Storage Access
Block은 storage allocation과 data transfer의 단위
DB 시스템은 disk와 memory간의 block transfer를 최소화한다.
main memory에 block을 최대한 많이 올려서 disk access를 줄일 수 있다.
Buffer: disk block의 copy를 저장할 수 있는 main memory의 부분
Buffer Manager: main memory의 buffer 공간을 할당하는 subsystem
Buffer Manager
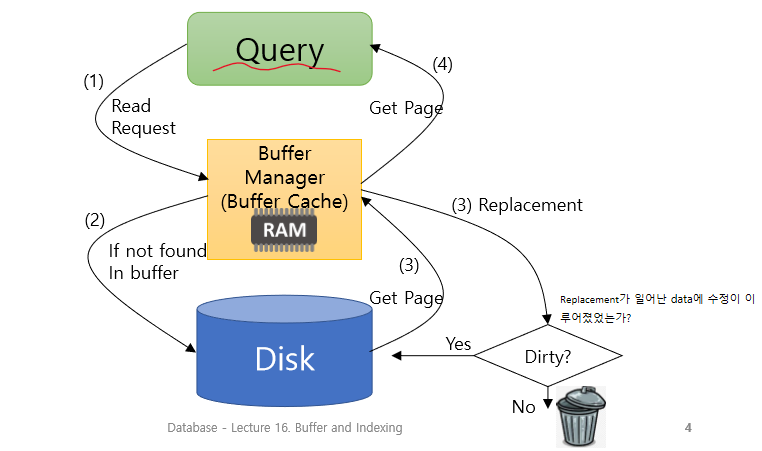
program은 disk에서 block read가 필요할 때, buffer manager를 호출
- 이미 해당 block이 buffer에 있으면, buffer manager는 main memory상의 해당 block의 address return
- 없으면 buffer 공간 할당 (안쓰는 block이나 수정돼서 disk에 written back된 block을 replace) -> disk에서 block을 read해 buffer 공간에 올리고 해당 address return
READ
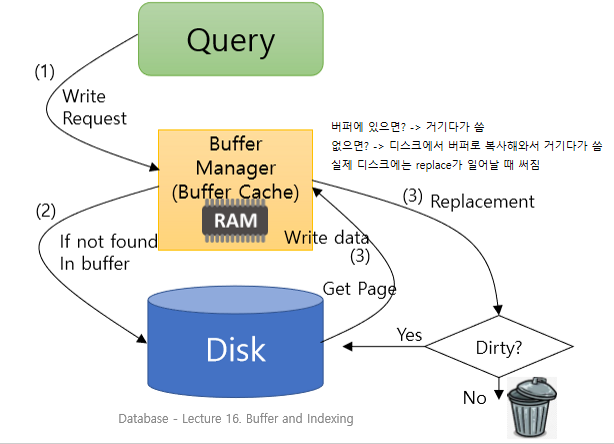
WRITE
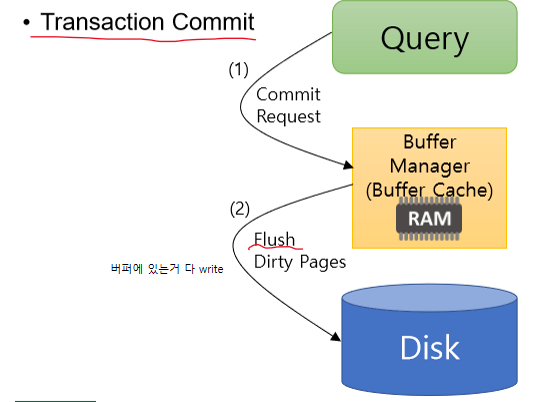
TRANSACTION COMMIT
Buffer replacement strategy
- Pinned block: disk write를 허용하지 않는 block
-- Pin: block에서 data를 R/W하기 전에 pin 함
-- Unpin: block에서 data의 R/W가 완료되면 unpin 함
-- pin/unpin 연산은 여러번 가능 pin = 0일때만 해당 block flush 가능 - Shared and exclusive locks on buffer
-- concurrent한 operation간의 conflict를 방지하기 위함
-- Reader는 shared lock이 필요
-- writer는 exclusive lock이 필요
Locking rules
한번에 한 process만 exclusive lock 획득 가능
shared lock과 exclusive lock은 동시에 있을 수 없음
shared lock은 여러 process가 동시에 가질 수 있음
Buffer replacement policies
대부분의 OS는 LRU(Least Recently Used)전략을 사용 -> 하지만 DB query에는 좋지 않음
Toss-immediate strategy: process가 끝나자마자 사용한 block 방출
MRU(Most Recently Used) strategy: block이 process된 뒤 해당 block은 replace될 후보가 됨
Indexing
Indexing은 data의 access 속도를 높이기 위해 사용됨
Search key - record를 찾는데 사용되는 attribute의 set
Index file 각 record의 search key - pointer로 구성됨
index는 보통 원래 table보다 훨씬 작음
Index의 두 가지 기본적인 종류
- Ordered indices: key가 정렬되어 저장됨
- Hash indices: hash function을 이용하여 bucket에 search key를 uniform하게 분배됨
Index evaluation metrics
- Access types (Point query, Range query)
- Access time
- Insertion time
- Deletion time
- Space overhead
Ordered Indices
search key value를 기준으로 정렬하여 저장
Clustered Index(primary index): index에서의 key의 순서 = file에서의 순서
Secondary Index(nonclustered index): file에서의 순서와 index에서의 key의 순서가 다름

index record는 실제 record의 pointer를 가지고 있는 bucket의 pointer를 가지고 있음
secondary index는 dense해야 함
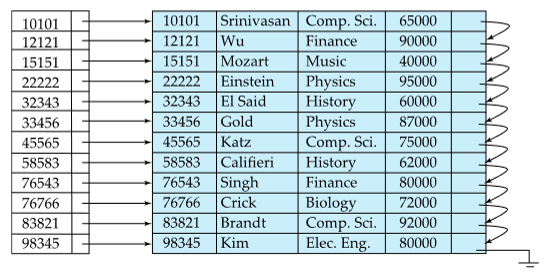
Dense Index File
모든 search key value에 대한 index record가 있음
Ex) instructor relation의 ID에 관한 index
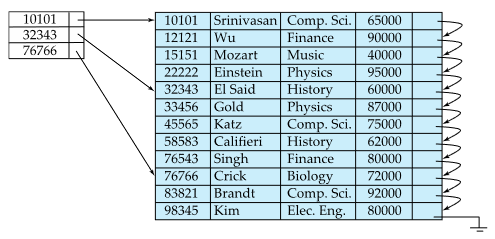
Sparse Index File
일부 search key에 대한 index만 가지고 있음
record가 search key를 기준으로 정렬되었을 때만 가능
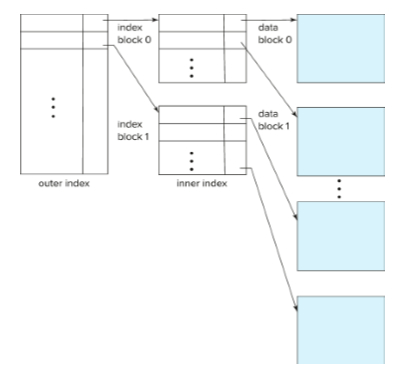
Multilevel Index
record가 매우 많아 index file의 크기가 memory 크기보다 커지는 경우 이를 해결하기 위해 사용
실제 데이터를 가리키는 inner index file들과
그 inner index file들을 가리키는 outer index file을 만들어 운영