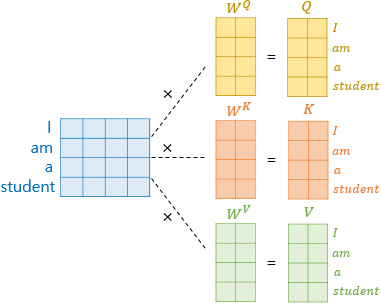
transformer에서 score 함수는 일반적인 내적이 아니라 scaled dot product를 취한다. score(q,k)=q⋅k/dk 이고, dk=dmodel/num_heads
논문에서는 512/8=64=8
Attention(Q,K,V)=softmax(dkQKT)V
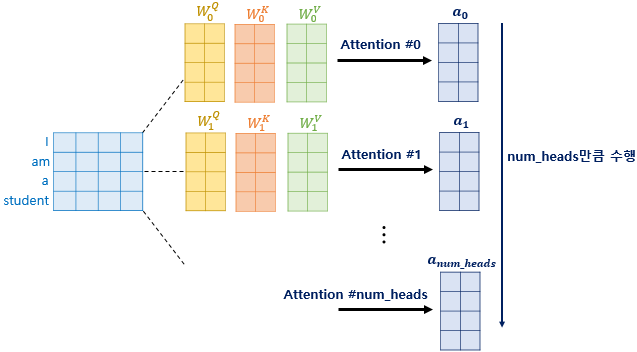
Multi-head Attention
: dmodel의 차원을 num_heads개로 나누어 dmodel/num_heads의 차원을 가지는 Q, K, V에 대해서 num_heads개의 병렬 어텐션을 수행
결과로 나온 각각의 어텐션 값 행렬을 어텐션 헤드라고 부르고, 이때 가중치 행렬 WQ,WK,WV의 값은 8개의 어텐션 헤드마다 전부 다르다.
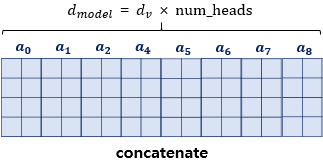
병렬 어텐션을 모두 수행하였다면 모든 어텐션 헤드를 concatenate한다. 모두 연결된 어텐션 헤드 행렬의 크기는 (seq_len,dmodel)이 된다.
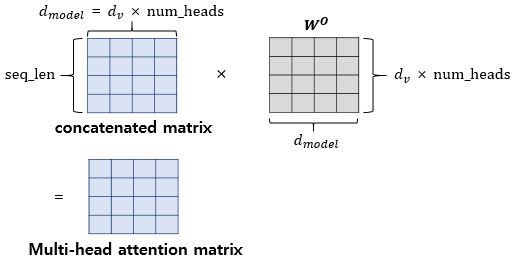
여기에 다시 또다른 가중치 행렬 W0을 곱한 결과 행렬이 멀티-헤드 어텐션의 최종 결과물이 된다.
최종 결과물 행렬의 크기는 (seq_len,dmodel)이다.
즉 인코더의 첫번째 서브층인 멀티-헤드 어텐션 단계를 끝마쳤을 때 인코더의 입력으로 들어왔던 행렬의 크기는 (seq_len,dmodel)로 계속 유지가 된다.
패딩 마스크(Padding mask)
: 입력 문장에 <PAD> 토큰이 있을 경우 마스킹을 해서 어텐션에서 제외를 해 준다.
마스킹을 하는 방법은 어텐션 스코어 행렬의 마스킹 위치에 매우 작은 음수값을 넣어 주는 것이다.
이렇게 하면 어텐션 스코어 행렬이 소프트맥스 함수를 지난 후에는 해당 위치의 값은 0이 되어 단어 간 유사도를 구하는 일에 <PAD> 토큰이 반영되지 않게 된다.
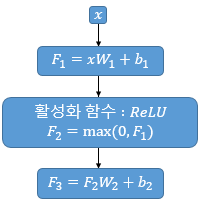
포지션-와이즈 피드포워드 신경망 (Position-wise FFNN) FFNN(x)=MAX(0,xW1+b1)W2+b2
매개변수 W1,b1,W2,b2는 하나의 인코더 층 내에서는 다른 문장, 다른 단어들마다 정확하게 동일하게 사용된다. 하지만 인코더 층마다는 다른 값을 가진다.