[Paper Review] Grounding Language with Visual Affordances over Unstructured Data
Paper Review
https://arxiv.org/pdf/2210.01911.pdf
ICRA 2023
Abstract
최근 연구에서는 LLM을 robot task에 적용하는 것이 효과적임을 보여줘왔습니다. 본 연구에서는 self-supervised visuo-lingual affordance model을 통해 language conditioned robot skill을 학습합니다.
Introduction
LLM의 semantic knowledge를 robot planning 사용하려는 연구가 많이 진행되고 있습니다. 하지만 이런 것은 많은 양의 데이터와 사람의 개입을 필요로 하거나 간단하게 조성된 제한된 환경에서의 policy로만 가능합니다. 사람에게는 간단한 작업이지만 로봇에게는 어려운 것을 Moravec's paradox라고 합니다.
기존의 연구들은 manipulation을 semantic과 spatial로 나누었습니다. 이것에서 영감을 받아 본 논문은 general purpose language conditioned robot skill를 학습하는 방법을 제시합니다. offline과 reset free한 데이터를(reset free: 정해진 원점 회귀가 불필요) self supervised visuo lingual affordance model로 학습합니다. 단순히 데이터의 양을 늘리는 것이 아니라 계층적으로 semantic concept을 갖는 high level과 3d interaction knowledge를 갖는 low level로 처리합니다.
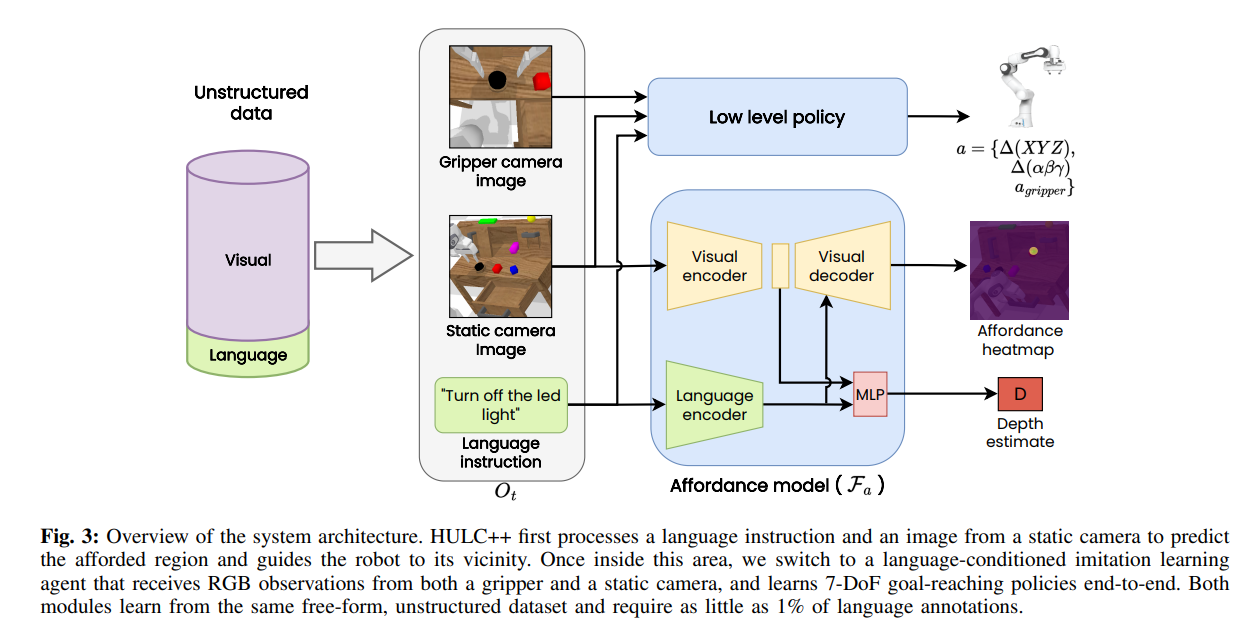
HULC++는 HULC의 제어와 VAPO의 object centric semantic understanding을 결합한 것입니다. VAPO가 self supervised visual affrordance로써 learning 속도를 높이고 generalization 성능도 올립니다. abstract한 자연어을 구체적인 일련의 instruction으로 바꾸는 방식으로 처리합니다.
Related Work
Method
먼저 해당 3d location을 구하고 model based planning으로 해당 위치로 이동합니다. local language conditioned으로 전환 후 learning based policy로 scene과 상호작용합니다. 그후 HULC++로 구체적인 subtask로 분해합니다.(model based: 이미 환경을 알고있는 전제; model free: 모르는 가정하에 상호작용으로 해결)
위의 식에서 알 수 있다시피 일정 pixel distance() 이내면 model free 방법을 이상이면 model based 방법을 사용하는 것을 알 수 있습니다. 타겟 근처에서는 local behavior만 학습하면 되기에 model free가 더 효과적으로 작용합니다.
Extracting Human Affordance from Unstructured Data
본 연구에서는 자연어 명령이 주어질 때 world 좌표를 예측할 수 있는 affordance model을 목표로합니다. 기존의 방식들이 직접 segmentation mask를 만들어줬어야 했으면 본 논문에서는 자동으로 affordance를 뽑을 수 있습니다. tele operated play data를 사용한 것에 장점이 있는데 싸고 쉽게 모을 수 있으며 general하고 random이 아닌(사람의 지식에서의 affordance가 반양된) 데이터를 얻을 수 있습니다.
특정 task를 수행함에 있어 end effector position에 필요한 object가 있다고 가정합니다. end effector의 world position을 camera image에 투사하여 해당 픽셀을 구하고 전 프레임에서의 픽셀과 language instruciton을 annotate합니다. 이를 통해 model이 해당 task를 수행하는데 필요한 픽셀을 예측할 수 있게 됩니다.
model based policy를 따라 해당 위치로 이동해야 하는 3d position을 알기 위해서는 depth 정보가 사용되지만 해당 모델에서는 esimated depth를 사용합니다. visuo lingual feature에서 depth를 예측함으로 occlusion 상황에서도 더 뛰어납니다.
Language Conditioned Visual Affordances
2가지 헤드로 구성되는데 하나는 각 픽셀에 대한 afforded point가 될 likelihood를 구하는 것이고 다른 하나는 depth 예측을 위한 가우시안 distribuition을 예측하는 것입니다. 같은 인코더를 사용합니다. 결과적으로 output은 pixel wise heatmap, depth estimate 입니다.
Visual module
모든 픽셀에 대해 softmax를 취해 distribuition V에 속하게 해 모든 합이 1이 되도록 합니다. target t와 v 사이에 cross entropy를 구해 계산합니다. affordance prediction에는 U-Net 구조가 사용됩니다.
Depth Module
가우시안 distribution으로 예측합니다.(occlusion 및 여러가지 에러로 depth 정보가 정확하지 않을 수 있기에)
Low-Level Language Conditioned Policy
multi context imitation learning으로 학습을 진행합니다. goal image나 language goal 로 학습하는 방식이 unlabeled data를 활용할 수 있기에 훨씬 용이합니다.
Decomposing Instructions with LLMs
기존 학습된 LLM을 사용하고 robot code로 prompting 했다는 내용입니다.
Experiments
Conclusion

많은 도움이 되었습니다, 감사합니다.