Chapter 3
Thread Hierarchy
1. CUDA Programming
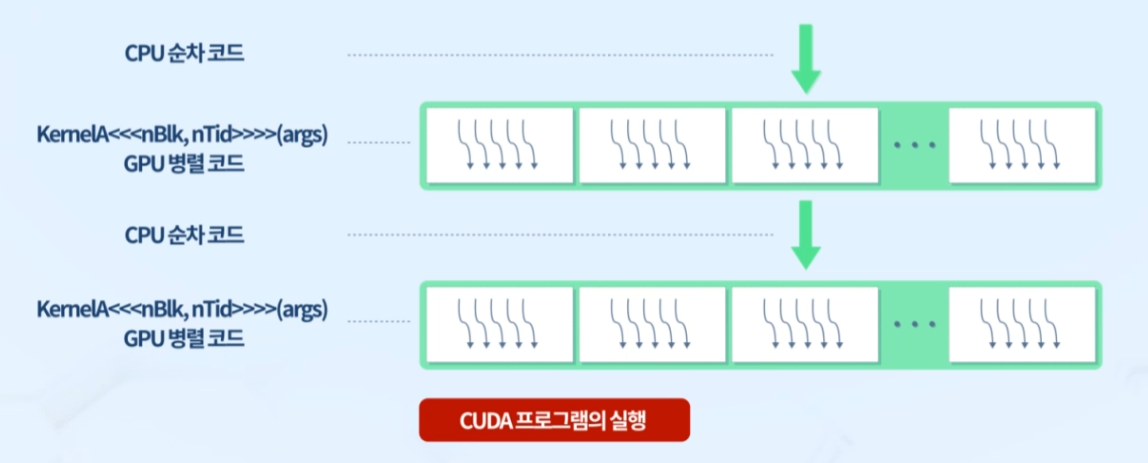
순차 코드는 host에서, 병렬 코드는 device에서
Open MP의 Fork-Join Model과 유사
- Open MP는 CPU에서 실행, data를 구간별로 나눈 data chunk를 각 코어가 순차적으로 실행
static or dynamic하게 core에 data chunk 할당 - CUDA는 data 개수만큼 thread 생성되어 GPU에서 실행 -> thread 개수 > 코어 개수여야 GPU 성능 최대한 활용 가능
thread를 1대1로 많이 생성하여 스케줄링
2. CUDA Thread Hierarchy
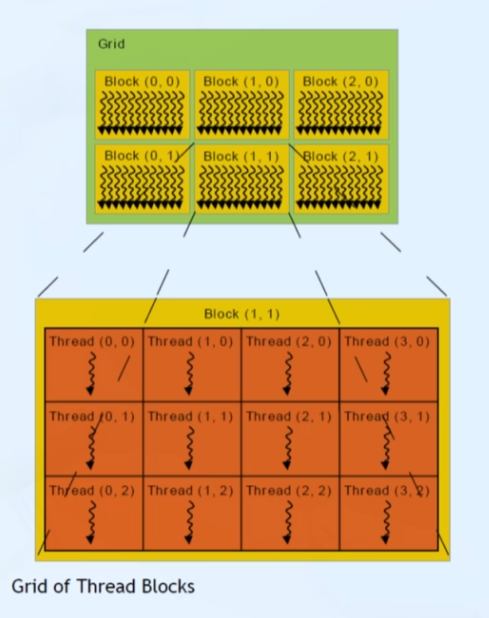
커널 함수가 호스트에서 호출될 때, 많은 수의 스레드가 생성됨
스레드 계층 구조: 스레드 블록 + 그리드
그리드와 스레드 블록 크기를 구하는 built-in 변수
- gridDim: 그리드 크기(그리드 내의 블록 수)
gridDim.x, gridDim.y, gridDim.z - blockDim: 블록 크기(블록 내의 스레드 수)
blockDim.x, blockDim.y, blockDim.z
그리드와 스레드 블록은 dim3 타입의 3차원으로 구성
- 사용되지 않은 field는 1로 초기화 후 무시됨
- 1st, 2nd, 3rd 성분은 각각 x,y,z field로 접근 가능
스레드는 서로 구분 위해 고유한 좌표를 필요로 함
- blockIdx: 그리드 내에서 블록 인덱스
- threadIdx: 블록 내에서 스레드 인덱스
Thread 인덱싱
- 프로그래밍 시, 어떤 thread가 어떤 data를 처리할지 인덱싱을 해야 함
- data 개수가 홀수거나 딱 떨어지지 않는 경우,thread 개수가 data 개수보다 조금 더 크도록 구성
2. CUDA Thread Hierarchy
스레드 블록 크기, 데이터 크기로 grid 크기 결정
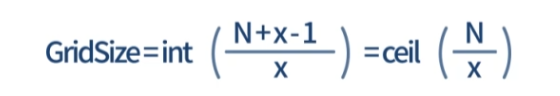
데이터의 크기: N, 스레드 블록의 크기: x
- Case1: 데이터 크기가 블록 크기의 배수 O
N= 100, x= 20
GridSize=int[(100+20-1)/20]=int[5.95]=5 - Case2: 데이터 크기가 블록 크기의 배수 X
N=100, x=17
GridSize=int[(100+17-1)/17]=int[6.82]=6
17*6-100=2개의 스레드는 작업에 참여 X
3. Global Index 계산

스레드 인덱스, 블록 인덱스로 글로벌 인덱스 결정
int idx = blockdim.x*blockIdx.x + threadIdx.xex. if blockIdx = 2, threadIdx = 3
한 블록에 스레드 8개 -> blockdim = 8
idx = 8 * 2 + 3 = 19
4. 2D Grid & 2D Blocks
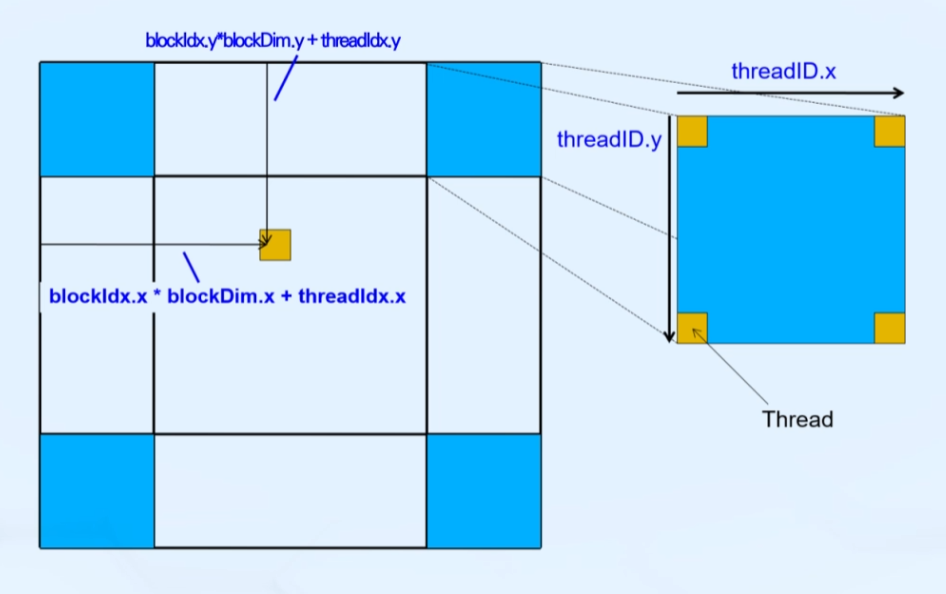
x축 y축 각각 독립적으로 global index 구하기
__device__ int gelGlobalIdx_2D(const int N)
{
int col = blockdim.x*blockIdx.x + threadIdx.x
int row = blockdim.y*blockIdx.y + threadIdx.y
int index = row*N + col
return index;
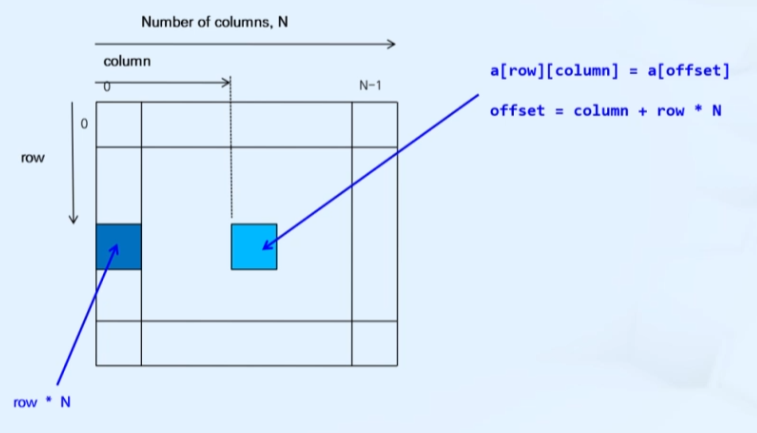
}a[row][column] = a[offset]
offset = column + row*N
(N은 column의 개수)- cache miss 방지를 위해 실제 계산 데이터는 항상 1차원으로 해두고 index만 2차원으로 처리하는 방법 사용
- 2차원 block을 row를 쭉 나열한 1차원 array라고 생각하기
Example

- C = A + B를 수행하는 코드
segmentation fault방지를 위해if (idx_x < N && idx_y < M)조건문이 들어감
CUDA Kernel
1. Kernel 코드 작성
디바이스(GPU)에서 실행되는 코드
- 커널 함수에서는 단일 스레드에 대한 계산, 해당 스레드에 대한 데이터 접근을 정의
- 커널 호출 시, CUDA 스레드들은 병렬로 동일 연산 수행(SIMT)
- 커널은 __global__ 선언 한정자를 사용하여 정의
__global__ voidkernel_name(argument list);2. Kerenl 함수 한정자
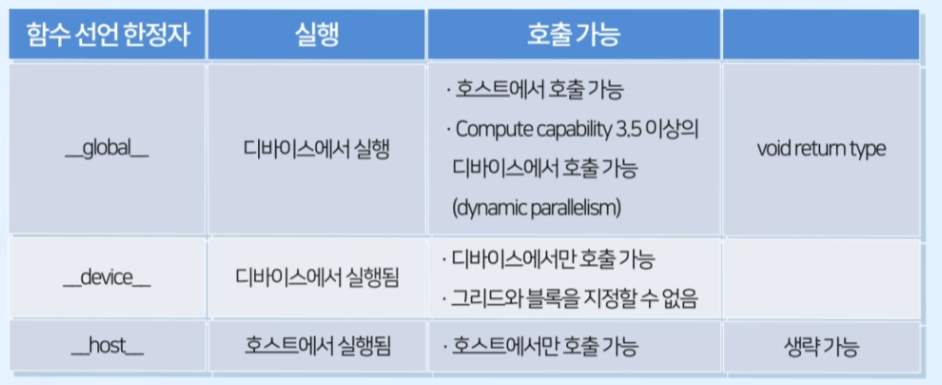
__global__: 호출은 host, 실행은 device에서 하는 함수
- CC 3.5 이상에서는 device에서도 호출 가능하도록 변경
- void 타입만 지원 -> return 타입 지정 불가
return이 필요한 경우, 매개변수 활용
__device__: 커널 속에서 실행하는 커널함수
- 디바이스에서만 호출 가능
- CC 3.5 이상에서는 global 한정자도 허용
즉, 대부분 global 한정자를 사용하면 됨
__host__: CUDA와 관련 없는 일반 C 함수
- 생략 가능
__device__와 __host__는 함께 사용 가능
- 함께 사용하는 경우, 함수는 host와 device 모두에 대해 컴파일 되는 generic function이 됨
3. Kernel 호출: C 함수 호출의 확장 형태
커널 호출 시 그리드와 스레드 블록의 크기를 <<<>>>안에 지정
function.name<<<grid, block>>>(argument list);
- grid: 그리드의 크기 (블록 개수)
- block: 스레드 블록 크기 (블록 별 스레드 개수)
ex. 4 * 8 = 32개의 스레드 사용
kernel_name<<<4,8>>>(argument list);4. Kernel 호출: 비동기적 호출
커널 호출은 호스트 스레드에 대해 비동기적
- 일반적인 C 프로그램: 어떤 함수 실행 후 그 함수의 작업이 끝나면 다음줄로 넘어감
- CUDA: 커널 함수 호출 시, GPU에 작업을 넘겨주고 host는 바로 다음줄로 넘어감
동기화 함수: cudaDeviceSynchronize()
__host__ __device__ cudaError_tcudaDeviceSynchronize(void);
- 모든 커널 계산이 완료될 때 가지 host application을 blocking시키기 위해
cudaDeviceSynchronize()함수를 호출 cudaMemcpy()사용 시, 호스트 쪽에서 묵시적 동기화 -> 데이터 복사 완료까지 application 대기
초기화 함수: cudaDeviceRest()
__host__ cudaError_tcudaDeviceReset(void); - 현재 device의 모든 할당 해제, 모든 state 초기화
- 이 함수 이후 디바이스에 대한 API 호출은 디바이스를 다시 초기화
- CUDA 프로그램 작성 시, 더 이상 디바이스를 사용하지 않는다면 이 함수를 꼭 써주는 것이 좋음
5. Multi Stream (Scheduling)

- GPU 자원을 최대한 활용하고 실행 시간을 줄이기 위해 scheduling 필요
- CUDA에서 기본적으로 scheduling 기능을 제공
CUDA Kernel: Example
1. 커널 함수 호출 예제
C code
#include <stdio.h>
__global__ void GPUKernel(int arg)
{
printf("Input Value (on GPU)= %d\n", arg);
}
int main(void)
{
printf("Call Kernel Function! \n");
GPUKernel<<<1,1>>>(1);
GPUKernel<<<1,1>>>(2);
cudaDeviceSynchronize();
return 0;
}
Compile
$ nvcc [-arch=sm_70] kernel_test.cu -o kernel_test[-arch=sm_70]은 GPU architecture를 지정
Result

cudaDeviceSynchronize()가 없다면,GPUKernel()은 실행되지 못하고 application이 종료됨- 동기화 함수 대신 마지막에
cudaDeviceRest()을 사용해도 됨
2. global, device 모두 사용하는 예제
C code
#include <stdio.h>
__global__ void helloFromHost();
__device__ int helloFromDevice(int tid);
int main()
{
helloFromHost<<<1,5>>>();
cudaDeviceReset();
return 0;
}
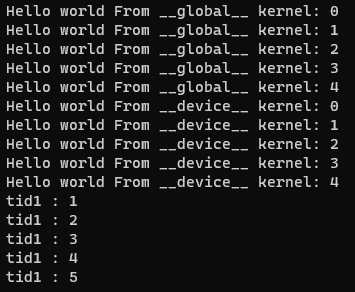
__global__ void helloFromHost()
{
int tid = threadIdx.x;
printf("Hello world From __global__ kernel: %d\n", tid);
int tid1=helloFromDevice(tid);
printf("tid1 : %d\n", tid1);
}
__device__ int helloFromDevice(int tid)
{
printf("Hello world From __device__ kernel: %d\n", tid);
return tid+1;
}Result