혼자 공부하는 머신러닝 + 딥러닝 4
4. 1로지스틱 회귀
"K 최근접 이웃은 주변 이웃을 찾아주니까 이웃의 클래스 비율을 확률이라고 출력하면 되지 않을까?"
- 다중 분류 : 타깃 데이터에 2개 이상의 클래스가 포함된 문제
- 로지스틱 회귀 : 이름은 회귀이지만 분류 모델(기준이 되는 점은 사이킷런에서 음성 클래스로 판단), 선형 회귀와 동일하게 선형 방정식을 학습.
확률을 결과로 내고 싶을 때 시그모이드 함수 / 로지스틱 함수를 사용하면 가능
시그모이드의 방정식은 양 옆이 0,1로 수렴하는 그래프를 만들 수 있기 때문에 복잡한 계산으로 제작 - LogisticRegression은 기본적으로 릿지 회귀와 같이 계수의 제곱을 규제 -> L2규제(제어 매개변수는 C)
- 이진분류는 샘플마다 2개의 확률을 출력하고 다중 분류는 샘플마다 클래스 개수만큼 확률을 출력. 다중 분류는 클래스마다 Z값을 하나씩 게싼, 가장 높은 z값을 출력하는 클래스가 예측 클래스
- 이진 분류에서는 시그모이드로 z를 변환, 다중 분류는 소프트맥스 함수를 사용하여 z값을 확률로 변환. 소프트맥스 함수는 여러개의 선형 방정식의 출력값을 0~1 사이로 압축하고 전체 합이 1이 되도록 만듬(정규화된 지수함수)
- 분류 모델은 예측뿐만 아니라 예측의 근거가 되는 확률을 출력, 로지스틱 회귀는 회귀 모델이 아닌 분류 모델 - 선형 회귀처럼 선형 방정식을 사용 -> 값을 0~1사이로 압축하여 확률로 이해. 로지스틱 회귀는 이진 분류에서는 하나의 선형 방정식을 훈련. 다중 분류일 경우에는 클래스 개수만큼 방정식을 훈련하고 출력값을 소프트맥스 함수를 통과시켜 전체클래스 값이 항상 1이 되게 함.
import pandas as pd
fish = pd.read_csv('https://bit.ly/fish_csv_data')
fish.head()
print(pd.unique(fish['Species']))
fish_input = fish[['Weight','Length','Diagonal','Height','Width']].to_numpy()
print(fish_input[:5])
fish_target = fish['Species'].to_numpy()
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(
fish_input, fish_target, random_state=42)
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(train_input)
train_scaled = ss.transform(train_input)
test_scaled = ss.transform(test_input)
from sklearn.neighbors import KNeighborsClassifier
kn = KNeighborsClassifier(n_neighbors=3)
kn.fit(train_scaled, train_target)
print(kn.score(train_scaled,train_target))
print(kn.score(test_scaled,test_target))
print(kn.classes_)
print(kn.predict(test_scaled[:5]))
import numpy as np
proba = kn.predict_proba(test_scaled[:5])
print(np.round(proba, decimals=4))
distances, indexes = kn.kneighbors(test_scaled[3:4])
print(train_target[indexes])
bream_smelt_indexes = (train_target == 'Bream')| (train_target == 'Smelt')
train_bream_smelt = train_scaled[bream_smelt_indexes]
target_bream_smelt = train_target[bream_smelt_indexes]
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(train_bream_smelt,target_bream_smelt)
print(lr.predict(train_bream_smelt[:5]))
print(lr.predict_proba(train_bream_smelt[:5]))
print(lr.classes_)
print(lr.coef_, lr.intercept_)
decisions = lr.decision_function(train_bream_smelt[:5])
print(decisions)
from scipy.special import expit
print(expit(decisions))
lr = LogisticRegression(C=20, max_iter=1000)
lr.fit(train_scaled, train_target)
print(lr.score(train_scaled, train_target))
print(lr.score(test_scaled, test_target))
print(lr.predict(test_scaled[:5]))
print(lr.predict_proba(test_scaled[:5]))
proba = lr.predict_proba(test_scaled[:5])
print(np.round(proba,decimals=3))
decision = lr.decision_function(test_scaled[:5])
from scipy.special import softmax
proba = softmax(decision, axis=1)
print(np.round(proba,decimals=3))
- 로지스틱 회귀는 선형 방정식을 사용한 분류 알고리즘. 선형 회귀와 달리 시그모이드나 소프트맥스를 사용하여 클래스 확률을 출력
- 다중 분류 : 타깃 클래스가 2개 이상인 분류 문제. 로지스틱 회귀는 다중 분류를 위해 소프트맥스 함수를 사용하여 클래스를 예측.
- 시그모이드 함수 : 선형 방정식의 출력을 0과1 사이의 값으로 압축하며 이진 분류를 위해 사용.
- 소프트맥스 함수 : 다중 분류에서 여러 선형 방정식의 출력 결과를 정규화하여 합이 1이 되도록 만듬.
scikit-learn
- LogisticRegression : 선형 분류 알고리즘인 로지스틱 회귀를 위한 클래스. penalty 매개변수에서 L2규제(릿지 방식)와 L1규제(라쏘 방식)선택 가능. c 매개변수에서 규제의 강도를 제어
- predict_proba() : 예측 확률을 반환. 이진 분류의 경우에는 샘플마다 음성 클래스와 양성 클래스에 대한 확률을 반환. 다중 분류의 경우에는 샘플마다 모든 클래스에 대한 확률을 반환.
- decision_function() : 모델이 학습한 선형 방정식의 출력을 반환
4. 2 확률적 경사 하강법(Stochastic Gradient Descent)
- 점진적 학습 : 이전 훈련한 모델을 버리지 않고 새로운 데이터에 대해서만 조금씩 더 훈련
- 확률적 경사 하강법 : 대표적인 점진적 학습 알고리즘. 확률적(무작위하게, 랜덤하게), 경사(기울기), 하강법(내려가는 법), 가장 가파른 경사를 따라 원하는 지점에 도달하는 것이 목표인 경사 하강법(경사를 따라 내려가는 법). 훈련세트에서 랜덤하게 하나의 샘플을 고르는 것. 훈련 세트를 사용해 최적의 손실함수로 조금씩 이동하는 알고리즘.
- 에포크 : 확률적 경사 하강법에서 훈련 세트를 한번 모두 사용하는 과정(일반적으로 수십, 수백번 이상 에포크를 수행)
- 미니배치 경사 하강법(minibatch gradient descent) : 여러개의 샘플을 사용해 경사 하강법을 수행하는 방식
- 신경망 모델이 확률적 경사 하강법이나 미니배치 경사 하강법을 꼭 사용.
- 손실 함수 : 어떤 문제에서 머신러닝 알고리즘이 얼마나 엉터리인지를 측정하는 기준(작을 수록 좋지만 어떤 값이 최솟값인지는 모름)
- 손실 함수는 샘플 하나에 대한 손실을 정의하고, 비용함수(cost function)은 훈련 세트에 있는 모든 샘플에 대한 손실 함수의 합을 말함.
-
로지스틱 손실함수(logitic loss function) : -log(예측확률)
= 크로스엔트로피 손실함수(cross-entropy loss function) -
이진 분류는 로지스틱 손실 함수를 사용하고 다중 분류는 크로스엔트로피 손실 함수를 사용. 회귀에서는 평균 제곱 오차를 많이사용(mean squared error)
-
표준화 전처리 팁 : 꼭 훈련 세트에서 학습한 통계값으로 테스트 세트도 변환해야함.
import pandas as pd
fish = pd.read_csv("https://bit.ly/fish_csv_data")
fish_input = fish[['Weight','Length','Diagonal','Height','Width']].to_numpy()
fish_target=fish['Species'].to_numpy()
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(fish_input, fish_target,random_state=42)
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(train_input)
train_scaled = ss.transform(train_input)
test_scaled = ss.transform(test_input)
from sklearn.linear_model import SGDClassifier
sc = SGDClassifier(loss='log',max_iter=100, tol=None, random_state=42)
sc.fit(train_scaled, train_target)
print(sc.score(test_scaled,test_target))
print(sc.score(train_scaled, train_target))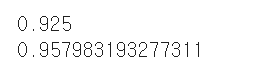
적은 에포크 횟수 동안에 훈련한 모델은 훈련세트와 테스트 세트에 잘 안맞는 과소적합된 모델일 가능성 높음
많은 에포크 동안 훈련한 모델은 훈련세트에 너무 잘맞아 테스트 세트에는 오히려 점수가 나쁜 과대적합된 모델일 가능성이 높음.
-
조기종료 : 과대적합이 시작하기 전에 훈련을 멈추는 것
-
힌지손실(hinge loss) : 서포트 벡터 머신이라 불리는 또다른 머신러닝 알고리즘을 위한 손실 함수
scikit-learn
- SGDClassifier : 확률적 경사 하강법을 사용한 분류 모델을 만듬. loss 매개변수는 확률적 경사 하강법으로 최적화할 손실 함수를 지정. 로지스틱 회귀를 위해서는 'log'로 지정. max_iter 매개변수는 에포크 횟수를 지정
- SGDRegressor : 확률적 경사 하강법을 사용한 회귀모델을 만듬.

Pitapat