지난 포스팅에서 빈도 기반으로 단어를 벡터화하는 것에 대해 정리했습니다. 이번에는 분포 기반의 단어 표현(벡터화)에 대해 정리하겠습니다.
분포 가설
등장 횟수 기반의 표현은 간편하지만 몇 가지 한계가 있습니다. 대표적으로 희소 문제가 있는데요. 중요한 단어이더라도 자주 등장하지 않는 단어는 학습에서 가중치를 부여받는데 한계가 있습니다. 분포 기반의 단어 표현은 이와 같은 등장 횟수 기반의 표현의 한계를 보완하기 위해 등장했습니다.
분포 기반의 단어 표현은 분포 가설을 근거로 합니다. 분포 가설이란 비슷한 의미를 지닌 단어는 주변 단어 분포도 비슷하다는 가설입니다.
- He is a good guy.
- He is a cool guy.
위 문장에서 good과 cool은 해당 단어 주변에 분포한 단어가 유사하기 때문에 비슷한 의미를 지닐 것이라고 추측할 수 있습니다. 그리고 분포 기반의 표현은 이 분포 가설에 기반하여 주변 단어의 분포를 기준으로 단어의 벡터 표현을 결정합니다. 이를 분산 표현(Distributed representation)이라고 합니다.
1) One-hot encoding
본격적으로 분산 표현에 대해 알아보기 전에 익숙한 One-hot encoding을 잠시 언급하겠습니다. 분산 표현의 장점을 알기 위해 One-hot encoding과 비교해보겠습니다.
One-hot encoding은 범주형 변수를 벡터로 나타내는 방법 중 하나입니다. 단어도 범주형 변수라고 본다면, One-hot encoding을 적용할 수 있습니다.
He is a good guy
위의 문장을 One-hot encoding으로 표현하면 다음과 같습니다.
He : [1 0 0 0 0]
is : [0 1 0 0 0]
a : [0 0 1 0 0]
good : [0 0 0 1 0]
man : [0 0 0 0 1]
단어의 길이만큼 영벡터를 만든 뒤 해당하는 단어에 1을 부여하면 됩니다. 간편한 방법이지만 치명적인 단점이 있습니다. 바로, 단어 간에 유사도를 구할 수 없다는 점입니다. 단어 간에 유사도를 구할 때에는 코사인 유사도가 사용되는데요.
코사인 유사도는 두 벡터를 내적한 값을 분자로 사용합니다. 하지만, 원-핫 인코딩을 적용한 서로 다른 두 벡터의 내적은 항상 0입니다. 따라서 어떤 두 단어르 ㄹ골라서 코사인 유사도를 구하더라도 그 값은 항상 0이 됩니다. 이렇게 두 단어 사이의 관계를 전혀 알 수 없다면, 모델의 유연성이 매우 떨어지게 됩니다. 새로운 문장이 들어왔을 때 그 의미를 파악하기 어려워지는 것입니다.
또한 단어의 갯수가 늘어날 수록, 벡터를 저장하기 위해 필요한 공간이 계속 늘어나야 한다는 단점도 있습니다. One-hot encoding은 단어가 3만개라면 한 행의 길이가 3만이 됩니다. 그리고 그 중에 해당하는 단어 하나에만 '1'이 표현됩니다. 메모리 낭비입니다.
2) 임베딩(Embedding)
One-hot encoding의 단점을 해결하기 위해 임베딩이라는 방법이 사용됩니다. 단어를 고정 길이의 벡터, 즉 차원이 일정한 벡터로 나타내기 때문에 '임베딩'이라는 이름이 붙었습니다. 예를 들어 임베딩을 거친 단어는 다음과 같이 실수 행렬로 표현할 수 있습니다.
[0.02313, 0.12334, 0.32424, 0.3244]
위와 같이 벡터 내의 각 요소가 연속적인 값을 가집니다. 비슷한 실수를 지닌 벡터는 비슷한 벡터 공간 안에 위치하게 되면서 단어 간의 유사성을 계산할 수 있게 됩니다. 그리고 Word2Vec은 가장 널리 알려진 임베딩 방법 중 하나입니다. 어떻게 위와 같은 벡터가 만들어지 Word2Vec을 설명하며 알아보겠습니다.
3) Word2Vec
Word2Vec은 주변 단어를 타겟으로 하여 중심 단어를 예측하는지, 혹은 중심 단어를 타겟으로 하여 주변 단어를 예측하는지에 따라 CBow와 Skip-gram으로 나뉩니다.
Skip-gram을 예로 들자면, 'He is a good man'이라는 임베딩하기 위해 모델은 good이라는 중심 문장을 중심으로 주변 단어를 학습합니다. [good]의 학습이 끝나면 다음은 [good]을 마스킹처리하고 다음 단어가 중심 단어가 됩니다.
CBow는 Skip-gram과 반대의 메커니즘으로 움직입니다. Word2Vec 모델의 구조를 Skip-gram을 중심으로 좀 더 자세히 살펴보겠습니다.
[--][--] [--][good] [--]
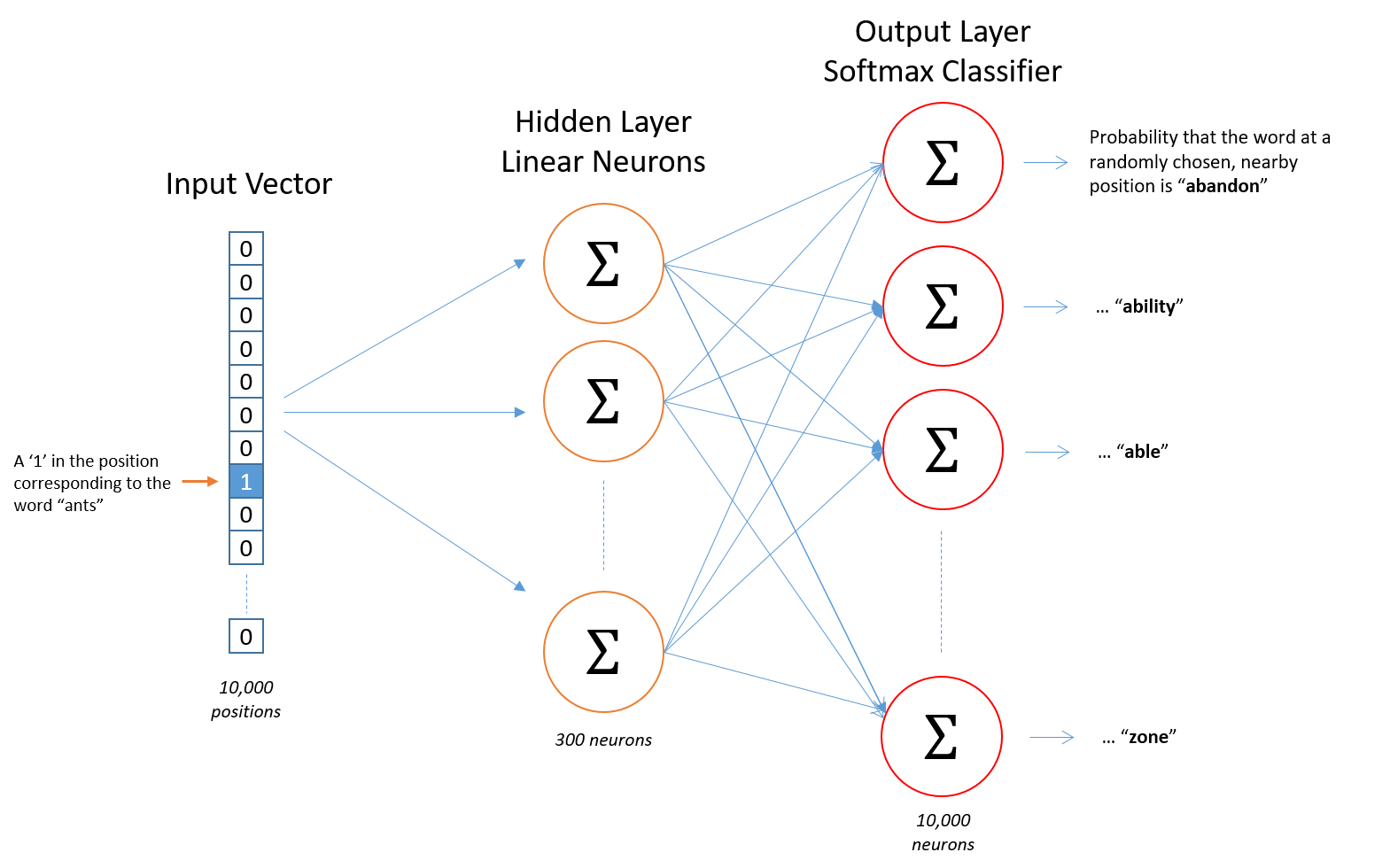
위 이미지는 Skip-gram을 도식화한 이미지입니다. 가장 왼쪽부터 입력층입니다. 순서대로 보자면,
- Word2Vec의 입력은 One-hot encoding된 단어의 벡터입니다. 인코딩된 벡터가 은닉층으로 흘러들어 갑니다.
- 은닉층의 가중치 행렬과 입력층의 벡터가 서로 곱해집니다.
- 이때 원-핫 인코딩의 특성 때문에 가중치 행렬의 특정 부분이 복사되는 형태로 결과가 출력됩니다.
- [1 0 0 0]의 원-핫 인코딩 벡터는 가중치 행렬의 첫 번째 행을 그대로 복사합니다. 이를 룩업 테이블이라고도 부릅니다. 이렇게 복사된 행이 입력층에서 입력된 단어의 임베딩 벡터가 됩니다.
- 임베딩 벡터는 출력층에서 소프트맥스 함수를 거쳐서 0~1 사이의 가능성으로 표현됩니다. 1에 가까울 수록 Skip-gram의 주변 단어에 해당합니다.
- 역전파를 거쳐 가중치 행렬이 조정되면서 임베딩 벡터는 단어 간의 의미적, 문법적 관계를 보다 잘 나타내게 됩니다.
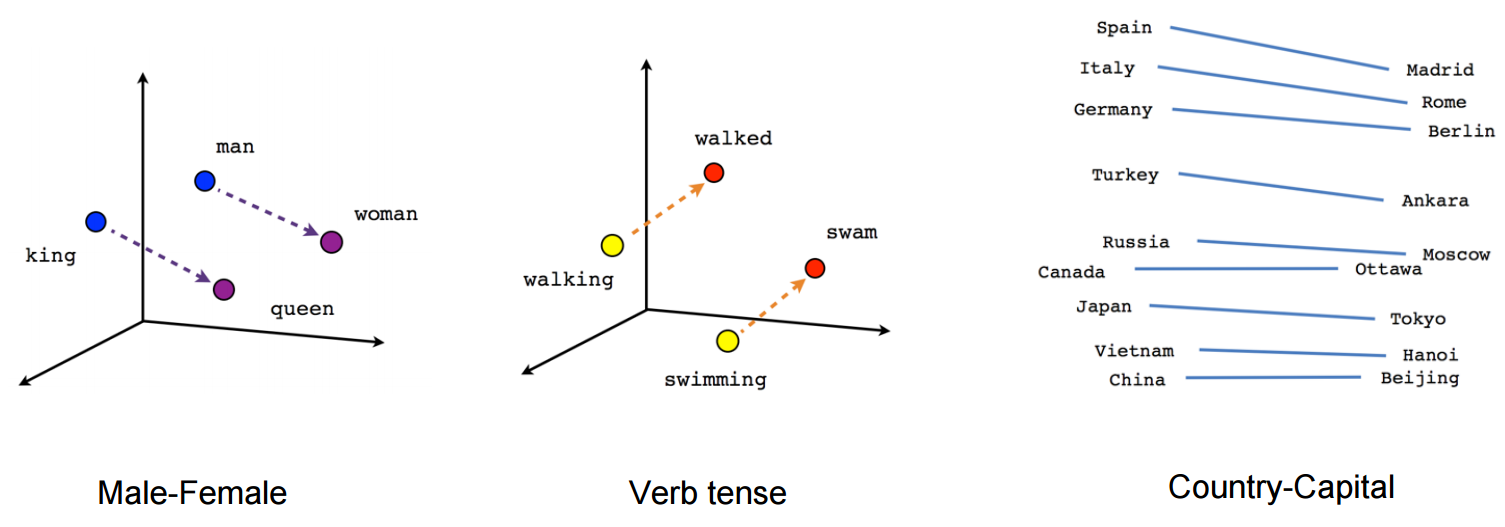
아래 이미지는 임베딩한 벡터를 시각화한 이미지입니다. man - woman 사이의 의미적 관계와 잘 표현하고 있으며, walking - walked, swimming - swam 사이의 문법적인 관계도 잘 표현하고 있습니다. 학습 데이터에 따라 나라-수도 간의 관계도 잘 나타낼 수 있습니다.