- 피드백은 언제나 환영입니다!
학습 내용
- Instance panoptic segmentation, cGAN, Multi-modal, Transformer 이론
- MNIST 데이터를 생성하는 cGAN 모델 구현
- Visual data & text multi modal 인 Pre-trained CLIP 사용
- 협업을 위한 github 사용법
Segmentation
Instance Segmentation
Semantic segmentation은 픽셀별 classification을 수행한다. 따라서, 다른 개체(instance)더라도 클래스만 같으면 동일한 것으로 인식한다. 반면, instance segmentation은 instance를 구분할 수 있다.
Instance segmentation = Semantic segmentation + Distinguishing instances
Panoptic Segmentation
Semantic segmentation은 class를, instance segmentation은 instance를 구분할 수 있었다면 panoptic segmentation은 class와 instance를 한 번에 구분할 수 있다.
Panoptic segmentation = Semantic segmentation + Instance segmentation
Conditional Generative Model
기존의 generative model은 학습한 분포를 따르는 데이터를 생성할 수 있었다. 하지만 추가적인 조정은 불가능했다. Conditional generative model은 generative model에 사용자의 의도를 반영할 수 있게 한 구조다!
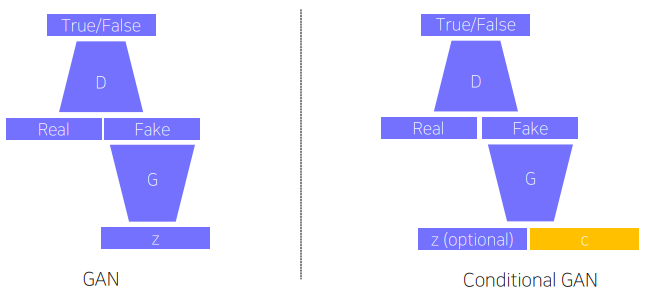
기존 GAN 구조에 discriminator, generator 각각에 condition을 추가한다는 점만 다르다.
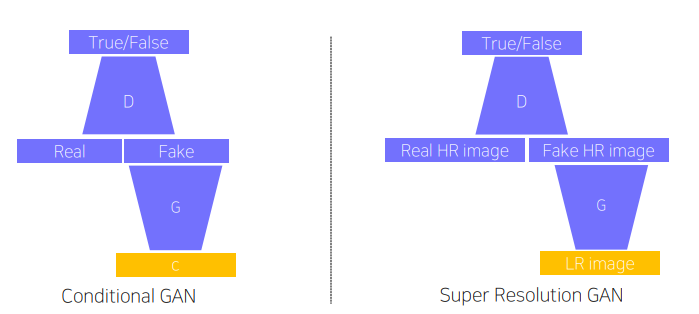
cGAN으로 super resolution, image translation을 수행할 수 있다.
기존에 L1 loss등을 사용하여 수행했던 super resolution은 인접한 픽셀 값을 averaging 하는 식으로 수행했다. GAN loss를 사용한다면 averaging 방식으로 만들어낸 결과물은 discriminator에 의해 저지되므로 상대적으로 선명한 결과물을 얻을 수 있다.
Image translation은 입력 이미지의 style 등을 바꾸는 작업이다.
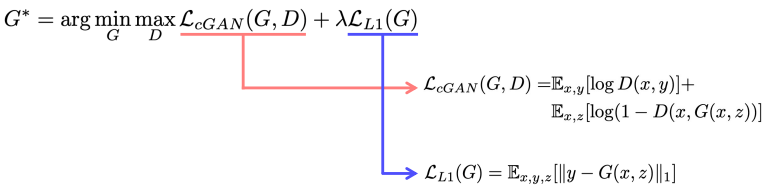
대표적인 모델로 Pix2Pix가 있다. L1 loss, GAN loss를 동시에 사용하여 입력 이미지를 어느정도 따르면서 선명하고 사실적인 결과물을 만들어낼 수 있다.
하지만, supervised 학습을 수행하기에 두 도메인 간 pairwise data가 꼭 필요하다. 이러한 불편함을 해결한 것이 CycleGAN 이다. CycleGAN은 non-pairwise dataset 간 translation을 수행할 수 있다. 양방향 GAN loss와 Cycle-consistency loss를 사용한다.
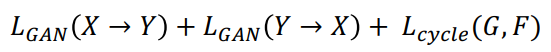
GAN loss는 두 도메인 간 translation을 수행하는 loss다. Cycle-consistency loss는 A -> B 도메인으로 translate하여 나온 결과물을 다시 A 도메인으로 translate 했을 때, 원본과의 loss이다. 이는 GAN loss만을 사용했을 때 나타날 수 있는 학습 불균형(mode collapse) 문제를 방지한다.
한편, GAN은 forward & backward로만 이뤄져있던 모델보다 학습하기 힘들며, 데이터 의존적이라는 단점이 있다. Perceptual loss를 사용하면 forward & backward computation을 사용하여 단순하지만, GAN 처럼 좋은 결과물을 얻을 수 있다. 하지만 학습하기 위해선 pre-trained loss 모델이 필요하다는 단점이 있다. Image transform net과 loss netowrk 두 가지로 이루어져 있다.
- Image transform net : input을 trasnform 한 generated image를 만들어낸다.
- Loss Network : generated image와 target 간 style 및 feature loss를 계산한다. 각각은 generated image와 content target 간 feature maps loss, generated image와 style target 간 gram matric loss를 구하면 된다. Johnson et al., ECCV 2016
Multi-modal
이미지와 소리, 이미지와 문자와 같이 다른 특성(modality)를 가진 데이터 타입들을 같이 활용하는 학습이다. Multi modal 학습 시에는 다음 내용들에 대한 주의가 필요하다.
- 서로의 feature map이 unbalance 하다. (ex. text : image = 1 : n)
- 학습에 효과적인 한 modality에 biased 될 수 있다.
Multi modal로 matching, translating, referencing과 같은 작업들을 수행할 수 있다.
GitHub
추후에 별도 포스팅 예정
피어세션
벌써 5주차라니! 데일리 스크럼이나 피어세션 때, 서로의 피곤한 기색을 더 잘 관찰할 수 있게 되었다😂 그래도 벌써 5주차나 해냈으니까 좀 더 힘내자고 으쌰으쌰 하고 있다. 우리 팀 화이팅!!🤩🤩
이번 주에는 9주차부터 함게 할 프로젝트 팀원 1명을 새로 구했다. 기존 팀원 5명 모두 함께 갔으면 좋았을 텐데, 1명은 research 방향을 원해서, end-to-end로 서비스를 만들어보자는 것과 방향성이 약간 달라 아쉽지만 다른 사람들과 함께하기로 했다.😥
다음 주 부터 시작될 도메인별 competition과, 9주차부터 시작 될 팀 프로젝트를 대비하여 이전에 배웠던 pytorch template을 공부해 오기로 했다. 오픈 소스들을 살펴볼 때 복잡해서 날 괴롭혔던 구조를 공부하고 직접 만들어 볼 생각에 두근거린다!
학습회고
이번 주에는 저번 주와 마찬가지로 각 target task 별 수많은 모델들에 대해 학습했다. 전체적인 흐름을 알아두자는 생각으로 공부했다. 많은 정보량의 디테일들을 다 살펴보기에는 주어진 시간에 비해 나의 학습속도가 느려서 슬펐다..😂😂
이번 주로 도메인별 이론 수업이 끝났다. 다음 주부터 주어진 target task를 팀별로 만들고, 모델 성능으로 다른 팀들과 겨루는 competition이 시작된다. 이 때까지 배운 이론 내용도 다 받아들이지 못한 것 같은데, 벌써 모델을 직접 만들어보는 단계라니! 제대로 할 수 있을지 걱정이 되지만 팀원들과 시행착오를 겪다보면 target task를 수행하는 것을 넘어 성능 개선에 대한 인사이트도 점점 키워 나갈 수 있을 것이다. 점점 캠프 끝난 후의 내가 기대된다!
