2022 국민대학교 겨울 인공지능 특강
1.[2022 국민대학교 겨울 인공지능 특강] 1주차 1일 학습 내용

Git란 분산 버전 관리 시스템인데, 여러명이서 코드 관리를 더 용이하게 하는 동시에 해당 코드의 버전 관리도 챙기기 위한 것입니다. 저장소(repository) 단위로 관리되며, 개발자들은 로컬 저장소에서 git으로 관리하고, 이 로컬 저장소들이 github라는 원격
2.[2022 국민대학교 겨울 인공지능 특강] 1주차 2일 학습 내용
Numpy 모듈에 대해 배웠다. 웨이센 인턴과 다학제간캡스톤디자인II 수업 프로젝트와 과제로 파이썬을 다루면서 사용해본 경험이 있어 많이 익숙한 분야였다.리스트가 있는데 굳이 numpy를 이용해서 배열(array)로 변환하려는 이유는 데이터 조회를 더 빠르게 하기 위해
3.[2022 국민대학교 겨울 인공지능 특강] 1주차 3일 학습 내용
오늘 배운것은 pandas라는 모듈에 관한 것이었다. Numpy와의 차이점은 pandas는 데이터를 table 형태로 정리해서 관리할 때, 즉, 행과 열을 이용하여 저장하고 관리하기 위한 자료구조라고 한다. 여기서 행은 개체, 열은 속성에 속한다. 우선, 1차원 데이
4.[2022 국민대학교 겨울 인공지능 특강] 1주차 5일 학습 내용
오늘 배운 라이브러리는 Matplotlibrary라는 것이다. Matplotlib라고 표기한다. 파이썬 코딩에서 불러올 때는 import matplotlib.pyplot as plt를 입력한다. Matplotlib의 하위 모듈 중 가장 많이 사용되는 모듈이 pyplot
5.[2022 국민대학교 겨울 인공지능 특강] 2주차 1일 학습 내용
오늘 배운 것은 Flask에 관한것이었다. Rest API란 것을 구축하기 위한것이라 하는데, 나는 아직은 모르는 용어이다. 그리고 Django라는 것이 무엇인지도 잠시 언급이 되었는데, 웹사이트를 구축하는데에 사용하는 것이라 한다.Flask란 파이썬 기반의 마이크로
6.[2022 국민대학교 겨울 인공지능 특강] 2주차 2일 학습 내용
REST API의 정의에 대해서는 이번 수업에 배웠다. 우선 API는 Application Programming Interface의 줄임말이며, 프로그램들이 서로 상호작용할 수 있도록 해주는 매개체이다. 사용자가 어떤 정보가 필요할 경우 그 정보를 제공하는 자원에 명령
7.[2022 국민대학교 겨울 인공지능 특강] 2주차 4일 학습 내용
EDA란 Exploratory Data Analysis의 준말인데, 탐색적 데이터라는 뜻이다. 데이터 그 자체를 확인함으로써 인사이트를 얻고 유의미한 정보를 알아내는 접근법이다.EDA의 과정은 다음과 같다.첫 번째로 특정 데이터를 분석하려는 목적이 있어야 하는데, 이것
8.[2022 국민대학교 겨울 인공지능 특강] 3주차 1일 학습 내용
이번 3주차 부터는 numpy 모듈을 다루는 여러 실습을 한다.파이썬에서 numpy를 불러올 때 import numpy as np 코드를 작성한다.리스트를 배열로 변환할 경우 사용하는 모듈이기도 하다. np.array()를 이용하며, 괄호안에 리스트를 입력하는 방식이다
9.[2022 국민대학교 겨울 인공지능 특강] 3주차 2일 학습 내용
2일차에는 연습문제 2가지가 주어졌다.1) Numpy를 사용하여 (y1, x1)에서 (y2, x2)까지 구간에 해당하는 모든 요소의 값에 2를 곱하여 반환하는 함수 구현하기y2는 y1이상, 그리고 x2는 x1 이상의 정수값이다.우선 리스트는 다음과 같이 주어진다.arr
10.[2022 국민대학교 겨울 인공지능 특강] 3주차 3일 학습 내용
Numpy를 이용한 롤러코스터 문제다. 탑승객들의 다음과 같은 신체조건을 기반으로 제한을 두려고 한다.키는 150cm이상, 195cm 이하, 그리고 몸무게는 140kg 미만이어야 한다.하지만 위의 조건을 제대로 읽지 않고 탑승한 사람들이 많아 탑승 불가능한 사람들을 구
11.[2022 국민대학교 겨울 인공지능 특강] 3주차 4일 학습 내용
이번 수업의 문제는 행렬 곱 문제다.arr_list = \[\[-9, -14], \[14, -2, 0, -14, -5, 1, -11, 3, -6], \[-2, -6, 18, 0]]위 배열에 담겨있는 배열들을 하나하나씩 읽어내야하는데, 서로 크기가 다르다.그리고 각 배열
12.[2022 국민대학교 겨울 인공지능 특강] 3주차 5일 학습 내용
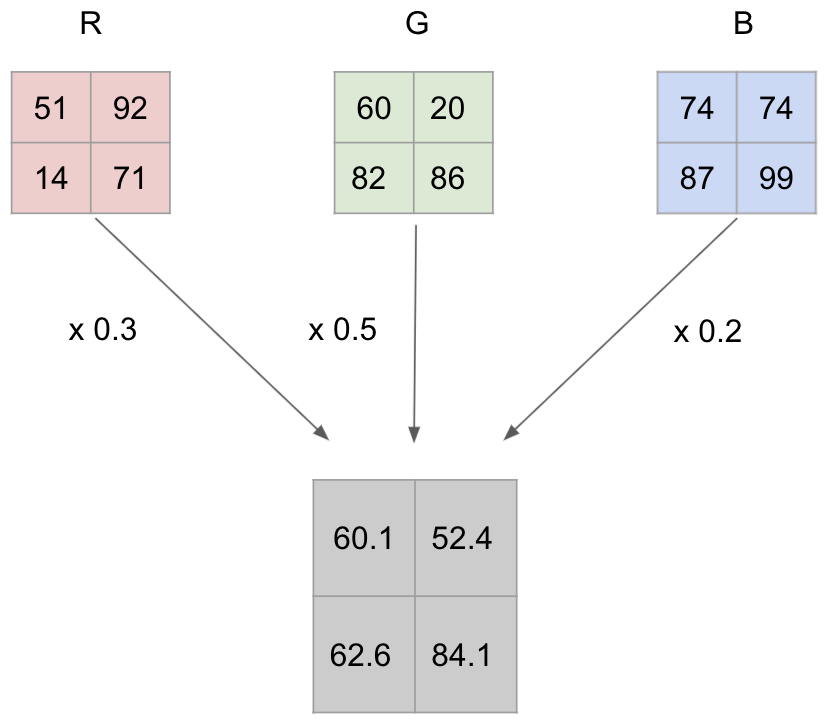
이번 5일차 문제는 이미지 변환 문제다.컴퓨터에서 이미지는 픽셀이라는 작은 점 단위로 구성되어 높이와 너비의 길이만큼 2차원 배열의 형태를, 즉, 행렬을 구성한다.이미지가 흑백일때는 각 픽셀은 하나의 수로 이뤄질 수 있지만, 색상일때는 픽셀이 빨강(R), 초록(G),
13.[2022 국민대학교 겨울 인공지능 특강] 4주차 1일 학습 내용
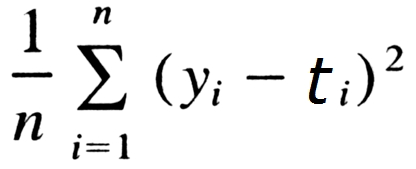
이번 주 부터 본격적으로 딥러닝 코딩을 다루게 된다. 우선 머신러닝 및 딥러닝에서 흔히 쓰이는 선형회귀를 코드로 구현하는 방법을 배웠다. 하지만 딥러닝 코딩을 할 때 쓰는 PyTorch 모듈을 사용하기 전에 선형 회귀의 원리를 이해하기 위해 PyTorch 모듈을 사용하
14.[2022 국민대학교 겨울 인공지능 특강] 4주차 2일 학습 내용
어제는 딥러닝 모듈인 PyTorch를 사용하지 않고 선형회귀(Linear regression)식을 직접 구현하여 예측값을 얻었지만, 이번엔 본격적으로 PyTorch를 이용해 구현했다.X = 1, 2, 3, 4, 5, 6, 7Y = 25000, 55000, 75000,
15.[2022 국민대학교 겨울 인공지능 특강] 4주차 3일 학습 내용

이번 시간에는 PyTorch를 이용해서 MNIST를 다뤘다. MNIST란 기본적인 딥러닝 학습 데이터셋(dataset)인데, 1부터 9까지 다양한 글씨체로 적힌 숫자를 학습해서 숫자들을 학습해서 판별한다. 손글씨 분류 딥러닝 학습 모델이다. 여기서 사용할 몇가지 Py
16.[2022 국민대학교 겨울 인공지능 특강] 4주차 4일 학습 내용
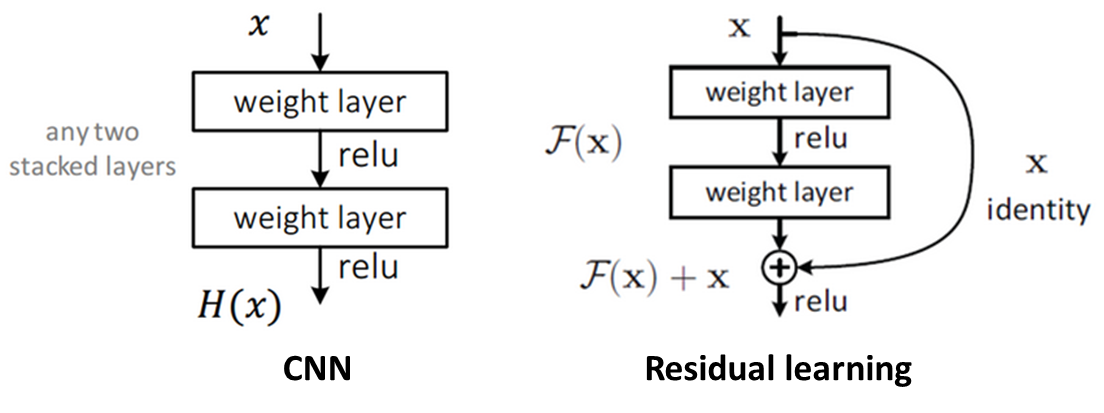
이번 시간엔 CIFAR10이라는 이미지 분류 데이터셋을 다뤘다. airplane, automobile, bird, car, deer, dog, frog, horse, ship, truck 이 10개의 클래스로 분류되는 32x32 크기의 60,000개의 이미지 데이터로
17.[2022 국민대학교 겨울 인공지능 특강] 4주차 5일 학습 내용
Image crawling딥러닝 모델을 훈련시키려면 데이터가 많이 필요하다. 인터넷에서 특정 이미지를 1만개 이상 다운받기에는 시간이 너무 오래걸리고, 그렇다고 컴퓨터에 저장된 이미지 데이터를 회전하거나 반전하는 등으로 변형을 해서 데이터 증식(data augmenta
18.[2022 국민대학교 겨울 인공지능 특강] 6주차 1일 학습 내용
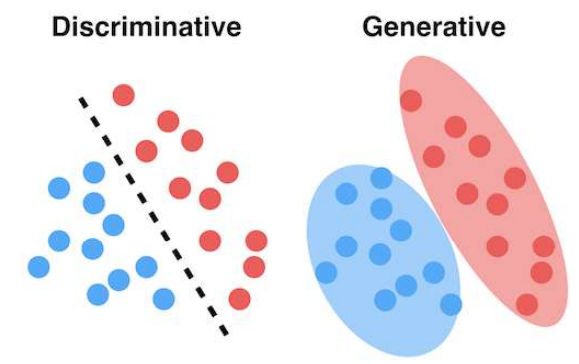
딥러닝을 이용한 컴퓨터비전 수업 2주차다. 이번주부터 GAN이라는 것을 배우기 시작할 것이다. Generative Adversary Networks의 준말인데, 간단하게는 원래는 존재하지 않지만 그럴싸해보이는 이미지를 생성하는 기술이다. 이런 기술이 어떻게 가능한지
19.[2022 국민대학교 겨울 인공지능 특강] 6주차 2일 학습 내용
이번 시간에 배울 모델은 Pix2Pix다. GAN을 기반을 설계된 모델이다. Image-to-image translation 방식인데, 한 이미지를 그 특성을 토대로 다른 형태의 이미지로 출력할 수 있는 방식이다. 예를 들어 이미지가 레이블 형태로 주어진 이미지를 실제
20.[2022 국민대학교 겨울 인공지능 특강] 6주차 3일 학습 내용
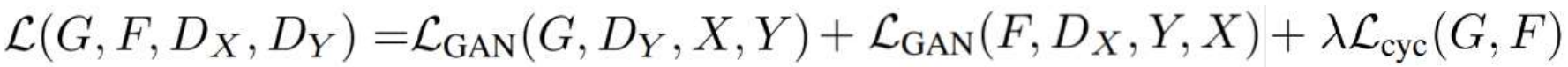
이번 시간에 배울 컴퓨터 비전 모델은 CycleGAN이라는 것이다. CycleGAN은 쌍을 이루지 않은(unpaired) 이미지 데이터셋으로 학습 가능한 이미지에 이미지 사이의 이동(image-to-image translation) 방식을 제안한다. 한 쌍으로 묶이지