딥러닝을 이용한 컴퓨터비전 수업 2주차다. 이번주부터 GAN이라는 것을 배우기 시작할 것이다.
Generative Adversary Networks의 준말인데, 간단하게는 원래는 존재하지 않지만 그럴싸해보이는 이미지를 생성하는 기술이다.
이런 기술이 어떻게 가능한지 알기 위해서는 확률 분포에 대한 개념을 정리하는 것이 중요하다. 확룰 분포는 확률 변수가 어떤 값을 가질 확률을 나타내는 함수를 의미한다.
- 이산 확률 분포: 확률변수 X의 개수를 정확히 셀 수 있는 확률분포. 예를 들어 주사위의 각 눈은 1부터 6까지 나올 확률이 모두 1/6으로 정확히 떨어질 수 있다.
- 연속 확률 분포: 확률변수 X의 개수를 정확히 셀 수 없는 확률분포. 확률 밀도 함수를 이용해 분포를 표현할 수 있다. 키, 달리기 성적 등 연속적인 값이 해당한다.
이미지 데이터 또한 연속 확률 분포를 이용하여 표현할 수 있다. 벡터나 행렬의 형태로 컴퓨터에 저장되기 때문이다. 이미지는 다차원의 한 픽셀 점으로 표현될 수 있고, 특히 사람 얼굴의 경우 얼굴, 코, 눈의 길이 등의 특징들이 통계적인 평균치로 표현될 수 있다.
-
Generative model (생성 모델)
실제로 존재하지는 않지만, 있을 법한 이미지를 생성하는 모델. 원래 데이터에 거의 근접해질 수 있도록 학습하며, 원래 이미지의 분포를 잘 모델링 할 수 있고, 편균적인 특징을 가진 데이터를 쉽게 생성할 수 있다면 좋은 모델이라는 뜻이다.
이번 시간에 다루게 될 GAN이 대표적인 예이다. GAN 이후로도 다양한 논문이 나왔으며, 화질과 성능이 더 좋아졌지만, 이번 시간에는 GAN에 집중하려 한다.

-
GAN
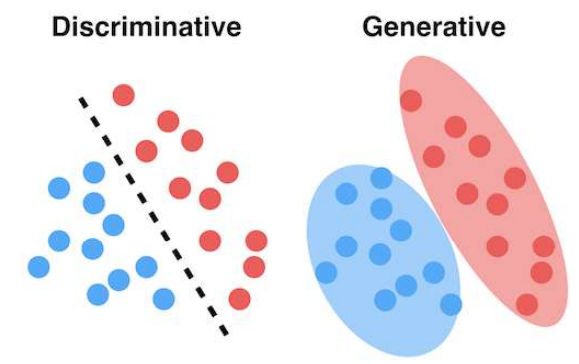
GAN은 Generative Adversary Network의 준 말인데, 'adversary'는 '적대적인'이라는 뜻이다. '적대적인 네트워크'라고 부르는 이유는 생성자(generator)와 판별자(discriminator) 이 두 네트워크를 학습하는 생성 모델이기 때문이다. 학습이 끝난 이후에 사용하는 모델이 생성자이며, 판별자는 가짜 데이터를 구분하여 생성자의 학습을 돕는 네트워크다.
 x: 원본 데이터, z: 노이즈 데이터
x: 원본 데이터, z: 노이즈 데이터
함수는 V로 표현되는데, 함수 D, G로 이뤄져있다. G는 함수 V의 값을 낮추고, D는 값을 높이는 역할을 맡는다. 이 함수의 p함수는 데이터의 분포를 나타내는 함수다. x~pdata(x)는 원본 데이터 x중 하나를 꺼내서 샘플링한다는 의미다.
전체 함수를 살펴보자면 두 식의 덧셈 형태로 이뤄져있다. 우선 D(x) 함수가 있는 왼쪽식을 먼저보자면, 판별자 함수에 x데이터를 입력한 값에 로그를 취한 값의 기대값, 즉, 평균값을 얻는것이다. 오른쪽 식은 생성자의 개념이 추가된 식이고, 노이즈 벡터를 받아서 새로운 이미지를 만든다. 노이즈 데이터를 샘플링 한 뒤, 그 값을 생성자 함수 G에 넣어 가짜 이미지를 만들고나서 판별자 함수 D에 입력해서 얻은 값을 1에서 빼서 평균값을 얻는 방식이다. 아무래도 가짜 이미지가 들어오면 가짜라고 판별하겠지만, 1에서 빼는 방식으로 나머지 값을 얻게되어 진짜라고 인식하도록 만드는 것이다.
위의 식이 E[X]의 형태로 표현되었는데, 무슨 식인지 이해할 수 없을 수 있기에 기대값이라는 용어의 정의를 짚고 가자.
기대값은 모든 사건에 대해 확률을 곱하면서 더해서 계산한다.
연속확률변수의 경우 다음과 같이 표현할 수 있다.

여기서 X는 확률변수를 의미하고, x는 사건을 의미한다.
최종적으로 다음과 같이 생성 모델의 분포가 원본 데이터의 분포로 수렴하도록 하는 것이 목표다.

