동작검출
import cv2
import mediapipe as mp
# 그리기 기능
mp_drawing = mp.solutions.drawing_utils
# 전체적인 검출 => 몸전체
mp_holistic = mp.solutions.holistic
# 비디오 불러오기
cap = cv2.VideoCapture('data/face4.mp4')
# 한개면 되지만 두개인 이유는 점과 선 색을 나눠 구분하기위해
drawing_spec1 = mp_drawing.DrawingSpec(thickness=1, color= (0,0,255))
drawing_spec2 = mp_drawing.DrawingSpec(thickness=3, color= (255,0,0))
with mp_holistic.Holistic(min_detection_confidence=0.5,
min_tracking_confidence=0.5) as holistic:
while True :
# 불러온 비디오에서 프레임단위로 가져오기
ret, frame = cap.read()
if not ret:
print('종료')
cap.release()
cv2.destroyAllWindows()
break
frame.flags.writeable = False
result = holistic.process(frame)
frame.flags.writeable = True
mp_drawing.draw_landmarks(frame, result.pose_landmarks,
mp_holistic.POSE_CONNECTIONS,
landmark_drawing_spec=drawing_spec1,
connection_drawing_spec=drawing_spec2)
cv2.imshow('pose',frame)
k = cv2.waitKey(33)
if k==49 :
cap.release()
cv2.destroyAllWindows()
break
frame = cv2.imread('data/test1.png')
with mp_holistic.Holistic(min_detection_confidence=0.5,
min_tracking_confidence=0.5) as holistic:
frame.flags.writeable = False
result = holistic.process(frame)
frame.flags.writeable = True
mp_drawing.draw_landmarks(frame, result.pose_landmarks,
mp_holistic.POSE_CONNECTIONS,
landmark_drawing_spec=drawing_spec1,
connection_drawing_spec=drawing_spec2)
cv2.imshow('pose',frame)
cv2.waitKey(0)
cv2.destroyAllWindows()
RNN/LSTM
순환신경망, RNN활용, Keras활용 신경망 구축
RNN
=>
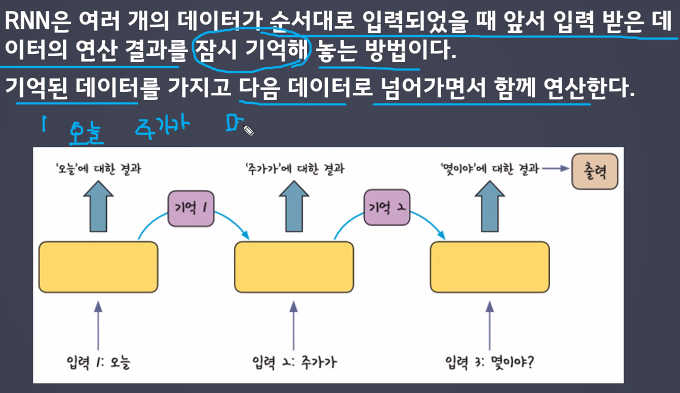
# 영어단어의 마지막글자 맞추기
# 14개의 알파벳 사용
# l,o,b,y,d,a,r,i,g,h,t,e,v,c
# 원핫인코딩으로 표현
l = [1,0,0,0,0,0,0,0,0,0,0,0,0,0]
o = [0,1,0,0,0,0,0,0,0,0,0,0,0,0]
b = [0,0,1,0,0,0,0,0,0,0,0,0,0,0]
y = [0,0,0,1,0,0,0,0,0,0,0,0,0,0]
d = [0,0,0,0,1,0,0,0,0,0,0,0,0,0]
a = [0,0,0,0,0,1,0,0,0,0,0,0,0,0]
r = [0,0,0,0,0,0,1,0,0,0,0,0,0,0]
i = [0,0,0,0,0,0,0,1,0,0,0,0,0,0]
g = [0,0,0,0,0,0,0,0,1,0,0,0,0,0]
h = [0,0,0,0,0,0,0,0,0,1,0,0,0,0]
t = [0,0,0,0,0,0,0,0,0,0,1,0,0,0]
e = [0,0,0,0,0,0,0,0,0,0,0,1,0,0]
v = [0,0,0,0,0,0,0,0,0,0,0,0,1,0]
c = [0,0,0,0,0,0,0,0,0,0,0,0,0,1]
# 단어 만들기
# lobby, daddy, right, light, heavy, heart, dvice, dhict
import numpy as np
data = np.array(
[
[l,o,b,b,y],
[d,a,d,d,y],
[r,i,g,h,t],
[l,i,g,h,t],
[h,e,a,v,y],
[h,e,a,r,t],
[d,v,i,c,e],
[d,h,i,c,t]
]
)
data.shape
# (data수, time step, feature)
X = data[:,:-1]
y = data[:,-1]
X.shape, y.shape
# 모델링
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense, SimpleRNN
model = Sequential()
model.add(SimpleRNN(units = 10, input_shape=(4,14),# timestep, feature
activation = 'tanh'))
model.add(Dense(units = 14, activation='softmax'))
model.compile(
loss='categorical_crossentropy',
optimizer = 'adam',
metrics = ['accuracy']
)
model.fit(X,y,epochs=300)
model.predict([[h,e,a,r]])영화 긍정부정
from tensorflow.keras.datasets import imdb
# 특성으로 사용할 단어 수
max_feature = 2000
(X_train,y_train),(X_test,y_test) = imdb.load_data(num_words = max_feature)
# sample, timestep, feature
X_train.shape
import numpy as np
# 긍정 , 부정 데이터
np.unique(y_train)
len(X_train[0]) # 하나의 리뷰, 이미 단어하나마다 번호가 할당되어있다.
# 리뷰 길이 똑같게 맞춰주기 => 평균길이
print('리뷰의 최대 길이 :',max(len(i) for i in X_train))
print('리뷰의 최소 길이 :',min(len(i) for i in X_train))
print('리뷰의 평균 길이 :',sum(map(len, X_train))/len(X_train))
# 모든 리뷰의 길이를 238로 통일시키기
# 짧으면 앞에 0 채우기
# 길면 짜르기
max_len = 238
from tensorflow.keras.preprocessing import sequence
X_train_seq = sequence.pad_sequences(X_train,maxlen = max_len)
X_test_seq = sequence.pad_sequences(X_test,maxlen = max_len)
import matplotlib.pyplot as plt
len_data = [len(s) for s in X_train]
plt.hist(len_data,bins = 100)
plt.show()
꾸준히