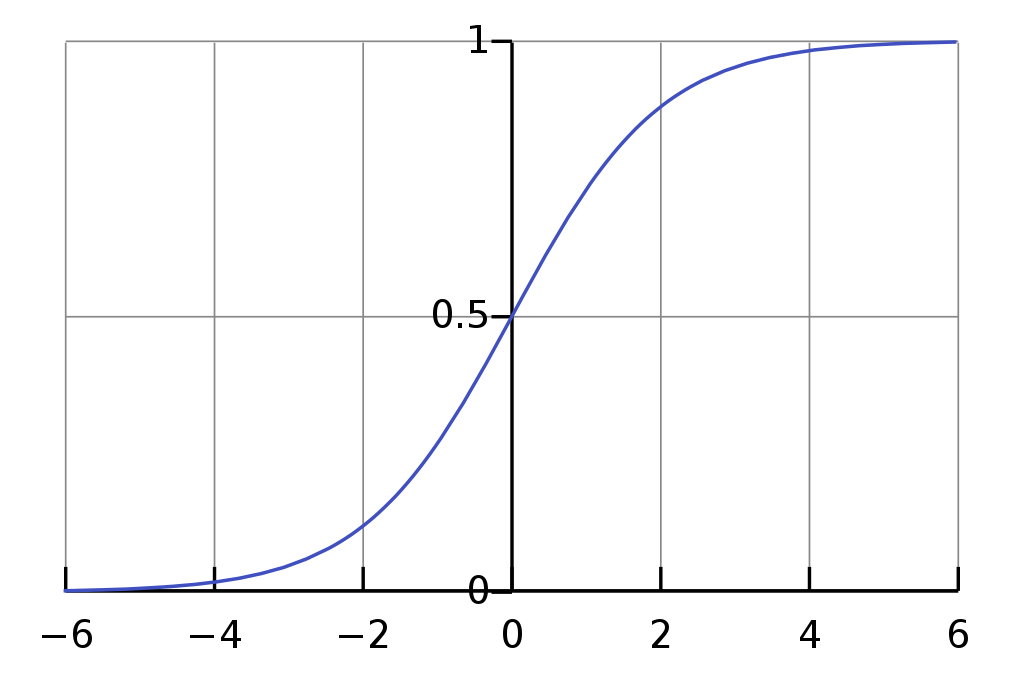
출처 :시그모이드 함수 위키
위의 이미지가 바로 Sigmoid Function의 형태입니다.
그리고 위의 sigmoid 함수는 확률모델을 선형 회귀모델로 표현한 것이 아니라, 위 그래프에서
인 지점을 중심으로 하여 두 범주간 경계가 불명확해지는
의 구간(0.3<p<0.7)을 최소화해 주기 때문에 분류모델의 분류 성능을 매우 향상시켜 줍니다.
결국 Logistic Regression이란 Log-odds 값을 구한다음, 이를 sigmoid function에 넣어서 0에서 1 사이의 값으로 변환된 결과를 가지고 분류하는 알고리즘 이며,
로지스틱 회귀에서 데이터가 특정 범주에 속할 확률을 예측하는 단계는 다음과 같습니다.
- 실제 데이터를 대입하여 Odds 및 회귀계수를 구한다.
- Log-odds를 계산한 후, 이를 sigmoid function의 입력으로 넣어서 특정 범주에 속할 확률값을 계산한다.
- 설정한 threshold에 맞추어 설정값 이상이면 1, 이하면 0으로 이진분류를 수행한다.
