1. 데이터 다루기, Classifier
기초 지식
- 특성 : 데이터를 표현하는 하나의 성질
- 훈련 : 머신러닝 알고리즘이 데이터에서 규칙을 찾는 과정 (사이킷런에서 fit() method의 역할)
- 정확도 : 정확히 맞친 개수 / 전체 데이터 개수
- 모델 : 알고리즘이 구현된 객체 혹은 알고리즘 자체
scikit-learn
- KNeighborsClassifier() : nneighbors매개변수로 이웃의 개수를 지정, k-최근접 이웃 분류(가까운 이웃 참고 정답 예측) 모델을 만드는 사이킷런 클래스. n_jobs를 -1로 설정 시 모든 CPU 코어를 사용
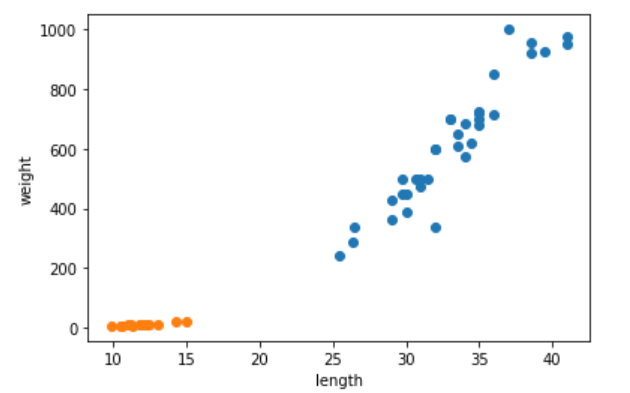
위와 같은 산점도에서 특정위치의 생선이 무엇일지 주변 값을 이용하여 예측_- fit() : 모델을 훈련
- predict() : 모델을 훈련하고 예측
- score() : 성능 측정
2. 데이터 전처리
개념들
- 지도학습 : 입력과 타깃을 전달하여 모델을 훈련한 다음 새로운 데이터를 예측하는 데 활용
- 비지도 학습 : 입력 데이터에서 어떤 특징을 찾는 데 주로 활용
- 데이터 전처리(data preprocessing) : 머신러닝 모델에 훈련 데이터를 주입 전 가공하는 단계, 알고리즘들은 샘플 간의 거리에 영향을 많이 받으므로 특성값을 일정한 기준으로 맞춰야함.
- 샘플링 편향(sampling bias) : 훈련 세트와 테스트 세트에 샘플이 골고루 섞여 있지 않은 경우(도미와 빙어가 골고루 섞인 세트들이 필요)
- 표준점수(standard score) : 훈련 세트의 스케일을 바꾸는 방법중 하나(특성의 평균 빼고 나누기 표준편차)
- 브로드캐스팅 : 다른 크기의 넘파이 배열을 자동으로 사칙연산 등 모든 행이나 열로 확장하여 수행
- 테스트세트 스케일을 바꿀 때도 훈련 세트의 mean,std를 이용하여 변환해야함
scikit-learn
- train_test_split() : 훈련 데이터를 훈련 세트와 테스트 세트로 나누는 함수, 비율은 test_size로 지정할 수 있으면 기본값 0.25
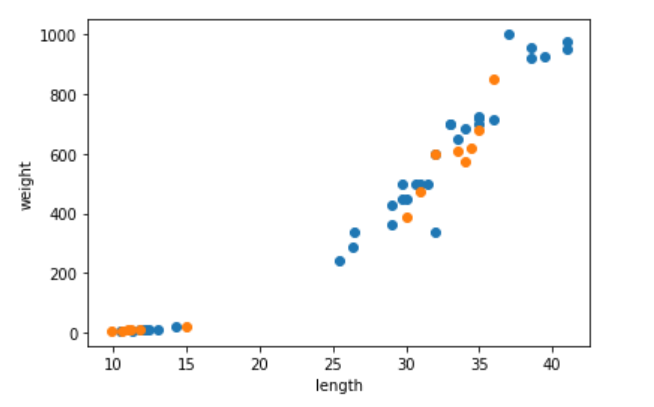
// 예시 train_input, test_input, train_target, test_target = train_test_split(perch_full, perch_weight, random_state=42) // stratify 매개변수에 타깃 데이터를 전달 하면 클래스 비율에 맞게 데이터를 나눔.
위의 경우 파란색이 train, 주황색이 test(왼쪽 아래는 빙어, 오른쪽위는 도미)
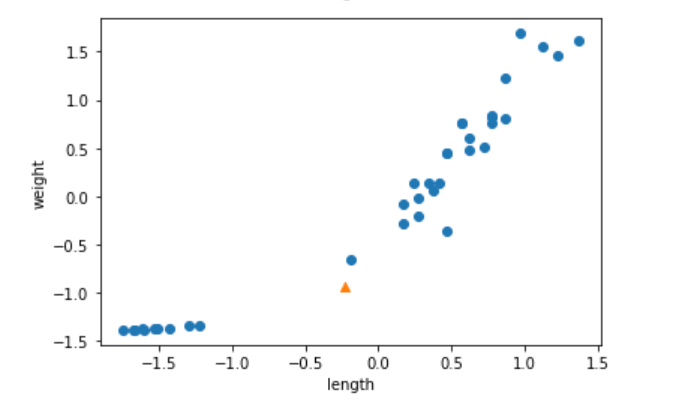
범위 스케일 조정의 경우
3. 회귀 알고리즘과 모델 규제
3.1 regression
- 지도 학습 : 분류 / 회귀(Regression)
1) 분류 : 샘플을 몇개의 클래스 중 하나로 분류하는 문제
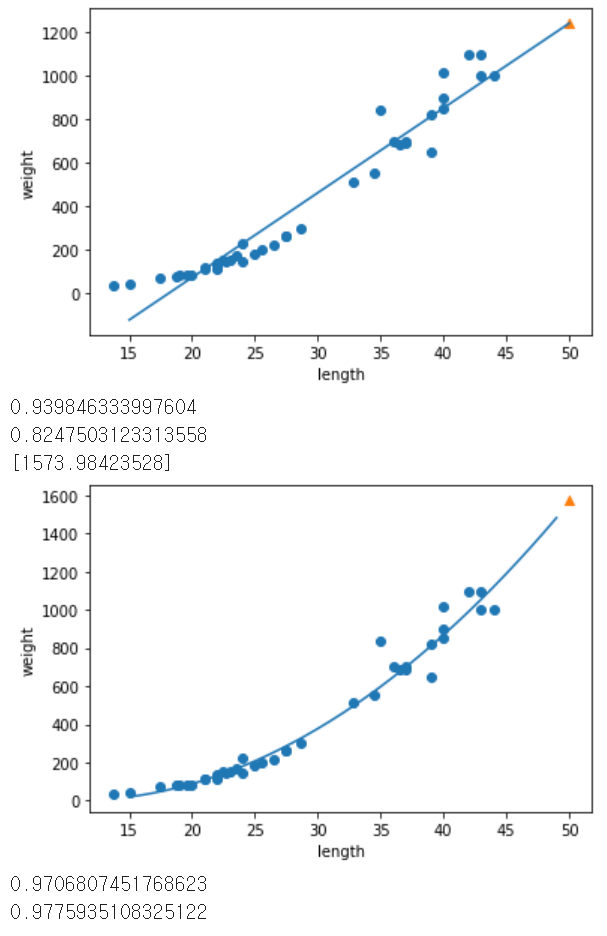
2) 회귀 : 임의의 어떤 숫자를 예측하는 문제, 임의의 수치를 출력(두 변수 사이의 상관관계를 분석하는 방법) - k-최근접 이웃 회귀 알고리즘 : KNeighborsRegressor()
- 결정 계수(R^2) : 회귀의 성능 측정도구(1에 가까울수록 좋음)
- 과대적합(overfitting) : 훈련 세트 점수는 좋은데 테스트 세트에서 점수가 굉장히 나쁘다면 모델이 훈련 세트에 오버피팅된 경우
(훈련 세트 점수가 너무 높으면 과대적합, 그 반대거나 두 점수가 모두 낮으면 과소적합, 과소적합의 경우 모델이 너무단순하거나 데이터크기가 작을 경우)
method
- score() : 출력값이 높을 수록 좋음. 정확도나 결정계수 또한.
- numpy의 reshape() : 바꾸려는 배열의 크기를 지정.(원본 배열 원소의 개수와 새로 지정한 크기가 같아야함, 크기에 -1을 지정하면 나머지 원소 개수로 모두 채우라는 의미)
train_input = train_input.reshape(-1,1)scikit-learn method
- KNeighborsRegressor : k-최근접 이웃 회귀 모델을 만듬(이웃 샘플의 타깃값의 평균)
- mean_absolute_error : 타깃과 예측의 절댓값 오차를 평균하여 반환
# 테스트 세트에 대한 평균 절댓값 오차를 계산 mae = mean_absolute_error(test_target, test_prediction)
3.2 linear regression
- 시간과 환경이 변화하면서 데이터도 바뀌기 때문에 주기적으로 새로운 훈련 데이터로 모델을 다시 훈련해야함.
- 선형 회귀(linear regression) : 특성이 하나인 경우 어떤 직선을 학습하는 알고리즘.
y = ax + b(기울기를 계수-coef, 가중치-weight라고 부름) - 모델 파라미터 : 머신 러닝 알고리즘이 찾은 값(많은 머신러닝 알고리즘의 훈련 과정을 최적의 모델 파라미터를 찾는 것 = 모델 기반 학습)
- 다항 회귀 : 다항식을 사용한 선형 회귀(2차 방정식의 그래프를 그리려면 길이를 제곱한 항이 훈련 세트에 추가되어야 함.)
다른 변수로 치환가능하므로 다항 회귀도 선형 회귀
scikit-learn method
- LinearRegression() : 선형 회귀 클래스
fit_intercept 매개변수를 False로 지정 시 절편을 학습 하지 않음.from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression train_input, test_input, train_target, test_target = train_test_split(perch_full, perch_weight, random_state=42) lr = LinearRegression() lr.fit(train_poly,train_target)
3.3 특성 공학과 regression
- 선형 회귀는 특성이 많을수록 엄청난 효과를 냄
-
다중 회귀 : 여러개의 특성을 사용한 선형 회귀 (특성이 2개면 평면을 학습 - 타깃, 특성1, 특성2의 축들을 가짐), 특성이 많은 고차원에서는 매우 복잡한 모델을 표현
-
특성 공학 : 기존의 특성을 사용해 새로운 특성을 뽑아내는 작업 (각 특성을 서로 곱해서 또다른 특성을 만듬.)
-
변환기 : 특성을 만들거나 전처리하기 위한 다양한 클래스(훈련을 해야 변환이 가능)
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(degree=5,include_bias=False)
# 기본적으로 각특성을 제곱한 항을 추가하고 특성끼리 서로 곱한 항을 추가
poly.fit(train_input)
train_poly = poly.transform(train_input)- 정규화 : 규제 적용 전 정규화, 훈련 세트로 학습한 변환기를 사용해 테스트 세트까지 변환해야함
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(train_poly)
train_scaled = ss.transform(train_poly)
test_scaled = ss.transform(test_poly)- 규제 (regularization) : 모델이 훈련 세트에 과대적합 되지 않도록 만드는 것.
- ridge, lasso : 선형 회귀 모델에 규제를 추가한 모델(릿지는 선형 모델의 계수를 작게 만들어 과대적합을 완화하며 alpha매개변수로 강도를 조절, 라쏘는 릿지와달리 계수 값을 아예 0으로 만들수도 있음)
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import Ridge
ss = StandardScaler()
ss.fit(train_poly)
train_scaled = ss.transform(train_poly)
test_scaled = ss.transform(test_poly)
ridge = Ridge()
ridge.fit(train_scaled, train_target)
train_score = []
test_score = []
alpha_list = [0.001, 0.01, 0.1, 1, 10,100]
for alpha in alpha_list:
ridge = Ridge(alpha=alpha)
ridge.fit(train_scaled, train_target)
train_score.append(ridge.score(train_scaled,train_target))
test_score.append(ridge.score(test_scaled,test_target))
ridge = Ridge(alpha=0.1)
ridge.fit(train_scaled, train_target)- 하이퍼파라미터 : 사람이 알려줘야하는 파라미터

Pitapat