논문 또는 논문 관련 블로그를 본 내용을 정리하는 글을 남기고자 한다.
해당 블로그는 Long Tailed Distribution에 대해 검색하는 도중 정리된 글이 있어 다시 리포스트하여 정리해보았다.
[ICML2022, LG Research AI, LTD Learning]
What is Long Tailed Distribution Learning?
Long Tailed Distribution(LTD)
"데이터 분포가 치우쳐진 경향을 보이는 데이터 집합"
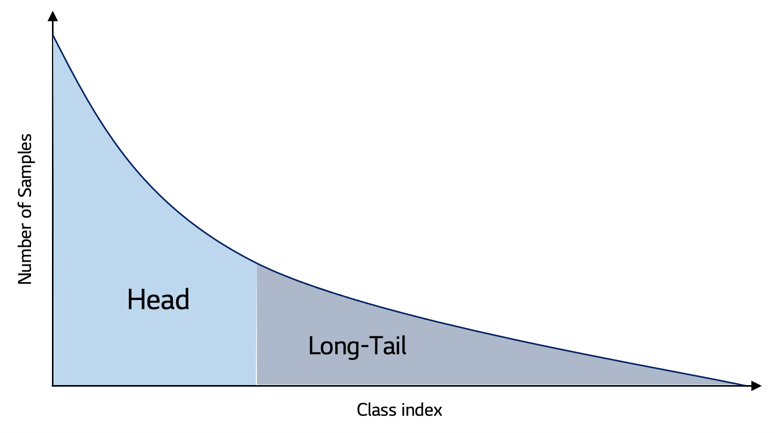
위 그림과 같이 데이터 분포가 치우쳐진 데이터 집합(분포)를 Long Tailed Distribution(LTD)이라고 표현한다.
LTD는 정말 많은 데이터에서 포착되는 분포라고 할 수 있으며, 경험상 실무 데이터는 이러한 분포를 띄고 있을 가능성 또한 매우 높다고 할 수 있다.
- Head Class : Sample수가 지배적으로 많은 Class를 Head Class라고 한다
- Tail Class : Sample수가 적은 Class(보통 Target Class)를 Tail Class라고 한다.
LTD의 문제점은 모델이 각 Class의 Representation을 충분히 학습할 수 있을 정도의 양이 충분하지 않으며 이로 인해 Head Class의 경우 높은 성능을, Tail Class의 경우 낮은 성능을 보이는 것이다.
보통 지배적으로 많은 수의 Head Class Sample로 인해 이에 편향되게 학습이 되며 Tail Class의 성능이 낮아진다.
LTD를 개선하기 위한 방법
이를 개선하기 위해 다양한 방법론이 제시되었다.
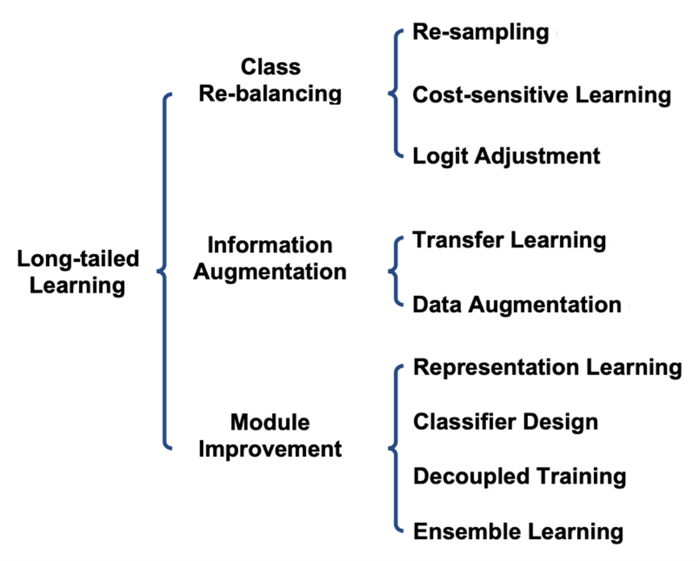
Re-sampling
- Under-Sampling
Under-Sampling은 Head Class Sample를 줄여 전체 데이터 분포를 고르게 하는 Sampling 방법이라고 할 수 있다.
하지만, Under-Sampling의 큰 단점은 Randomize하게 Head Class Sample을 제거하는 과정 중 중요한 정보를 삭제하게 된다면 학습에 치명적인 문제로 작용할 수 있다는 점이다.
따라서 이를 보완하게 위해 KNN Classifier를 사용하여 Class Distribution을 잘 대표하는 유의미한 Sample을 추출하는 기법을 사용하기도 한다. - Over-Sampling
Over-Sampling은 Under-Sampling과 반대로 Tail Class Sample을 늘려 전체 데이터 분포를 고르게하는 Sampling 방법이다.
Over-Sampling 역시 문제점이 있다면, 단순 복제 방법은 Tail-Class의 적은 분포로 인해 Feature추출의 한계가 생겨 이에 대한 Overfitting이 우려되는 점이다.
이를 보완하기 위해 Head Class Sample 사이를 interpolation(Head Class Distribution 사이의 값을 추정)을 이용해 생성해 내는 Synthetic Minority Over-sampling Technique(SMOTE)방법이 제시되었다.
+ GAN을 이용한 방법들 또한 제시되었다.
Cost-Sensitive Learning
- Cost-Sensitive Learning
Cost-Sensitive Learning은 한 마디로 학습 단계에서 Head Class와 Tail Class에 다른 Weight를 주어 학습을 편향되지 않게 Learning하는 방법이라 할 수 있다.
Class별로 다른 Loss를 취하는데, 이 때 Head-Class에는 Penalty, Tail Class에는 Weight를 주어 모델의 일반화 성능을 높이게 된다.
Transfer-Learning
-
LTD에서의 Transfer Learning
Head-Class의 정보를 Tail-Class로 전이하여 모델의 성능을 끌어올리는 방법(Head-to-Tail knowledge Transfer-Learning)이다. -
Feature Transfer Learning(FTL)은 Tail-Class의 variance가 Head-Class보다 작아 Head쪽으로 Decision Boundary가 편향되는 것을 막기 위해 Head Variance를 반영하여 Tail Class Augmentation을 진행, Head와 Tail의 Variance의 크기를 어느정도 맞추게 된다.
-
Online Feature Augmentation(OFA)는 Class Activation Map에 기반하여 Class-Specific Feature와 Class-Agnostic Feature를 추출한다. 그 다음, Tail-Class Specific Feature와 Head-Class Agnostic Feature에 기반하여 tail-class sample을 증강한다.
-
Rare Class Sample Generator(RSG)는 각 Class별 feature center를 추정한 후, Head-Class Sample Feature와 가장 가까운 intra-class feature center간 Feature Displacement에 기반하여 Tail-Class Feature를 보강한다.
(이를 순차적으로 진행하는 것이며, Transfer Learning에 관해서는 한번 더 정리해보도록 하자.)
Representitive Learning(Constrastive Learning)
- K-postive Constrastive Learning(KCL)은 Balanced Feature 공간을 형성할 수 있는 K-postive Constrastive Loss를 제안, LTD문제를 완화하였다.
- Parametric Constrastive Learning(PaCo)는 Class Center들을 모델의 가중치로 놓고, parametric 학습이 가능한 새로운 Class center를 추가하여 Supervised Constrastive Learning(SCL)을 개선하였다.
- Distributional Robustness loss for Long-tail Learning(DRO-LT)는 Prototypical Learning에 기반한 Distribution Robust 최적화를 통해 모델이 Data distribution shift에 더욱 Robust하도록 개선하였다.
본문에서는 Decoupled Learning에 대한 설명 또한 존재하지만 중요하지 않기 때문에 생략합니다.
Partial and Asymmetric Contrastive Learning for Out-of-Distribution Detection in Long-tailed Recognition(PASCL)
본문에서는 앞서 설명한 LTD 유형의 데이터셋을 가지는 OOD(Out-of-Detection) Task에서의 새로운 방법론을 소개하고 있다.
OOD Sample과 TID(Tail-class In-Distribution)Sample의 예측 정확도에 더욱 집중하는 PASCL을 소개하였다.
SCL 및 기존의 문제점은 Head-Class와는 이미 OOD Sample이 구분이 되었지만, Tail-Class와는 잘 구분이 되지 않다는 점이다.
이는 "OOD Detection와 LTD recognition간의 목적이 상충한다는 점"에서 기인한다고 서술하였다.
OOD Detection은 Rare한 Sample에 대해서 모델이 Under-Confident한 결과를 내도록 하는 것 이며,
LTD recognition은 이와 반대로 Rare한 Sample에 대해서 모델이 높은 Prediction Confident를 낼 수 있도록 하는 문제이다.
따라서 본문에서는 다음과 같은 방법을 제시한다.
- Partial and Asymmetric Supervised Contrastive Learning (PASCL)을 통해 이 두 그룹(OOD & TID)간의 차이를 구분할 수 있는 boundary를 찾음
- Auxiliary Branch Fine-Tuning (ABF)을 통해 모델을 2개의 branch로 disentagle시켜 각각의 목적에 맞게 2번에 걸쳐 학습함.
Partial and Asymmetric Supervised Contrastive Learning (PASCL)
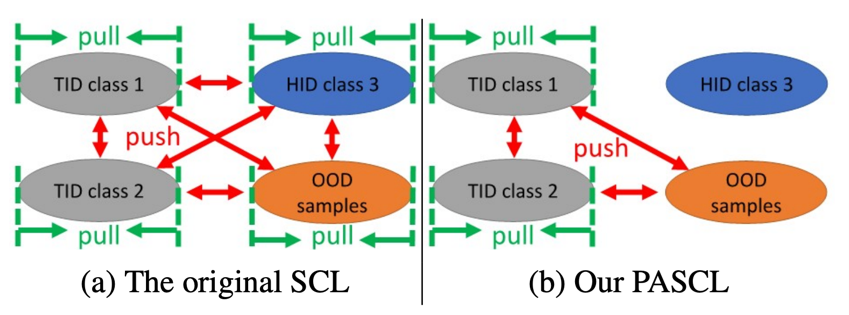
- Partiality
HID Sample과 OOD Sample은 결국 잘 분리되었다고 할 수 있기 때문에 우리가 집중해야할 것은 TID라고 할 수 있다.
따라서 OOD Sample과 TID Sample에만 부분적으로 Constrastive Learning을 적용하여 다음과 같이 진행한다.
-
같은 Class TID Sample들과 OOD Sample들은 Feature Space상에서 서로 가까워지게 Pull 땡겨!
-
TID Sample과 OOD Sample사이는 Feature Space상에서 멀어지게 Push 밀어!
(위 내용을 토대로 일반적인 SCL에 대해 추측해보았을 때, 같은 Class들 끼리 서로 pull, 다른 class들끼리는 push하는 기법을 진행함으로써 Class Center와 각 Class boundary를 명확하게 하는 기법 같아 보인다.)
- Asymmetry
In-Distribution Sample과 달리, 사실 OOD Sample은 말 그대로 "해당 분포에 존재하지 않는 데이터" 즉, 다양한 형태로 이루어져 있다. 따라서 OOD Sample이 Feature Space에서 서로 가까운 공간에 위치할 필요는 없으므로 Pull 해주지 않는다.
Auxiliary Branch Fine-Tuning (ABF)
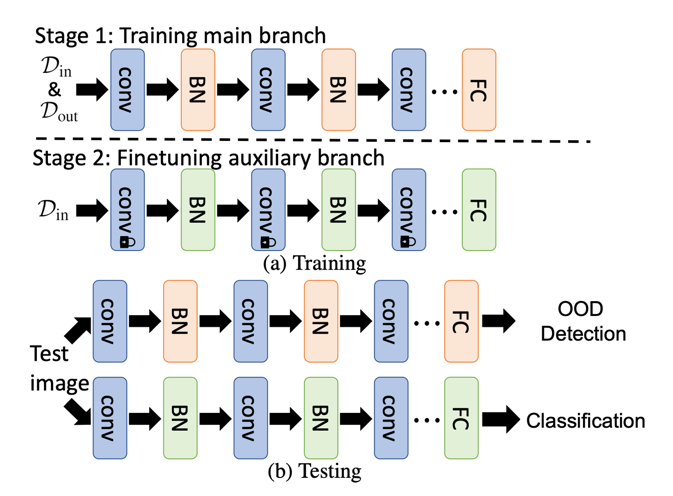
- In-distribution Sample과 OOD-sample 모두 mixture-BN을 사용하여 loss를 최소화시키도록 학습한다.
- In-Distribution Sample만을 사용하여 Main-branch에서 학습된 모델의 Auxiliary BN Layer와 Classification layer를 Fine-Tuning한다. 이때, 다른 Conv Layer는 고정시키고 Logit-Adjustment(LA) cross-entropy loss를 사용하여 모델을 학습한다.
이렇게 학습된 모델을 Inference시, 역시 2번의 branch를 거쳐 학습하게 된다.
- 새로운 Sample은 먼저 OOD Detection을 수행하는 Main branch로 들어가서 OOD vs In-Distribution 문제를 수행한다.
- OOD라고 판정될 경우 다음 branch로 넘어가지 않으며, 아닐 경우 Auxiliary branch를 통해 in-distribution classification을 수행하게 된다.
Conclusion 및 Discussion은 생략하였습니다. 이 내용은 참조한 본문을 통해 확인해주시길 바랍니다.
개인적인 견해
완전한 논문을 읽고 정리한 것이 아니라 정리된 블로그(LG AI Research)를 다시 한번 정리하는 글이며, 이에 따라 그대로 따라 작성한 문장이 몇 있다.
본문 자체도 보기 편하게 작성되어있지만, 조금 더 편리한 문장과 방법을 통해 정리를 하려고 하였으며, 본문에는 나와있지 않은 SCL에 대한 부가 설명 또한 첨부하였다.
블로그를 정리하는 것이 큰 의미가 없다고 생각하였으나.. 이렇게 LTD라던지 관련 분야가 아닌 글의 속독을 위해서는 정리된 글이 이렇게나 도움이 될 줄은 몰랐다. 논문 통째로 읽기 위해서는 영어가 필수이기 때문에 나날이 영어의 중요성을 인지하고 있는 요즘이다...
추가적으로 SCL을 추측해서 정리하기는 하였으나, 이에 관한 내용도 한 번 정리해보면 좋을 것 같다. Long-Tail Distribution은 앞서 언급했듯이 실무 데이터에서 정말 잘 나타내는 문제였기 때문에 여러 방법론을 숙지하는 것은 중요하다고 생각한다.
사실 이 논문을 읽으려다가 한 번 정리해보자는 마음으로 작성한 글이며,
- Long Tail Distribution
- PASCL
- OOD(Out-of-Distribution) Detection
과 같은 개념을 다질 수 있었다.
PASCL SCL 논문정리 LG_AI_RESEARCH LTD OOD 데이터_편향 Overfitting
