
VIT?
Vision Transformer는 Large-scaled Dataset, Model의 위엄을 잘 보여준 논문이라고 생각한다. 정확하게 어떤게 시발점이었는지는 모르지만, VIT논문 발표 이후 대용량 이미지 데이터 기반 모델들이 주를 이루었으며, 해당 모델에 맞는 데이터셋 또한 많이 구축되었다. CNN 기반이 주를 이루었던 Vision분야에서 새로운 방향성을 제시한 Vision Transformer 모델을 리뷰하였다.
논문 총평을 하자면, 그렇게 어렵지 않은 논문이라고 할 수 있다. 다만, 몇몇 용어를 해석하는 어려움이 있었기에 추가자료와 함께 정리하도록 하였다.
Reference :: An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
1. Introduction

Self-attention 구조는 NLP(Natural Language Processing), 자연어 처리 분야에서 많이 쓰였으며, 구조적인 장점인 효율성과 확장성 덕분에 수많은 파라미터를 이용한 대용량 Corpus처리를 용이하게 하였다. 하지만 Vision 분야에서는 Transformer의 유의미한 적용이 힘들었다.
본 논문에서 또한 image를 일정 patch 구간으로 나누어 linear하게 embedding하여 Transformer의 input으로 넣는 구조를 통해 Transformer를 Vision분야에서 사용하려 해보았지만 적은 학습 데이터(21K)로는 CNN기반의 ResNet보다 적은 정확도를 보였다. 이는 CNN이 가진 inductive bias를 Transformer가 모두 표현하지 못한다는 것이 가장 큰 이유라고 생각하였다.
하지만 해당 Transformer에 매우 큰(Large-scale)데이터셋(14M~300M)을 통해 학습하자 Image Classification 문제에서 SOTA 성능을 보였으며, 데이터의 양적인 측면에서 CNN의 inductive bias자체를 Training 할 수 있었다.
Inductive bias?
Inductive bias란 어떤 모델의 특별한 구조적인 특징으로 갖는 내재적인 효과를 의미한다. 논문에서는 CNN의 Inductive bias로 translation equivariance, locality 두 가지를 제시하였다. 이해에 필요한 정도로 간단하게 서술하고 넘어가도록 하겠다.
1) Translation equivariance
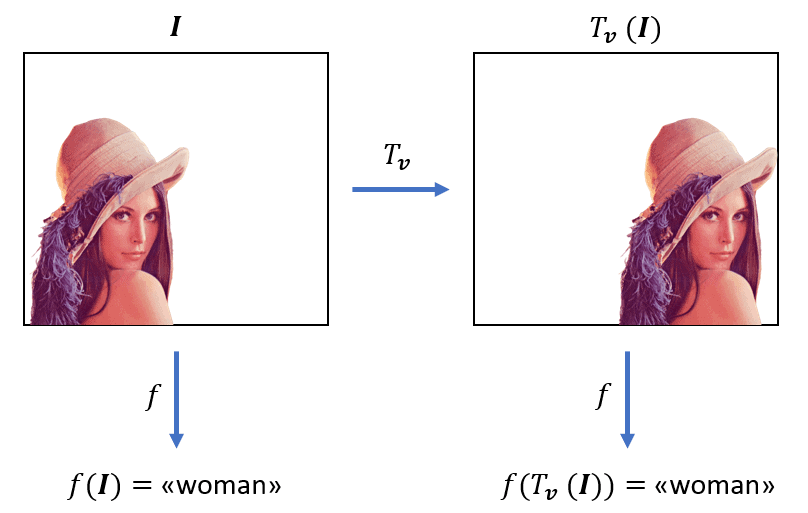
모델의 입력값이 변하면 출력값도 변한다는 특징이다. CNN은 다음 그림과 같이 이미지 내에서 입력값 위치 또는 값이 변하면 그에 따라 출력값 또한 바뀐다는 특징을 가지고 있어 Vision 문제에 적합하다는 특징을 가지고 있다.
2) Locality
Convolutional 기반 Network들의 Filter를 통해 Local한 patch 형태로 연산을 수행함에 따라 특정 영역만을 통해 충분히 Feature를 추출할 수 있다는 것을 가정하는 것이다.
위 특성을 지닌 CNN과 다르게 데이터 전체를 보고 Attention할 위치를 정하는 Transformer에서는 보다 더 많은 데이터를 필요로 한다는 것을 알 수 있다!
2. Related Work
본 논문과 관련된 다른 논문들에 대한 서술이므로 간단하게 살펴보고 넘어가도록 하겠다.
NLP의 Transformer, BERT등의 NLP 모델 논문들을 언급할 수 있으며, Transformer를 Vision분야에 접목시킨 Cordonnier et al.(2020) 논문에서는 2x2의 작은 크기의 패치를 이미지에서 추출하여 linear embedding하고 이를 Transformer의 input으로 전체 구조를 구성하였으며 본 논문과 가장 유사하다고 할 수 있다.
본 논문은 해당 논문과 거의 차이가 없다고 할 수 있지만, 대용량 데이터를 학습시킴으로써 Convolutional-based보다 더 성능을 끌어올렸으며, 고정된 패치 사이즈를 유연하게 조정함으로써 middle resolution task까지 수행할 수 있게 하였다.
3. Method
Model overview
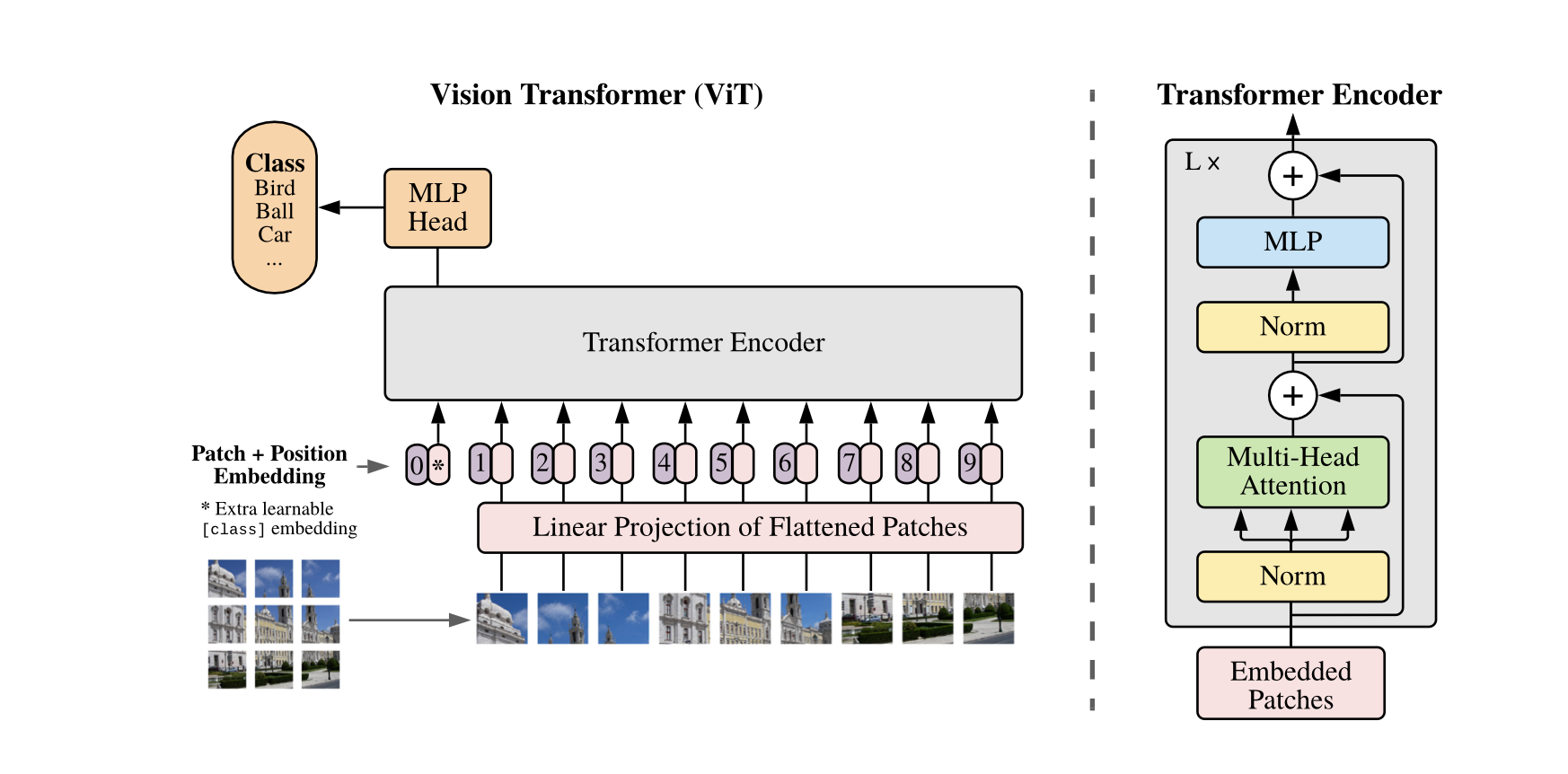
이미지를 작은 Fixed-size Patch형태로 잘개 쪼개어 Flatten하고 선형적으로 Embedding하여 Patch Embedding을 구성하였다. 이후 Patch의 위치정보인 x,y를 나타내는 Position Embedding을 추가하였다. 마지막으로 Classification Task를 수행하기 위해 각 Patch들에 Classification Token을 부여하여 Extra learnable [class] embedding으로 Embedding Vector를 구성하였다.
Vision Transformer
Vision Transformer를 구성하기 위해 진행되는 해당 내용을 다음과 같이 조금 더 보기 용이하게 정리하였다. 추후에 그림자료도 조금 첨부할 예정입니다
1. 이미지를 작은 Patch단위로 끊는다.
- ( 3 x 256 x 256 ) Input 이미지가 있다고 가정
- Patch의 width, height 모두 크기가 4라고 가정
- 즉, 해당 이미지는 ( 3 x 4 x 4 ) 크기의 패치 64x64개로 나누어진다.
2. 하나의 Patch를 하나의 Sequence라고 보고 Patch를 Flatten한다.
- ( 3 x 4 x 4 ) 크기의 Patch를 Flatten하여 48크기의 Vector를 총 64x64개 획득한다.
- Sequence 데이터로 나타낸다면 ( 4096 x 48 )으로 표현할 수 있다.
- 논문에서는 이 Sequence 데이터 크기를 N x P²C 라고 명시하였다.
3. Transformer에 입력하기 위해 Embedding 연산을 수행한다.
- D 사이즈로의 projection을 위해 ( P²C x D ) 행렬 E와 연산을 수행한다.
- 행렬곱 ( N x P²C ) * ( P²C x D ) = ( N x D ) 수행
- D = 128이라고 가정했을 때, ( 48 x 4096 ) ( 4096 128 ) = ( 48 * 128 )
- 최종적으로 이미지 하나가 아닌 배치 사이즈까지 고려한다면, (B,N,D)의 크기를 갖는 텐서 획득
- 여기까지의 Embedding을 Patch Embedding 이라고 한다.
4. Class Token 추가
- Embedding한 결과에 Class Token을 추가한다
- (N, D) => (N+1, D)
5. Positional Embedding 추가
- NLP에서의 Positional Encoding과 마찬가지로 Positional Embedding을 add 해준다.
- 이를 통해 이미지 내에서의 Position 정보를 vector에 부여한다.
- 실험적으로 1D, 2D, None, Relative Positional Encoding을 모두 사용하였을 때 1D가 가장 좋은 결과를 나타내는 것을 확인할 수 있었다.
- 그냥 ADD 연산이므로 차원은 변함없이 (N+1, D)이다.
해당 5단계로 구성된 Embedding Vector를 Transformer의 입력으로 정의하였다.
추가적으로 LayerNormalization의 경우 모든 Block 전에 수행되며 Residual Connection 구조로 설계하였음을 밝혔다.
Hybrid Architecture
Raw Image Patch 대신 CNN을 통해 얻은 Feature Map을 사용하여 input sequence를 구성한 Hybrid 형태의 구조이다. Patch Embedding 연산 시 E를 Feature Map 크기에 맞추어 Projection한다는 차이점이 있다. 나머지는 동일하며 Hybrid Architecture는 Experiments 시 성능 비교를 위해 구성하였다.
Fine-Tuning and Higher Resolution
대용량 데이터를 통해 Pre-trained된 VIT를 Downstream Task에 대해서 Fine-Tuning하였다. 이 때 Pre-trained Prediction head를 제거하고 후위에 DxK 형태의 FeedForward Layer를 구성하여 K개의 클래스를 예측할 수 있도록 하였다.
고해상도 이미지 Fine-Tuning에서는 Patch사이즈가 동일함에 따라 sequence length가 더 커지게 되었다. VIT는 Sequence Length의 확장성을 가지고는 있으나, 이 때문에 Pre-trained된 Positional Embedding값이 무의미해진다는 점을 발견하였다. 따라서 2D interpolation을 통해 pre-trained Positional Embedding값을 Original Image에 location에 맞추었다.
+ Personal Opinion
Experiment Notation
이번 논문 리뷰에서도 Experiments 부분을 생략하였다. 내용이 조금 많긴해서 고민하였는데 어렵지 않은 내용이기도 하고 논문 작성 시 보통
가정 -> 실험 -> 결론 과정을 통해 이미 결론이 파악된 가정들을 Experiment 전 부분에 언급을 하므로 위 정리글을 증명하는 내용이라 따로 정리하지 않았다.
다만 논문에서 또한 정리되어있지만 해당 내용만큼은 반드시 정리를 해놓으면 나중에 읽기 편할 것 같아 정리해보았다.
Review
VIT 논문을 읽으며 느낀 점은 Transformer 기초 지식 및 CNN등의 기본적인 이해가 필요했었던 논문이라고 생각이 들었다. 또한 VIT라는 단어가 부상할 당시 왜 대용량 데이터의 중요성을 강조했었는지 조금 알게 되었다. (VIT만이 원인이라고 할 수는 없겠지만 원인제공요소 중 하나일 것임은 분명하다..)
Transformer라는 기존의 Convolutional한 구조에서 벗어나 새로운 구조에 이미지를 적용시키는 방법이 흥미로웠다. 원리가 자세히 적혀있지 않았으나 김진솔님 블로그를 통해 논문 내용에 Transformer 기본 개념까지 더불어 정리 할 수 있었다(감사합니다!). 본 논문에서는 16사이즈의 패치를 사용하였기 때문에 김진솔님의 블로그가 더 논문에 가까운 예시를 들었다고 할 수 있다. 하지만 256x256 image를 16x16(Resolution)의 패치로 나누게 되면 16x16(개수)의 패치들이 생성되기 때문에 해당 숫자가 헷갈릴 우려가 있어서 가독성을 위해 숫자를 바꾸어 정리를 해보았다.
