
이전 포스팅까지 모델이 자연어를 이해하기 위해 전처리하는 방법에 대해 다뤘습니다. 이제 전처리 과정을 거쳐 벡터화된 자연어를 처리하기 위한 신경망에 대해 정리하겠습니다.
택시를 타다
용돈을 타다
자연어는 연속형 데이터의 일종입니다. 위의 예시처럼 앞의 단어에 따라 뒤의 단어의 의미가 변합니다. 같은 '타다'이지만 앞에 오는 단어에 따라 '타다'의 의미가 달라집니다. 컴퓨터가 어떻게 이걸 이해할 수 있을까요?
순환 신경망 모델(RNN)
위와 같은 연속형 데이터를 처리하는데 특화되어 있는 모델이 바로 순환 신경망 모델입니다. 순환 신경망 모델은 단어를 순서대로 하나씩 모델에 input 시킵니다. 자연스럽게 순서 정보가 생기게 됩니다. '택시'라는 단어가 input되면 '를'이 output으로 나오고, 다시 '를'이 'input'으로 들어간다음 '타다'가 'out'으로 나옵니다. 최종적으로 input된 문장과 output된 문장이 같지만, 이건 label을 무엇으로 두고, 출력 갯수를 몇 개로 두는지에 따라 조절할 수 있는 문제입니다.
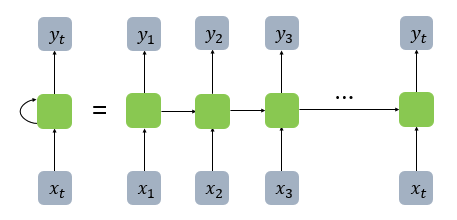
앞서 설명한 RNN의 구조입니다. 활성화 함수를 지난 값들이 출력층 방향으로만 향했던 피드 포워드 신경망과는 다른 구조입니다. 순환 신경망 모델은 피드 포워드 모델과 달리 은닉층의 노트에서 활성화 함수를 통해 나온 결과값을 다시 다음 계산의 입력으로 보내는 특징이 있습니다.
- t-1 시점의 계산이 다시 t 시점의 입력값이 되어 연산을 수행하는 노드를 셀이라고 부릅니다. 위 이미지에서 초록색 사각형이 메모리 셀입니다.
- 셀이 출력층 방향 또는 다음 시점인 t+1의 자신에게 보내는 값을 은닉 상태라고 부릅니다.
- t 시점의 셀은 t-1 시점의 셀이 보낸 은닉 상태값을 t 시점의 은닉 상태 계산을 위한 입력값으로 사용합니다.
이렇게 시점에 따라 새로운 단어가 input되고, 새로운 단어가 셀에서 이전 단어의 은닉 상태와 연산되는 과정이 반복됩니다. 이런 구조 때문에 RNN은 이론상으로 입력되는 시퀀스, 즉 문장의 길이에 제한이 없다는 장점이 있습니다. 또한 시퀀스 내의 단어가 순서대로 입력되기 때문에 순서 정보가 중요한 자연어 처리에 유리한 모델입니다.
또한, RNN은 input의 갯수와 output의 갯수에 따라 다용한 용도로 사용할 수 있다는 장점이 있습니다.
- 일 대 다 : 하나의 이미지(input)에서 사진 제목을 출력하는 이미지 캡셔닝 작업에 사용할 수 있습니다. 사진 제목은 단어들의 나열(output)이므로 단어 시퀀스 출력으로 볼 수 있습니다.
- 다 대 일 : 이메일의 내용(input)을 보고 해당 메일이 스팸인지 아닌지 분류(output)하는 모델로도 만들 수 있습니다.
- 다 대 다 : 사용자가 문장을 입력(input)하면 대답 문장을 출력(output)하는 챗봇으로도 활용할 수 있습니다. 또한 입력 문장으로부터 번역된 문장을 출력하는 번역기 등에도 사용합니다.
순환 신경망의 단점
1) 장기의존성 문제
모든 모델이 그렇듯이 순환 신경망에도 단점은 있습니다. 먼저, 장기의존성 문제가 있습니다. RNN은 하나의 임베딩 벡터에 연산 결과를 계속 덮어 쓰는 방식으로 다음 셀에 은닉 상태를 넘깁니다. 그래서 앞 부분의 입력값일 수록 학습 과정에서 정보가 소실될 위험이 있습니다. 역전파 과정을 떠올려보면 됩니다.
역전파 과정에서 가중치 조정이 일어날 때 뒤에서부터 손실함수의 기울기가 조금씩 감소하기 때문에 앞 부분의 노드에 도착했을 때 이미 기울기가 0에 가까워져 있는 현상이 일어납니다. 이 현상을 기울기 소실이라 부르고, RNN의 장기의존성 문제라고도 합니다.
2) 병렬화 불가능
또 다른 단점은 시퀀스를 병렬처리할 수 없다는 점입니다. 앞서 봤듯이 RNN은 모든 단어가 순차적으로 입력되는 모델입니다. 이는 연속형 데이터의 순서 정보를 처리할 수 있다는 장점이 되기도 하지만, GPU를 활용한 병렬 연산을 할 수 없다는 단점이 되기도 합니다. 실제로 RNN을 사용하면 학습 속도가 다른 모델에 비해 현저히 느린 것을 보실 수 있습니다.
위와 같은 문제를 해결하기 위해 LSTM, GRU, Attention과 같은 모델을 고안하게 됩니다. 이 모델에 대해서는 다음 포스팅에서 다루도록 하겠습니다.
