Chapter 8
추가적인 작업 분할 지시어
1. 작업 분할 지시어
개요
- 병렬 영역 내부에 삽입하여 작업 할당에 이용
- 새로운 스레드 생성 없이 기존 스레드에 관련작업 실행 분배
종류
- do/for
- sections
- single
- workshare(Fortan only)
2. 동기화
구문의 시작점
- 스레드 사이 동기화 X
- 먼저 접근하는 스레드에 우선적 작업 할당
구문의 끝점
- 동기화(묵시적 장벽)
- 작업이 먼저 끝나도 다른 작업의 완료까지 대기
- 대기 없이 다른 작업을 실행하려면 nowait clause 사용
Sections, Single, Master
1. Sections
정의
#pragma omp sections로 정의- 여러 스레드에 작업 단위로 분배, 병렬처리 기능
사용
- 스레드 팀에 있는 각각 스레드를
#pragma omp sections로 작업을 나눔 - 해당 작업은 스레드 팀 중에서 하나의 스레드에 의해 한번만 실행
- 어떤 스레드가 어떤 section을 수행할지 보장 X
- 작업을 할당 받지 못한 스레드는 묵시적 동기화 지점에서 대기
Example - C code
#include <stdio.h>
#include <omp.h>
int main()
{
int i, a[10], b[20];
omp_set_num_threads(2);
#pragma omp parallel private(i)
{
#pragma omp sections
{
#pragma omp section
for (i=0; i<10; i++)
a[i] = i*10 + 5;
#pragma omp section
for (i=0; i<20; i++)
b[i] = i*5 + 10;
}
}
for (i=0; i<10; i++)
printf("%d ",a[i]);
printf("\n");
for (i=0; i<20; i++)
printf("%d ",b[i]);
printf("\n");
}Example - 결과 및 해석

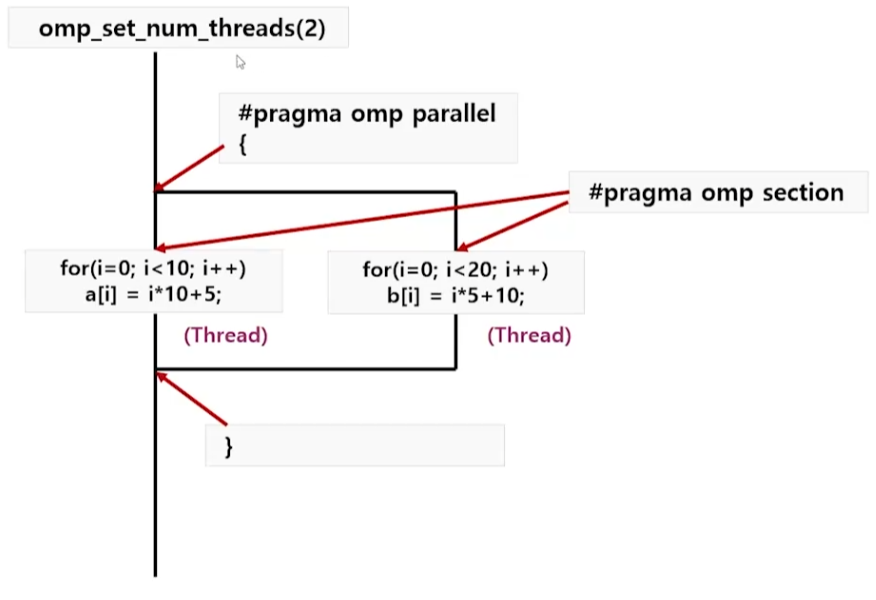
- 각기 다른 스레드에서 a[], b[] 초기화 진행
- 어떤 스레드가 어떤 section의 작업을 수행할지는 확정 X
2. Single
정의
#pragma omp single로 정의- 스레드 팀 중 하나의 스레드만 해당 코드를 실행할 것을 지정
사용
- 다른 스레드들은 single 지시어로 지정된 스레드가 실행을 완료할 때까지 암시적 동기화 지점에서 대기
- 가장 먼저 single 지시어에 도착한 스레드가 해당 작업 수행
Example - C code
#include <stdio.h>
#include <omp.h>
int main()
{
omp_set_num_threads(32);
#pragma omp parallel
{
#pragma omp single
{
printf("hello world\n");
}
}
}Example - 결과 및 해석
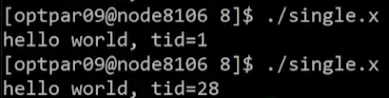
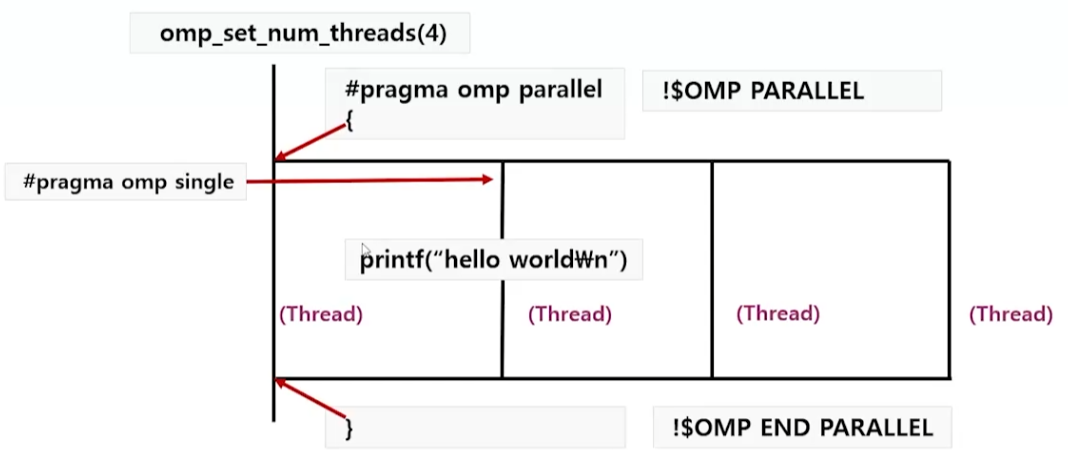
- 한줄의 "hello, world!" 만 출력
- 작업을 수행하는 스레드는 먼저 도달한 스레드 -> 매번 달라짐
3. Master
정의
- single과 거의 유사함
#pragma omp mastersection을 마스터 스레드(0번)에서만 실행- 다른 스레드들은 해당 section을 건너뛰며, 묵시적 barrier X
4. 정리
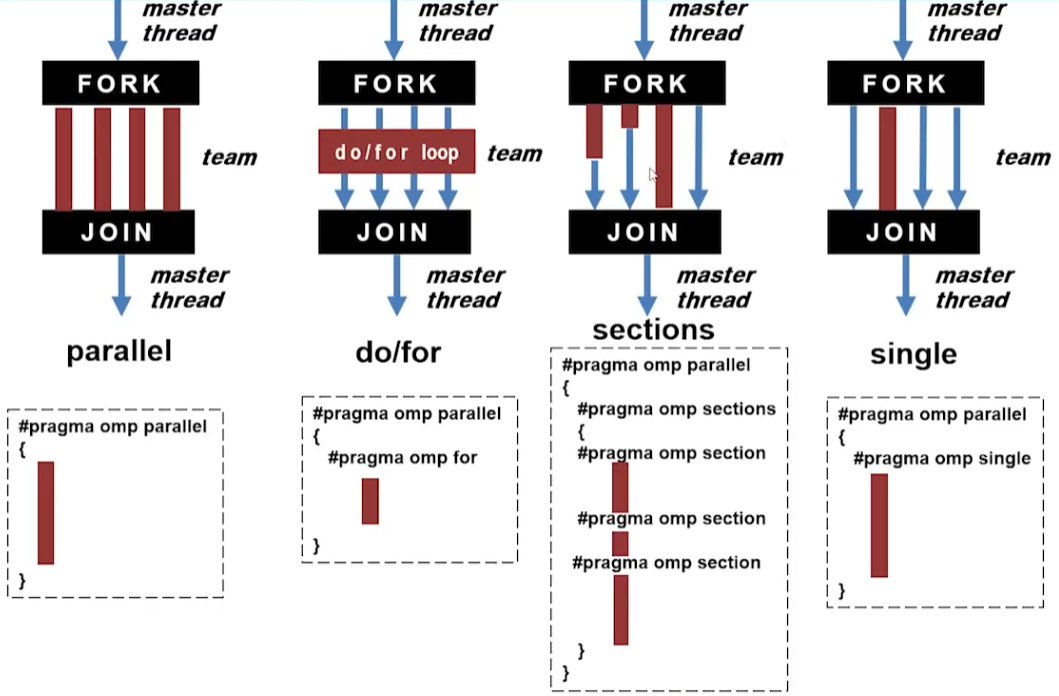
Nowait, Ordered
1. Nowait
정의
- nowait 보조 지시어 사용
- 묵시적 barrier 제거 -> 코드를 신중하게 작성해야 함
사용
- nowait 지정 시, 먼저 작업 종료한 스레드는 barrier에 대기하지 않고 다음 작업 실행
- 병렬 영역 내에 독립된 복수의 분할 작업이 있는 경우, nowait 사용하여 성능 개선 가능
- 단, Reduction과 Nowait 동시 사용의 경우, 각 스레드 합산 과정 중 data racing 발생 가능성 있음
Example 1 - C code
#include <stdio.h>
#include <omp.h>
int main()
{
int x=1;
omp_set_num_threads(16);
#pragma omp parallel
{
#pragma omp single nowait
{
x++;
printf("x=%d\n", x);
}
#pragma omp single
{
x++;
printf("x=%d\n", x);
}
}
return 0;
}Example 1 - 결과 및 해석
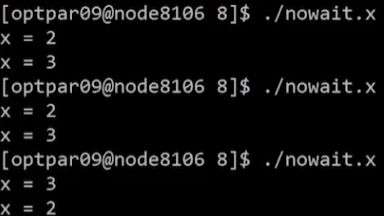
- 출력값이 일정하지 않음
#pragma omp single nowait로 인해 묵시적 barrier가 없어짐- Example1 에서는 각 섹션에서 모두 x를 RW -> data racing 발생
Example 2 - C code
#include <stdio.h>
#include <omp.h>
#define N 10000
int main()
{
int i, j , a[N][N];
omp_set_num_threads(4);
#pragma omp parallel private(i,j)
{
// 행렬의 위쪽 삼각형 초기화
#pragma omp for nowait
for (i=0; i<N; i++)
for (j=i; j<N; j++)
a[i][j] = i+j;
// 행렬의 아래쪽 삼각형 초기화
#pragma omp for
for (i=0; i<N; i++)
for (j=0; j<i; j++)
a[i][j] = i-j;
}
}Example 2 - 결과 및 해석
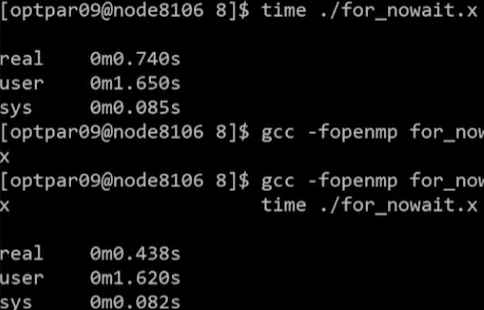
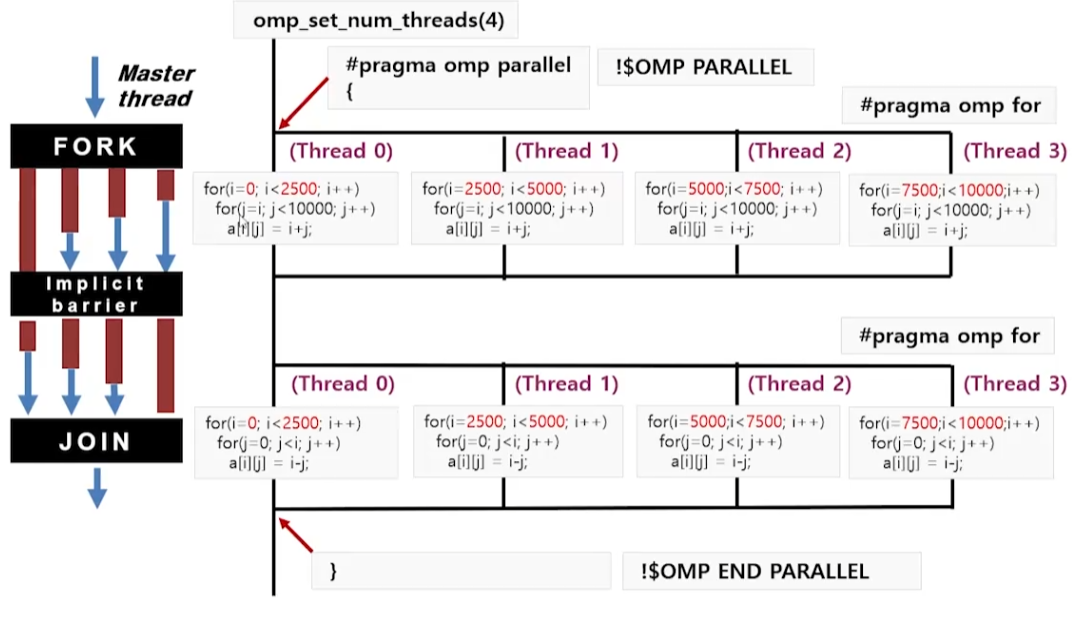
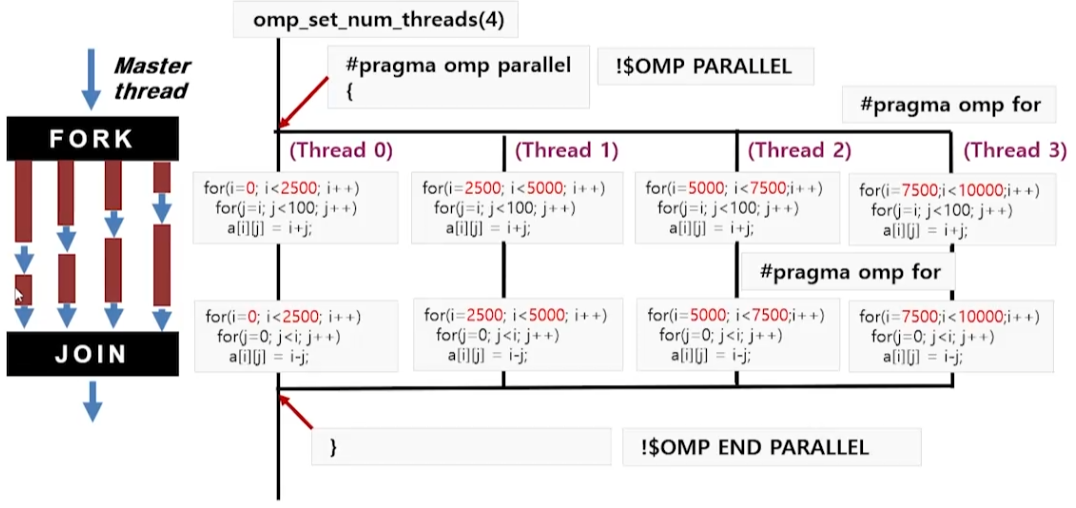
- nowait를 사용했을 때(아래쪽) 확실히 성능이 더 좋음
- 각각의 section이 분리된 영역을 다룸 -> data racing 발생 X
- nowait 옵션 사용 시 성능을 향상시킬 수 있다!
2. Ordered
정의
orderedsection 내부의 루프 실행을 순차적으로 진행- 하나의 병렬 루프에 하나만 허용
- 병렬 루프 지시어는
orderedclause를 가져야 함 orderedsection을 실행하는 스레드는 매 순간 한개
Example - C code
#include <stdio.h>
#include <omp.h>
#define N 10000
int main()
{
int i, a[5];
omp_set_num_threads(4);
#pragma omp parallel private(i)
{
#pragma omp for ordered
for (i=0; i<5; i++)
{
a[i]=i*2; // 병렬 처리 (순서 X)
#pragma omp ordered
printf("a[%d] = %d\n",i,a[i]); // 순차 처리
}
}
}Example - 결과 및 해석
a[0] = 0
a[1] = 2
a[2] = 4
a[3] = 6
a[4] = 8- a[]의 원소들이 순서대로 출력됨
a[i]=i*2;구문은 순서 상관없이 병렬적으로 처리됨printf("a[%d] = %d\n",i,a[i]);구문은 앞의 스레드들이 모두 작업이 마칠 때 까지 뒤의 스레드들이 대기- 성능은 좀 떨어질 수 있으나, 파일 출력 등 순서가 중요한 작업에서 ordered를 사용

올해는 진짜 갓생 산다