데이터 분석 35일
🧠 챕터 1-1: 머신러닝이란?
핵심 포인트 요약
-
머신러닝이란?
→ 컴퓨터가 데이터로부터 스스로 패턴을 학습해 예측/분류를 수행하는 기술 -
머신러닝 3요소
→ 데이터, 알고리즘, 컴퓨팅 파워 -
AI, 머신러닝, 딥러닝의 관계
→ 딥러닝은 머신러닝의 하위, 머신러닝은 AI의 하위 -
머신러닝의 주요 분류
- 지도학습: 분류, 회귀
- 비지도학습: 군집화, 차원축소
- 강화학습: 보상 기반 학습 -
머신러닝 vs 통계
→ 머신러닝은 예측력 중시, 통계는 가설검증 중시
✅ 꼭 알아야 할 것:
- 머신러닝은 "얼마나 잘 예측하는가"에 초점
- 분류/회귀/강화학습의 차이 이해
- AI-ML-DL 구조 그림 머릿속에 그려두기
🧹 챕터 1-2: 머신러닝 전에 데이터 전처리!
핵심 포인트 요약
-
전처리 목적: 정확도 높이기 위해 노이즈 제거
-
주요 전처리 기법:
- 결측치 처리: 평균, 중앙값, 예측 대체 등
- 이상치 제거: Boxplot, 3σ rule, ML 기법
- 정규화/표준화: 스케일 맞추기 (MinMaxScaler, StandardScaler)
- 불균형 데이터 처리: SMOTE, 언더샘플링
- 범주형 인코딩: One-hot, Label Encoding
- 피처 엔지니어링: 파생변수 만들기, 변수 선택
✅ 꼭 알아야 할 것:
- 결측치/이상치 처리 방법 구분 가능해야 함
- MinMaxScaler vs StandardScaler 차이 구분!
- SMOTE가 뭐 하는 놈인지 개념 잡기 (소수 클래스 확장)
- 원-핫 인코딩은 서열 없는 범주형에, 라벨 인코딩은 서열 있을 때
📈 챕터 1-3: 값을 예측하고 싶어? 회귀!
핵심 포인트 요약
-
회귀는 숫자 예측 (ex. 주가, 온도)
-
선형 회귀: X와 Y가 일직선 관계일 때
-
다항 회귀: X², X³ 같이 곡선 형태 모델링 가능
-
평가 지표:
- MSE: 제곱 오차 평균 (큰 오차에 민감)
- MAE: 절대값 오차 평균
- RMSE: MSE에 루트 씌운 것
- R²: 설명력, 1에 가까울수록 좋음 -
규제 기법:
- 릿지 (Ridge): 계수 줄임 (L2)
- 라쏘 (Lasso): 계수를 0으로도 (L1 → 변수 선택 효과 있음)
✅ 꼭 알아야 할 것:
- 선형 vs 다항 회귀 차이 이해
- MSE, MAE, RMSE, R² 각각 언제 쓰는지
MSE: 큰 오차에 벌 주고 싶을 때
MAE : 직관적인 평균 오차 보고 싶을 때
RMSE: MSE 성격 + 해석 쉬운 단위로 보고 싶을 때
R²: 전체 설명력을 %로 보고 싶을 때 - 릿지/라쏘는 과적합 방지용!
- 릿지: 변수 다 유지 / 라쏘: 변수 줄이기
🧾 챕터 1-4: 무엇인지 맞추고 싶어? 분류!
핵심 포인트 요약
-
분류는 범주 예측 (ex. 스팸/정상, 합격/불합격)
-
대표 모델:
- 로지스틱 회귀: 선형 회귀 + 시그모이드 함수
- SVM: 경계선을 가장 잘 찾는 알고리즘
- KNN, 나이브 베이즈, 딥러닝 등도 사용 -
평가 지표:
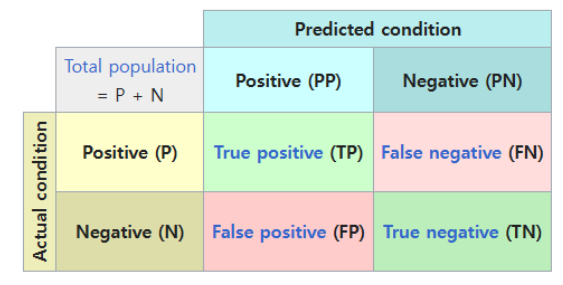
- Confusion Matrix: TP, TN, FP, FN
Type I = FP, Type II = FN
Confusion Matrix와 에러 타입은 같은 개념을 다른 시각으로 표현한 것!
- Precision: 예측한 것 중 얼마나 맞았나
- Recall (TPR): 실제 Positive 중 얼마나 맞췄나
- F1-score: Precision & Recall 조화
- ROC / AUC: TPR vs FPR 시각화 곡선
✅ 꼭 알아야 할 것:
-
로지스틱 회귀 vs 선형 회귀 차이
선형 회귀는 "숫자 예측",
로지스틱 회귀는 "확률을 예측해서 분류"하는 회귀 -
SVM의 최적 경계선 개념
SVM: "클래스를 가장 잘 나누는 선"을 찾는 분류 알고리즘
📝 SVM은 단순히 "나누는 선"을 찾는 게 아니라
👉 두 클래스와 가장 가까운 거리(마진)가 최대한 넓은 선을 찾 -
Precision(정밀도) vs Recall(재현율)
- 구분: Precision -> 스팸 분류, Recall -> 질병 진단- Precision: 예측한 양성 중 실제로 양성인 것의 비율
Precision = TP / (TP + FP) - Recall: 실제 양성 중 예측한 양성의 비율
Recall = TP / (TP + FN)✔️ Precision은 "내가 양성이라고 말한 것 중 진짜 양성이 얼마나 되냐?" → 정확하게 골라냈냐?
예) 10개 스팸이라 했는데, 7개만 진짜 스팸 → Precision = 70%
✔️ Recall은 "실제 양성 중에서 내가 몇 개나 맞췄냐?" → 놓친 건 없냐?
예) 실제 스팸이 20개였는데, 7개만 맞췄다면 → Recall = 35%
- Precision: 예측한 양성 중 실제로 양성인 것의 비율
-
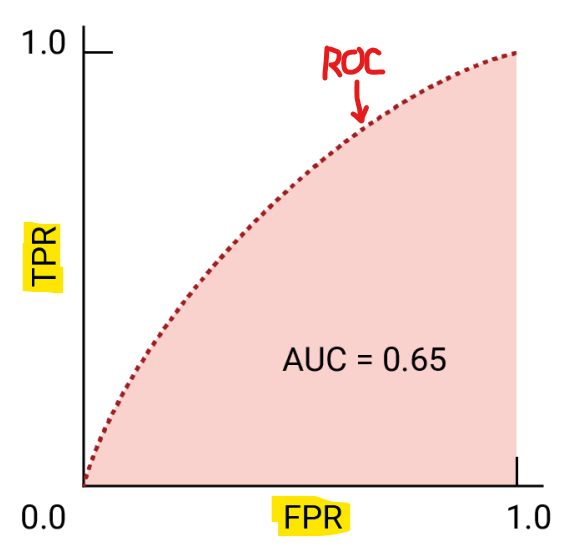
ROC 곡선은 TPR과 FPR 변화를 보여주는 그래프
TPR: 진짜를 놓치지 않고 잘 맞췄는가? (민감도, 재현율)
FPR: 아닌 걸 잘못 긁어온 건 얼마나 되나? (거짓 경보) -
AUC는 ROC 곡선의 면적 → 1에 가까울수록 좋음
-이 면적이 클수록 모델 성능이 좋다는 뜻!
- AUC = 1: 완벽한 분류기
- AUC = 0.5: 랜덤한 분류기
- AUC < 0.5: 성능이 오히려 반대 방향
✏️ 용어정리...
다중공선성
- 다중공선성(multicollinearity)은 설명 변수(독립 변수)들끼리 서로 강하게 상관관계가 있는 현상
⚠️ 다중공선성이 생기면 문제점:
- 회귀계수(β)가 불안정해짐 → 해석 어려움
- 계수가 크게 튀거나 부호가 반대일 수도 있음
- 예측 성능 자체는 괜찮지만, 해석력↓, 신뢰도↓
✅ 해결 방법:
- 상관관계 높은 변수 제거
- 릿지 회귀(Ridge Regression) 사용 → 다중공선성 완화에 효과적
