1) Title / Link / Read Date
- Title: Attention Is All You Need
- Authors / Venue / Year: Vaswani et al., NeurIPS 2017 (arXiv v7: 2023-08-02 표기)
- Link: https://arxiv.org/abs/1706.03762
- Read Date: 2026/02/06
2) 한 줄 요약 (Contribution in 1 sentence)
RNN/Conv 없이 “Self-Attention만”으로 인코더-디코더를 구성한 Transformer를 제안해, 번역에서 더 높은 성능과 더 빠른 병렬 학습을 달성했다.
3) Summary (핵심 내용 정리)
A. 문제 정의 (왜 RNN을 버렸나?)
- 기존 RNN 기반 시퀀스 모델은 시간축으로 순차 계산이 필수 → 학습 병렬화가 어렵고 긴 문장에서 비효율적.
- Attention은 거리와 상관없이 의존성 학습이 가능했지만, 대부분 RNN과 “같이” 쓰였음.
- Transformer는 아예 recurrence/conv를 제거하고 attention만으로 시퀀스 변환을 수행.
B. 모델 전체 구조 (그림으로 이해)
-
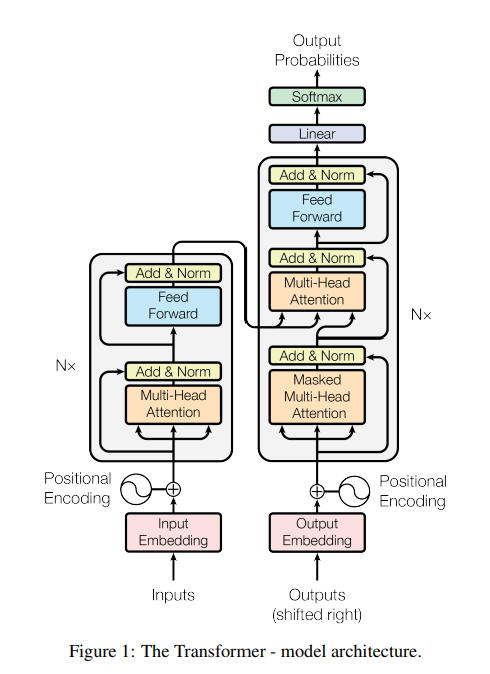
Figure 1 (p.3): Transformer 전체 아키텍처
- Encoder: (Self-Attention → FFN) 을 N=6층 쌓음
- Decoder: (Masked Self-Attention → Encoder-Decoder Attention → FFN) 을 N=6층 쌓음
- 각 서브레이어마다 Residual + LayerNorm:
LayerNorm(x + Sublayer(x)) - 디코더의 self-attention은 미래 토큰을 못 보게 mask(autoregressive 보장).
C. 핵심 아이디어 3개
- Scaled Dot-Product Attention (기본 attention)
- Multi-Head Attention (여러 표현공간을 병렬로 보게)
- Positional Encoding (RNN/Conv가 없으니 “순서 정보”를 주입)
4) Include formulas and images to aid understanding (수식 + 그림 포인트)
(1) Scaled Dot-Product Attention — Eq.(1)
논문 핵심 수식:
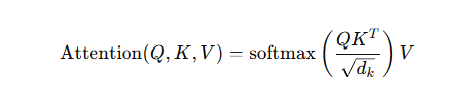
- Q(Query): “지금 내가 찾고 싶은 것”
- K(Key): “각 토큰이 가진 주소/특징”
- V(Value): “각 토큰이 가진 실제 내용 벡터”
- (\sqrt{d_k}) 로 나누는 이유: (d_k) 가 커지면 내적 값이 커져 softmax가 포화되고 gradient가 작아지는 문제를 완화.
- Figure 2 (p.4) 왼쪽이 이 과정을 그림으로 보여줌.
(2) Multi-Head Attention — “한 번에 여러 시선”
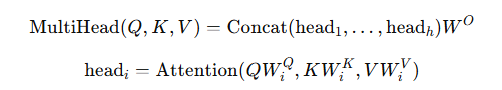
- 논문 설정(베이스): h=8, (d_\text{model}=512), 그래서 각 head는 (d_k=d_v=64).
- 의미: “문법 관계”, “장거리 의존성”, “대명사 지시(anaphora)” 같은 패턴을 서로 다른 head가 분담해서 배운다.
- Figure 2 (p.4) 오른쪽이 Multi-Head를 시각화.
(3) Position-wise Feed-Forward Network — Eq.(2)
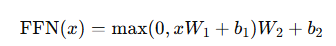
- 각 토큰 위치에 독립적으로 동일한 FFN 적용(= 커널 1짜리 conv 2번과 유사).
- 베이스 설정: (d\text{model}=512), (d{ff}=2048).
(4) Positional Encoding (사인/코사인) — 순서 정보 주입
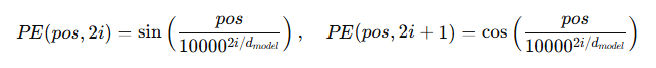
- Figure 1 (p.3) 에서 임베딩에 positional encoding을 더하는 흐름이 나옴.
- 장점: 학습 길이보다 더 긴 시퀀스에도 외삽 가능할 수 있다고 설명.
(5) Learning rate schedule — Eq.(3) (워밍업 핵심)
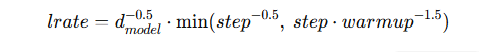
- 초기 warmup_steps=4000 동안 선형 증가, 이후 (1분의 루트 step)로 감소.
(6) “그림으로 이해” 포인트 (논문 내 시각자료)
- Figure 1 (p.3): Encoder/Decoder 블록 구조(모델 전체 지도)
- Figure 2 (p.4): Scaled Dot-Product / Multi-Head Attention 메커니즘
- Figure 3~5 (p.13~15): attention head들이 장거리 의존성, 대명사 지시 등 서로 다른 역할을 학습하는 시각화
5) Results (숫자 중심으로 꼭 남길 것)
- WMT14 En→De: 28.4 BLEU (Transformer big), 기존 최고 대비 +2 BLEU 이상 향상
- WMT14 En→Fr: 41.8 BLEU (big), 단일 모델 SOTA 주장
- 학습 비용/시간: big 모델이 8×P100에서 3.5일, base는 12시간(100k steps)로 보고
6) English vocabulary learned (단어/표현 + 뜻 + 예문)
아래는 이 논문에서 “자주 나오고, 연구 글에서 재사용되는” 표현 위주로 정리했어.
- sequence transduction
- 뜻: 시퀀스 → 시퀀스로 변환(번역/요약 등)
- 예문: The Transformer is a model for sequence transduction tasks.
- 해석: Transformer는 시퀀스 변환 작업을 위한 모델이다.
- eschew / dispensing with
- 뜻: (특히 일부러) 피하다 / 없애다
- 예문: The Transformer dispenses with recurrence and convolutions entirely.
- 해석: Transformer는 recurrence와 convolution을 완전히 제거한다.
- recurrence
- 뜻: 순환 구조(RNN처럼 이전 상태를 다음으로 전달)
- 예문: Without recurrence, the model becomes highly parallelizable.
- 해석: recurrence가 없으면 모델은 병렬화가 쉬워진다.
- parallelizable / preclude
- 뜻: 병렬화 가능한 / ~를 불가능하게 하다(막다)
- 예문: Sequential computation precludes parallelization within training examples.
- 해석: 순차 계산은 한 샘플 내부 병렬화를 막는다.
- compatibility function
- 뜻: query와 key가 “얼마나 잘 맞는지” 점수화하는 함수
- 예문: Weights are computed by a compatibility function of the query with the key.
- 해석: 가중치는 query와 key의 적합도 함수로 계산된다.
- scaled dot-product
- 뜻: 스케일링된 내적(softmax 포화 방지 목적)
- 예문: We divide by (\sqrt{d_k}) to counteract small gradients.
- 해석: 작은 그래디언트 문제를 줄이기 위해 (\sqrt{d_k})로 나눈다.
- masking / illegal connections
- 뜻: 마스킹 / 허용되지 않는 연결
- 예문: We mask out values corresponding to illegal connections.
- 해석: 불법 연결에 해당하는 값들은 마스킹한다.
- auto-regressive
- 뜻: 자기회귀(이전 출력만 보고 다음 출력 생성)
- 예문: The decoder is auto-regressive and uses shifted-right outputs.
- 해석: 디코더는 자기회귀이며 출력 시퀀스를 한 칸 밀어 사용한다.
- positional encoding / extrapolate
- 뜻: 위치 인코딩 / 학습 범위를 넘어 일반화(외삽)
- 예문: Sinusoidal encodings may allow extrapolation to longer sequences.
- 해석: 사인/코사인 인코딩은 더 긴 시퀀스로 외삽을 가능하게 할 수 있다.
- ablation (study) (논문 표/실험 읽을 때 필수 단어)
- 뜻: 구성요소를 빼서 효과를 검증하는 실험
- 예문: Model variations indicate which components matter most.
- 해석: 모델 변형 실험은 어떤 구성요소가 중요한지 보여준다.
7) 내가 체크할 “개념-문장” (헷갈리기 쉬운 핵심 문장 3개)
- “Self-attention reduces path length to O(1)”가 왜 중요한가?
- 해석 포인트: 멀리 떨어진 토큰 관계를 학습할 때, 정보(gradient)가 여러 층/시간을 거치는 “긴 경로”가 필요하면 어려워짐. Self-attention은 한 번에 전 위치를 볼 수 있어서 경로가 짧아진다.
- “Masking ensures position i depends only on < i”
- 해석 포인트: 번역/생성에서는 미래 단어를 보면 “치팅”이 되므로, 디코더 self-attention에서 미래를 가려야 함.
- “Scaling by √dk prevents extremely small gradients”
- 해석 포인트: 내적 값이 커지면 softmax가 포화 → gradient가 거의 0 → 학습이 안 됨 → 스케일링으로 완화.
원하면 다음 단계로, 너가 이해한 걸 기준으로 (1) Q/K/V를 2토큰 예제로 직접 숫자 계산하면서 Attention이 어떻게 나오는지, 그리고 (2) Multi-head가 왜 ‘평균내서 뭉개는 문제’를 줄이는지까지 “손계산 느낌”으로 같이 해볼 수 있어.
마지막은 너 스스로 논문 읽고 모르는 문장이나 단어를 같이 공부하는거지 그래서 미자막에 이제 잘 이해하고 논문읽고 단어 문장 공부하자 이렇게 말 해줘

Like it, and it will be the best.