[Paper Review] UNSUPERVISED SEMANTIC SEGMENTATION BY DISTILLING FEATURE CORRESPONDENCES
Paper Review
ICLR 2022
https://arxiv.org/pdf/2203.08414.pdf
Abstract
Unsupervised semantic segmentation은 대량의 이미지를 통해 annnotation 없이도 semantic segmentation을 가능하게 하는 것입니다. 기존의 방식은 end to end의 single framework를 사용했으나 본 논문에서는 feature learning과 compatificaiton을 분리합니다. 본 모델의 성능은 다양한 지표에서 SOTA를 달성했습니다.
Introduction
Semantic segmentation 더 작은 단위로 detect하고 delineate 합니다. pixel단위로 classification하는 것과 같습니다. 이 논문 이전에 weaker forms of labels를 활용해 semantic segmentation을 진행했습니다. Semantically meaningful한 feature를 뽑는 방향으로 연구가 진행되어왔습니다. 본 논문에서는 pretrained feature들을 활용하여 compact하고 discrete한 구조에 distilling하는 방식을 제시합니다. 정리하면 새로운 contrastive loss를 활용하여 pretrained unsupervised visual feature를 semantic cluster에 distill 하는 방식입니다.
Related Works
Self supervised Visual Feature Learning
사람의 annotation 없이 의미있는 feature를 학습하는 것은 컴퓨터비전의 오랜 목표였습니다. Contrastive learning 에서 augmentation이 진행되어도 visual feature들은 invariant 하다고 가정합니다. 비슷한 것은 유사도를 올리고 다른 것은 유사도를 낮추는 방식으로 작동합니다. STEGO는 visual feature를 learn하고 clustering하는 대신에 pretrained된 self supervised feature를 input으로 사용합니다.
Unsupervised Semantic Segmentation
self supervised feature learning에서 테크닉들을 많이 활용합니다. IIC, Contrastive clustering, and SCAN이 그 예시입니다. 이는 negative smaple과 nearest neighbors로 supervision하여 사용합니다. 하지만 이 때는 semantic segmentation을 진행하진 않았습니다. PiCIE에서는 distance를 k-mean clustering의 반복으로 결정한다고 했을 때 다른 transformation 사이에서의 distance를 최소화하는 방식으로 학습합니다. Segsort의 경우 superpixel을 proxy sementation map으로 활용하여 Expectation Maximization 방식으로 segment를 refine합니다.
SegSort (ICCV 2019)
기존 semantic segmentation은 pixel 단위의 classificaiton으로 해결합니다.
하지만 사람은 pxiel 단위의 인식이 안리ㅏ 인지의 최소 단위로 분해하여 scene을 인지합니다.
여기서 착안하여 같은 semantic class를 갖는 개별 이미지를 비교하는 방식으로 옳은 segmentaiton을 찾습니다.
inference는 pixelwise embedding 추출과 clustering으로 이루어지고 label은 nearest neighbor의 majority vote로 이루어집니다.
MaskContrast의 경우 이미 만들어진 model을 활용해 binary mask를 생성하고 그 saliency mask들을 contrast합니다.
본 논문에서는 이미 존재하는 pretrained self supervised visual feature를 추려서 correspondence information에 distill하여 cluster를 합니다. low rank factorization이 unsupervised co-segmentation에서 효과적이라는 것과 유사합니다
- low rank factorization은 더 작은 차원으로 분해하는 것으로 예시로는 SVD(singular value decomposition)이 있습니다.
Visual Transformer
CNN은 알다시피 CV에서 가장 널리 사용되어온 아키텍쳐입니다. long range interaction을 하기 힘들다는 단점이 존재하고 이를 해결하기 위해 self-attention 메커니즘을 적용했습니다. 그 후 Transformer는 NLP 분야에서 큰 성공을 거두었고 마침내 비전에서도 ViT를 적용하게 됩니다. DINO는 ViT를 사용한 대표적인 self supervised learning framework입니다. EMA(지수이동평균)를 사용하여 self distillation을 가능하게 합니다.
Self-Knowledge Distillation with Progressive Refinement of Targets (ICCV 2021) 당시 SOTA
https://arxiv.org/abs/2006.12000
Knoledge distillation을 처음으로 self supervised에 적용한 논문입니다.
hard target 즉 [1, 0, 0, 0]의 꼴을 soft , [0.8, 0.05, 0.05, 0.05]의 꼴로 만들어줍니다.
soft로 만들었을 때 모델이 더 일반화 되고 빠른 속도로 학습을 할 수 가 있습니다.
여기서는 student와 teacher가 모두 본인이 되는 방식입니다. t번째 epoch에서 t-1번째 epoch 모델의 출력값과 cross entropy loss를 구하는 방식입니다. Emerging Properties in Self-Supervised Vision Transformers a.k.a DINO
https://arxiv.org/pdf/2104.14294.pdf
SSL 방식 중 하나입니다. Teacher model은 backward를 하지 않고 student 모델의 업데이트를 EMA를 활용하여 업데이트 하는 방식으로 teacher 모델을 학습합니다.
이때 student는 모든 종류의 augment, 즉 global view와 local view를 모두 받지만 teacher 모델은 global view만을 input으로 받습니다.
(mean teacher (2017)과 유사합니다)
* collapse:
* centering: 모델 출력이 하나의 차원으로 집중되는 것을 예방
* sharpening: temperature로 나누어 input에 상관없이 uniform logit이 나오는 것을 예방
Method
Feature Correspondences Predict Class CO-Occurrence
기존에 연구들에서 한 개의 이미지에 대해 하나의 vector를 만들려고 했지만 많은 연구들을 통해 sementically relevant한 feature들이 많다는 것을 증명했습니다. 이를 활용하기 위해 correlation volume에 focus하였습니다. 서로 다른 이미지의 픽셀에 대해서 코사인 유사도를 구하는 방식으로 이를 구현합니다.(물론 같은 이미지를 비교하는 케이스도 존재) 이러한 방식이 generalization에 좋다는 것은 contrastive 및 visual search 연구에서 증명되었습니다.

왼쪽 이미지를 src로 가운데는 self query 오른쪽은 KNN을 활용한 것입니다.
GT label을 위해서 각 픽셀의 possible class를 구하고 이중 겹치는 것이 있으면 1 아니면 0으로 처리합니다.
average precision을 계산하는데 이는 efficacy of feature를 구할 수 있게 해줍니다. 그뿐 아니라 다른 포맷의 supervision과 비교할 수 있게 해줍니다. 본 논문에서는 fully connected Conditional Random Field와 비교합니다.
fully connected Conditional Random Field - https://shining-programmer.tistory.com/1
후처리의 일종으로 DeppLab에서 사용된 것으로 유명합니다. 전체적인 context에서 pixel간의 관계성을 포함하고자 도입되었습니다.
결국 최적의 Gibbs Distribution을 얻고자 하는 것입니다. (Gibbs Sampling ) 아래의 식처럼 일반적인 segmentation mask와 pixel관의 관계성을 모두 고려합니다. 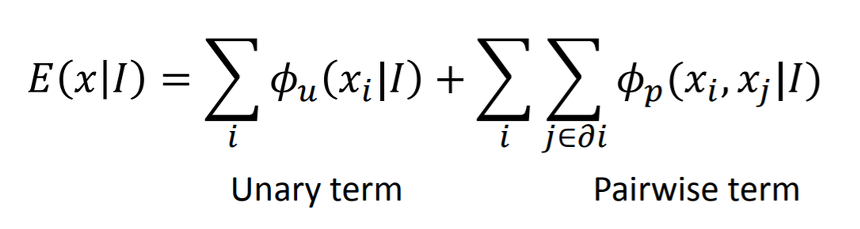
Distilling Feature Correspondences
이번 섹션에서는 cluster할때 semnatic segmentation을 pixel wise embedding으로 어떻게 만드는지를 다룹니다. feature correspondence를 distill한 low-dimensional embedding을 학습하기 위해서 앞에서 언급한 CRF에서 아이디어를 얻었습니다.
loss function의 경우 cosine similiarilty로 input feature f와 g의 correlation과 segmentation head를 통과한 s와 t의 correlation을 계산합니다. f와 g의 유사성이 높다면 s와 t의 correlation이 높아지기를 기대합니다.
여기서 b는 collapse를 막기 위한 negative pressure로 작용합니다. 다만 위 식에서 S와 F의 요소거 같아지도록 되는 것이 아니라 F-b의 부호에 따라 alignment 또는 anti-alignment로 가도록 하는 한계가 존재합니다. 이는 학습에 방해 요소가 되므로 weakly correlated segmentation feature를 orthogonal 하도록하는 새로운 방식을 제시합니다. small object에서는 수렴하지 못하고 발산하는 경우가 많아 Spatial Centering을 도입했습니다.
0 clamping은 여기서 부분이고 SC는 부분입니다.
STEGO Architecture
STEGO에서는 3가지 방식을 활용하는데 첫째는 자기자신 둘째는 KNN으로 구한 유사 이미지, 세번째는 Random image입니다. backbone의 경우에는 freeze합니다. 간단한 segmentation head를 학습시켜면 되기에 v100 gpu에서 2시간만에 학습을 완료합니다.
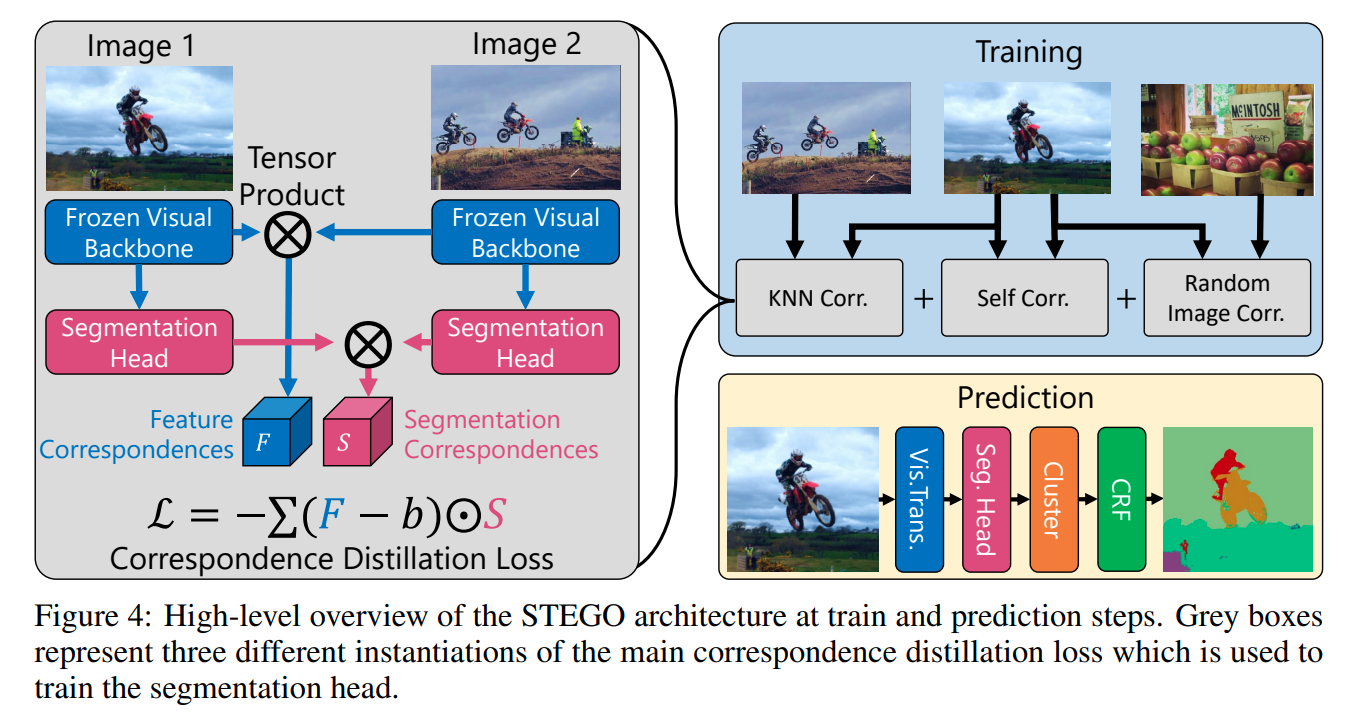
GAP와 backbone으로 (FC layer에 비해 spatial 정보를 덜 잃는 장점이 있다) feature를 뽑고 KNN으로 lookup table을 만들어줍니다. 은 top 7개의 sample을 사용합니다. 따라서 전체 loss는 아래와 같습니다.
의 경우 self와 rand가 knn의 2배 정도 되는 것이 성능이 좋았습니다. 거기에 더해 detail한 정보를 얻기 위해 five-cropping 방법을 사용합니다. minibatch K-Means algorithm으로 cosine distance를 계산하여 cluster를 뽑고 class를 assign 합니다. 그 후 CRF를 통해 label을 refine 합니다.
Relation to Potts Models and Energy based Graph optimization
위에서 본 correlation loss가 Potts model 또는 Ising model 처럼 보일 수 있습니다. 본 섹션에서는 위의 관계에 대해 설명합니다.
위의 식의 MLE를 구하는 과정은 전 섹션에서 본 loss 를 최적화하는 과정과 같습니다.
Experiments
mIoU를 지표로 사용하고 CocoStuff 데이터셋과 Cityspace dataset을 활용합니다.
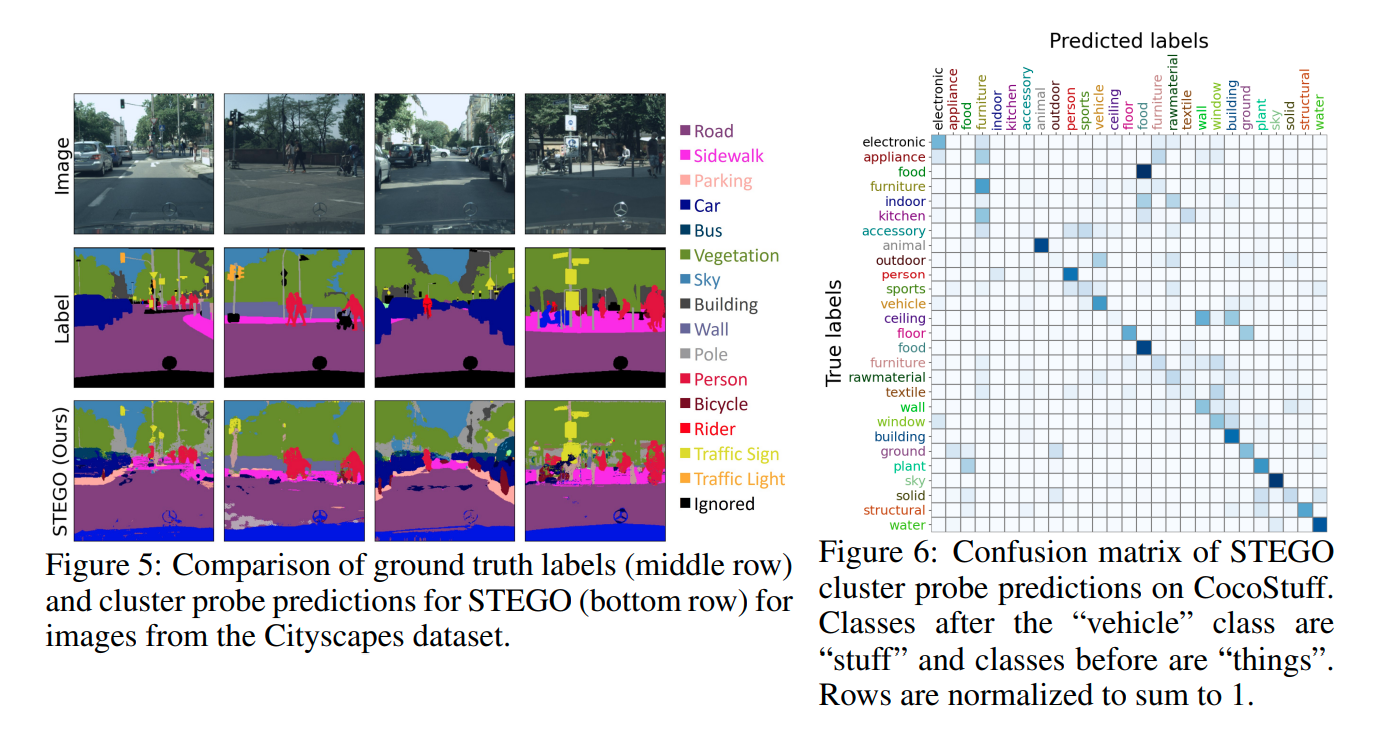
Linear Probe는 segmentation feature를 linear projection하여 평가하는 방식입니다.
Clustering은 supervised label 없이 Hungarian matching algorithm으로 unlabeled cluster를 gt label에 align하는 방식입니다.

결과는 위와 같이 매우 좋은 성능을 보입니다.
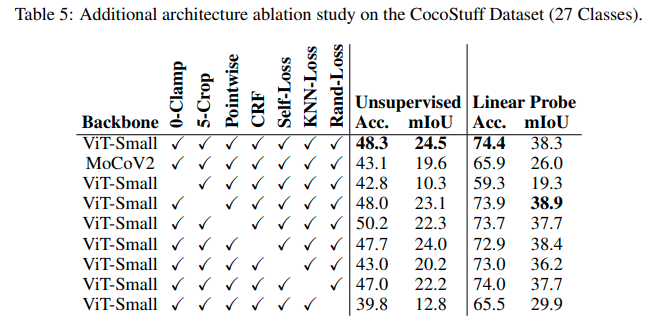
추가적인 ablation study는 위와 같습니다. 논문에서 제시한 방법론 들을 모두 적용하였을때 가장 성능이 좋은 것을 확인할 수 있습니다.


많은 도움이 되었습니다, 감사합니다.