https://wikidocs.net/22893
dot-product attention(Luong attention)을 기준으로 설명함
-
Attention Score
: 디코더의 현재 시점 t의 hidden state 를 전치(transpose)한 와 인코더의 i번째 hidden state 를 내적한 값
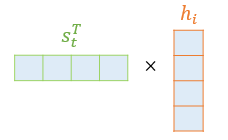
어텐션 스코어 함수를 정의해보면 다음과 같다.
-
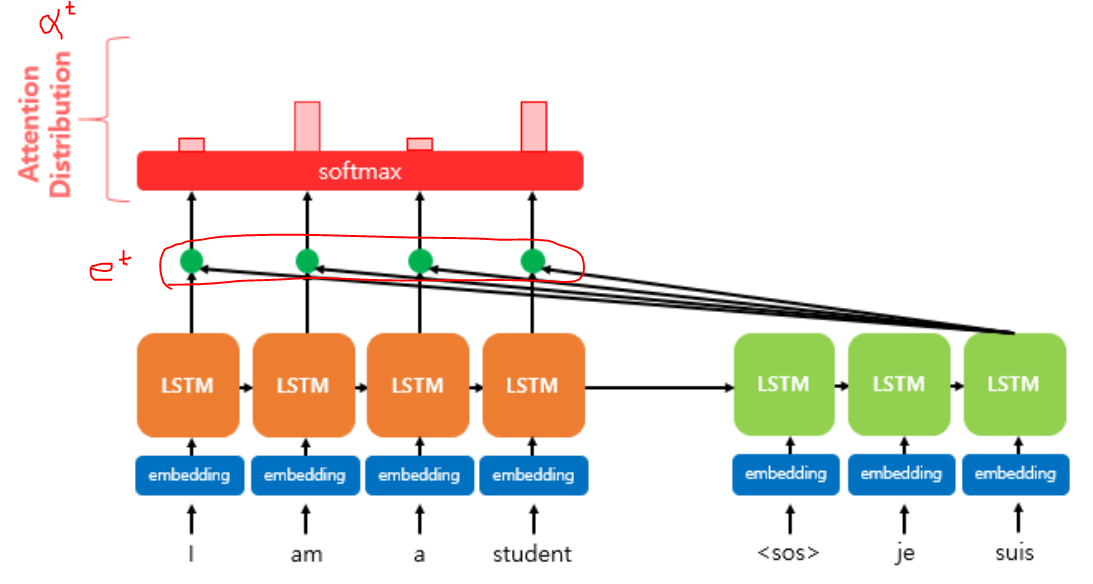
Attention Distribution(=Attention Vector)과 Attention Weight:
: 와 인코더의 모든 hidden state의 attention score의 모음값을 라고 정의했을 때, 의 수식은 다음과 같다.
이런 에 소프트맥수 함수를 적용하여, 모든 값을 합하면 1이 되는 확률 분포를 얻어내면 이를 어텐션 분포(attention distribution)라고 하며, 각각의 값은 attention weight라고 한다. attention distribution은 종종 attention vector라고도 불린다.
디코더의 시점 t에서 attention weight의 모음값인 어텐션 분포를 라고 할 때, 를 식으로 정의하면 다음과 같다.
-
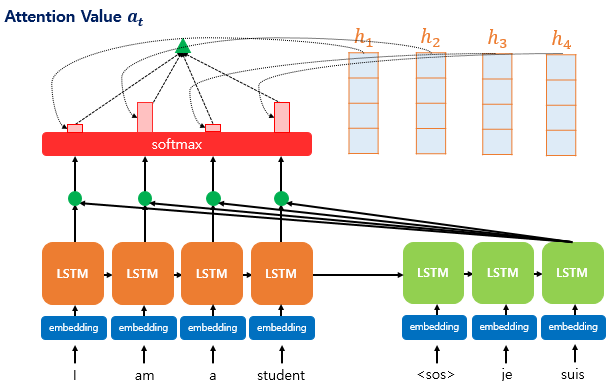
Attention Value
: 어텐션의 최종 결과값 attention value를 얻기 위해서 각 인코더의 hidden state와 attention weight들을 곱하고, 최종적으로 모두 더한다. 요약하면 가중합(Weighted Sum)을 진행한다.
attention value 는 디코더의 현재 시점 t에 대한 단일 vector가 된다. 이를 디코더의 t 시점의 hidden state와 concat을 해준다.
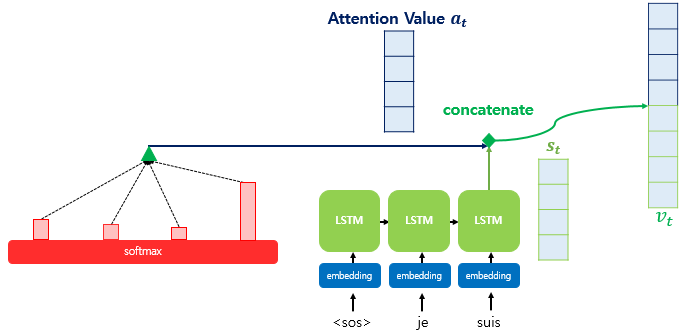
이후
를 진행한다. -
Query, Key, Value
: 디코더의 time t의 hidden state 가 Query가 되고
이와 연산되어 attention score를 구하는 재료가 되는 인코더의 i번째 hidden state 가 Key,
가중합이 진행되는 인코더의 i번째 hidden state 가 Value가 된다.
