
1. Logistic Regression
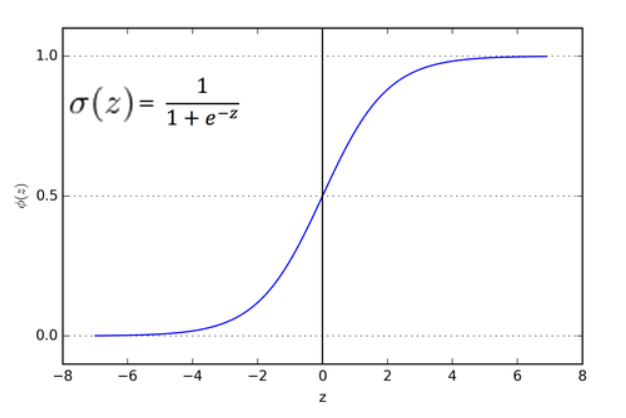
- 로지스틱 회귀는 분류 문제에 사용하는 모델입니다.
- 특성변수를 로지스틱 함수 형태로 표현하기 때문에 관측치가 특정 클래스에 속할 확률값으로 계산할 수 있습니다.
- 분류 문제에서는 확률값을 사용하여 타겟을 분류합니다. 이때 확률값이 정해진 기준값보다 크면 1, 아니면 0으로 예측합니다.
- 회귀모델이 그렇듯, 과소적합이 특징이지만 데이터를 이해하기 위해 가장 먼저 사용하는 모델이 되기도 합니다.
- 회귀모델의 특성 상 다른 블랙박스 모델에 비해 특성과 타겟 간의 관계를 해석하기 쉽기 때문에 본격적인 모델 구축 전에 로지스틱 모델을 데이터를 파악합니다.
2. Logit transformation
- 로지스틱 회귀는 특성 변수를 로지스틱 함수 형태로 표한하기 때문에 선형회귀처럼 직관적으로 해석하기 어렵습니다.
- 이때 Odds라는 개념을 활용합니다.Odds는 실패확률에 대한 성공확률의 비율입니다. Odds가 4라면 성공확률이 실패확률의 4배라는 의미입니다.
- Odds에 로그변환을 하면 로지스틱을 선형형태로 바꿀 수 있습니다. 특성 X의 증가에 따라 로그변환한 Odds가 얼마나 증가(or 감소)했는지 해석할 수 있습니다.
- 모델에 넣었을 때의 스케일로 해석하고 싶다면 로그의 역함수를 취해 계수를 변환하여 해석합니다(exp(계수) = p). 특성이 1단위 증가할 때 성공확률이 P배 증가한다고 해석할 수 있습니다.
3. Modeling
- 선형회귀와 마찬가지로 범주형 변수를 인식하지 못하기 때문에 인코딩을 해야합니다. Feature의 class에 따라 분기하는 tree 모델과 달리 Logistic 모델은 특성을 로지스틱 함수로 처리하여 표현하기 때문에 명목형 변수를 순서형 변수처럼 처리하는 것에 주의해야합니다. 주로 OneHotEncoder를 사용하며, High Cardinality를 해결하기 위해 baseN encoding 등을 사용한다.
- 사용하는 변수 간에 스케일이 다를 경우 숫자가 큰 변수의 영향력이 과대평가될 가능성이 높다. 이 문제를 해결하기 위해 StandardScaler를 사용하여 Feature를 정규화한다.
- 데이터가 크지 않은 경우 train / val / test set으로 분리(3-way holdout method)하기 어렵다. 이때 LogisticRegressionCV를 사용하면, train set를 cross validation할 수 있다.

-