작성 이유 : transfomer 모델을 설명해주기 위해서 작성하는 과정에서 attention 부분이 3가지정도 있었는데 encoder - decoder attention / multi-head-self-attention /masked multi-head-attention 이있었고 그 부분에서 화살표로 잔차학습이 존재해서 설명하려는 도중에 막혀서 작성하게 되었음
- why 이것을 사용했는가??
1) 문제점
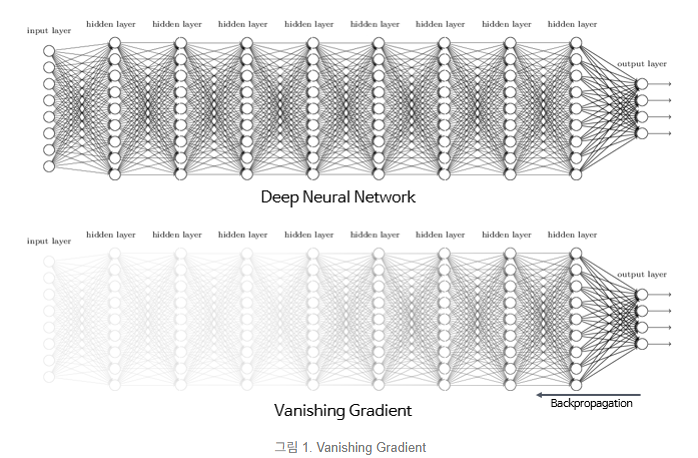
과거의 문제점 층을 깊에 쌓을 수록 gradiant vinishing problem(미분을 하면서 미분값이 0으로 가서 결국 더 이상 네트워크가 업데이트 되지 않는 현상)이 존재
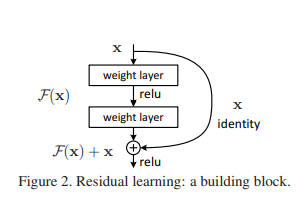
Residual block의 수식 (가장 기본형)
-
우리가 원래 원하던 함수: H(X)
-
ResNet은 이를 직접 학습하지 않고, 잔차(residual), F(x)= H(x)−x 를 학습하게 변경
-
y = x = F(x)
-
즉 이렇게 되면 “아무것도 안 하는(identity)” 해답이 필요할 때, F(x)=0만 만들면 되니까 최적화가 훨씬 쉬워진다는 게 핵심 주장입니다

2) 왜 skip connection이 학습을 쉽게 하나? (직관)




(1) “쉬운 길”이 생겨서 그라디언트가 덜 죽는다
(2) “필요한 변화만 추가로 학습”하게 만든다
질문 : 필요있고 없고는 역전파할때를 말하는 건지 순전파를 말하는 건지??
- 실제로는 순전파/역전파 둘 다에서 의미가 있어.



3) 통과 경로”가 생겨서 학습이 쉬워진다 보충 설명



부족한 개념 : 역전파 직접해보면서 0이되는지에 대한 부분을 이해가 필요할 듯 + 곱하기로
미분값이 적용되는지도 해볼 필요 있음
4-1) 2 layer (Sigmoid)






4-2) 2 layer ResNet (Sigmoid)






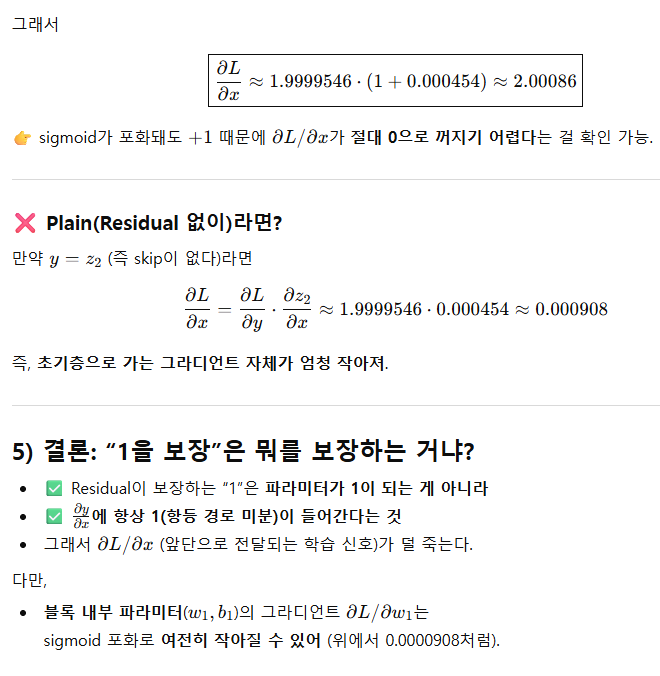

4-3) 2 layer ResNet (RELU)
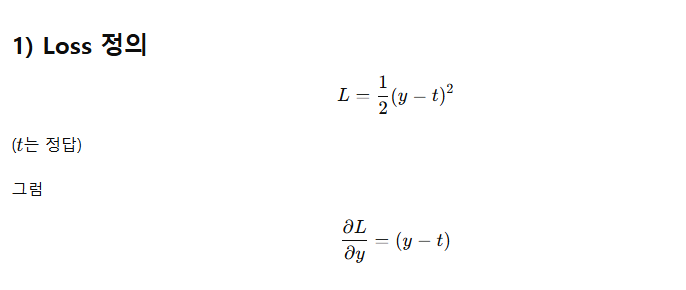







Like it, and it will be the best.